
作者:Phosphen
编译;Gans 甘斯,Bagel预测市场观察
这个男人收集了过去43年所有职业网球比赛的数据,全部输入一个机器学习模型,然后只问了一个问题:你能预测谁会赢吗?
模型只回答了一个字:能。
随后,它在今年的澳大利亚网球公开赛上,正确预测了116场比赛中的99场,准确率高达85%!
这是模型训练中从未见过的赛事,它竟然连最终冠军赢得的每一场比赛都预测对了。

这一切只用了一台笔记本电脑、免费的数据和开源的代码,出自 @theGreenCoding 之手。
接下来,我将完整拆解这个点石成金的项目,从原始数据到最终预测成功。这将是你见过的最令人印象深刻的AI + 预测成功案例。
起点:一个文件夹里的43年网球数据
故事要从一份堪称「体育数据圣杯」的资料集说起。
这份资料集涵盖了1985年至2024年,ATP(男子职业网球联合会)的每一场职业赛事记录。
破发点、双误、正手、反手、球员身高、年龄、排名、历史交手记录、比赛场地……ATP有史以来追踪过的每一项逐分统计数据,应有尽有。
四十年的CSV文件,全部装在一个文件夹里。
当他打开完整数据集时,电脑直接崩溃了。
但他没有放弃。针对数据集中的95,491场比赛,他额外计算了大量衍生特征:
两位球员的历史交手记录
年龄差、身高差
最近10场、25场、50场、100场比赛的胜率
一发得分率差值
破发点挽救率差值
一套从国际象棋借鉴的自定义ELO评分系统(关键点)
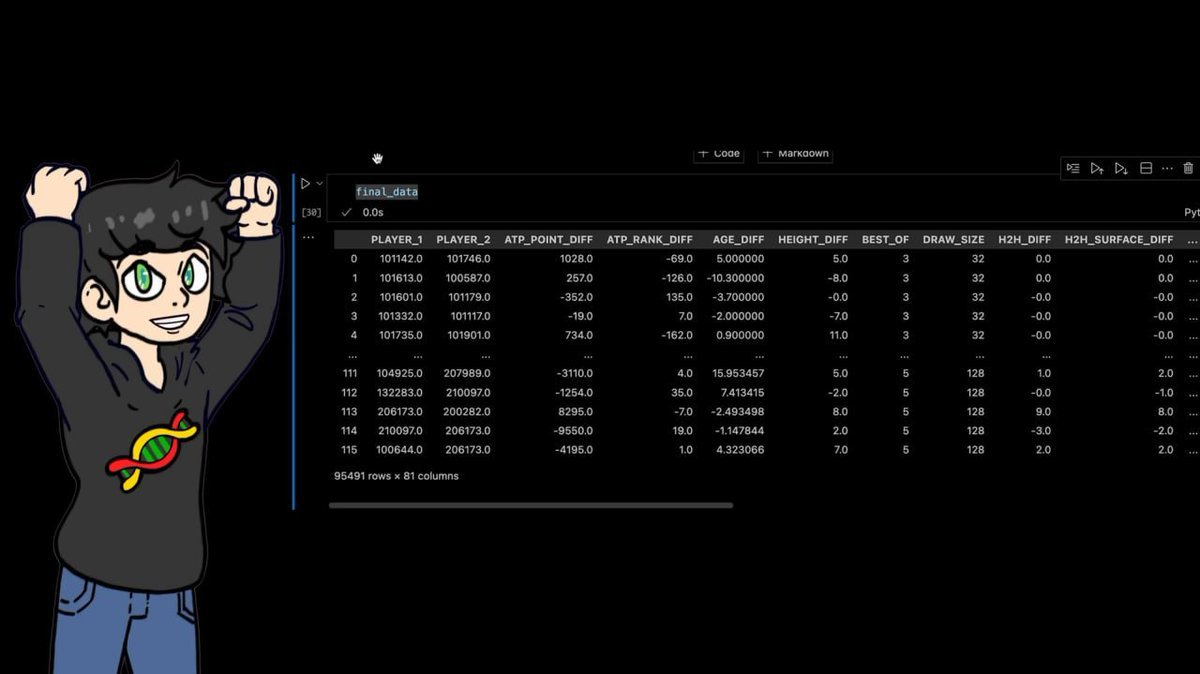
最终数据集:95,491行 × 81列。
过去四十年的每一场职业网球赛事,配上数十个手工计算的特征。
第二步:从泰坦尼克号借鉴的算法

在将数据输入分类器之前,他决定先彻底理解算法的运作原理。为此,他用 numpy 从零手写了一个决策树。
决策树的工作方式类似推理游戏——通过一系列问题逐步逼近答案。
为了说明这个概念,他选了一个完全不同的数据集:泰坦尼克号。
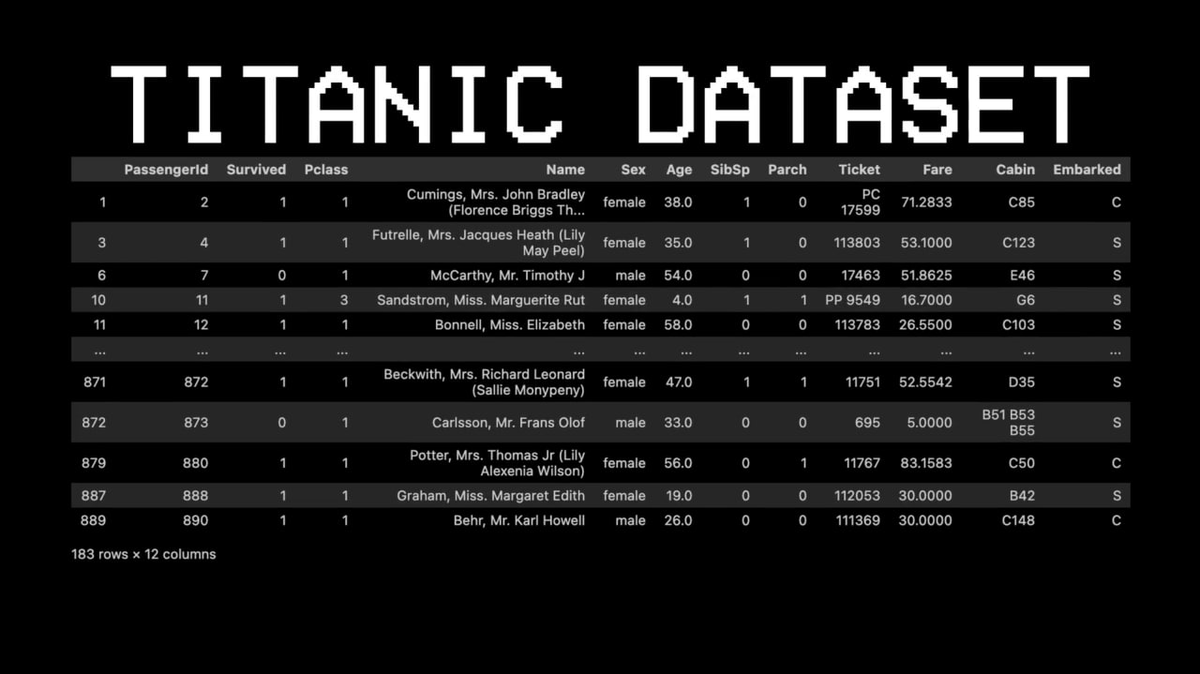
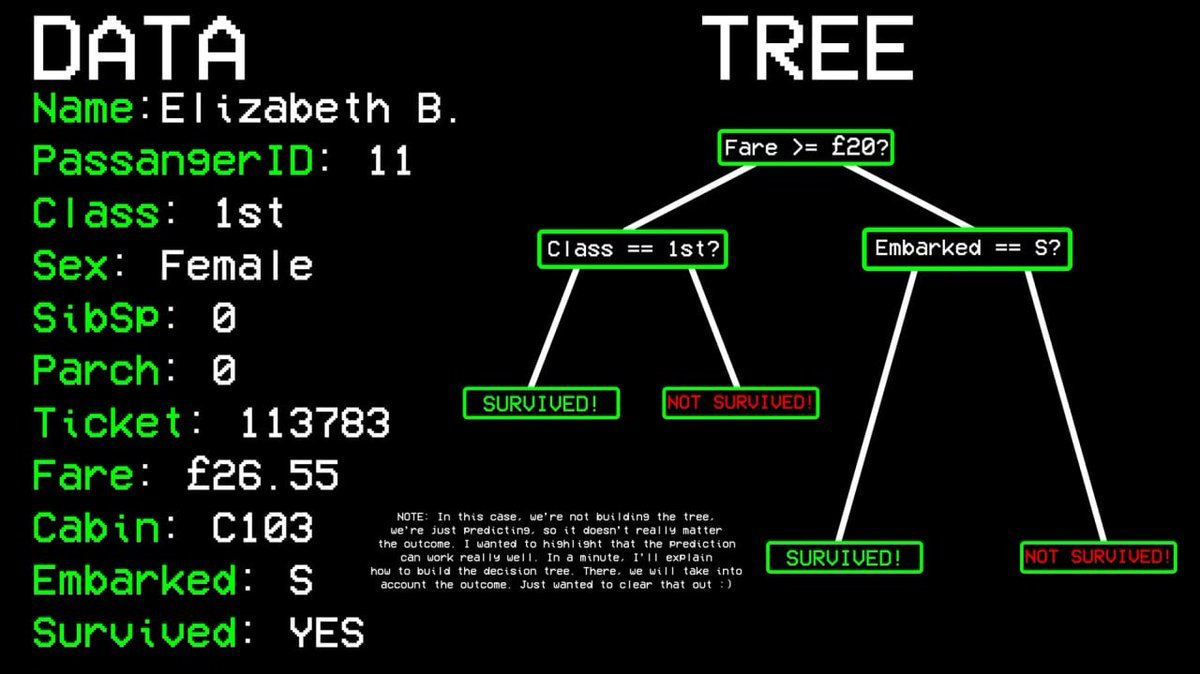
举个例子:11 号乘客是否存活?
问题一:TA 在头等舱吗?→ 是的。
问题二:TA 是女性吗?→ 是的。
预测结果:存活。
算法如何决定问哪些问题?
它从所有数据出发,找到最能区分「存活」和「未存活」的单一变量。在泰坦尼克号数据中,答案是舱位等级。头等舱乘客走一边,其他人走另一边。
但头等舱也有人遇难,仍存在「不纯度」。算法继续寻找下一个最佳分割点,性别。头等舱女性全部存活,形成「纯节点」,分支到此终止。
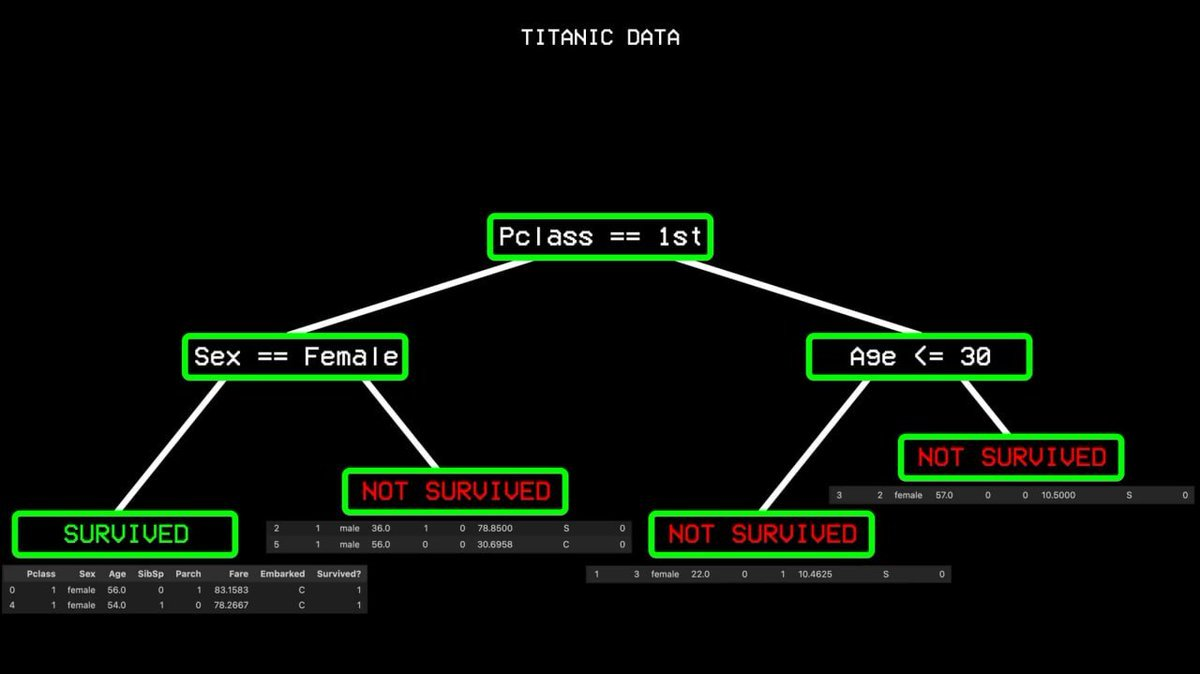
不断重复这个过程,直到构建出一棵覆盖所有情况的完整决策树。
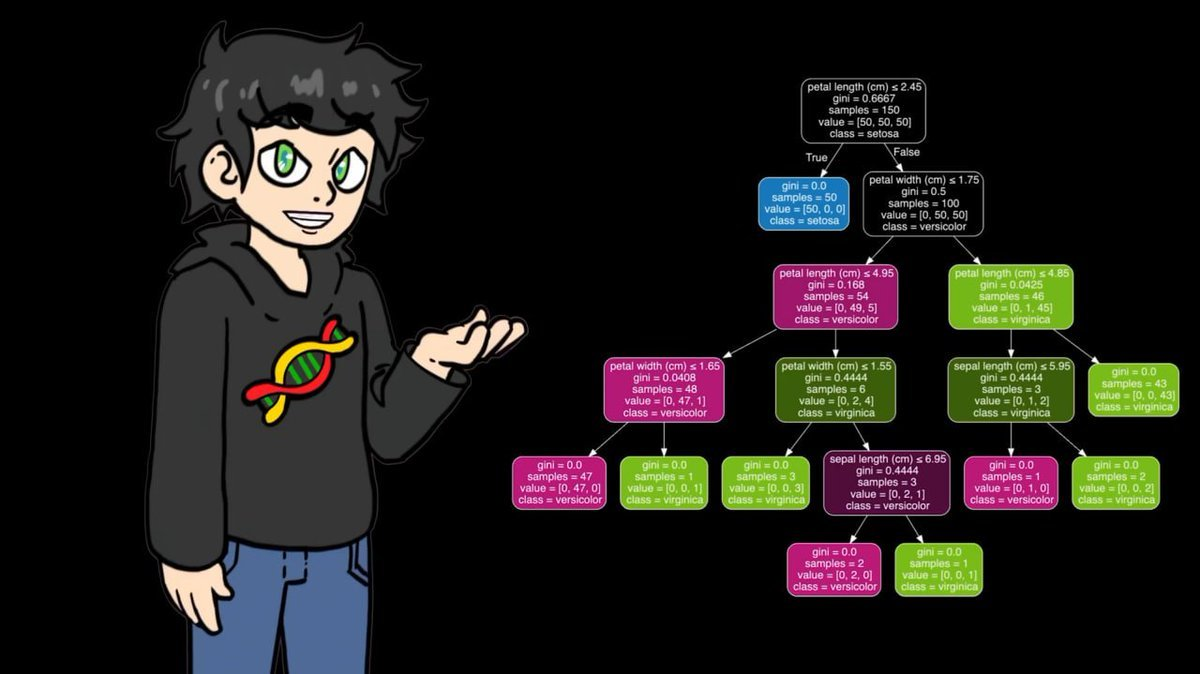
他的 numpy 手写版在小数据集上表现良好,但用在 95,000 条网球比赛数据上时,速度慢得令人崩溃。于是在正式训练阶段,他切换到 sklearn 的优化版本,逻辑相同,但快得多。
第三步:找到决定胜负的关键变量
在训练模型之前,他先将所有变量两两绘制成一张巨大的散点图矩阵(SNS pairplot),寻找能够区分胜者与败者的规律。

大多数特征都是噪声。球员ID显然没用。胜率差值虽然呈现出一些规律,但不够明显,无法支撑可靠的分类器。
只有一个变量远超其他:ELO差值(ELO_DIFF)。
ELO_DIFF和ELO_SURFACE_DIFF的散点图清晰展示了两个类别之间的分离程度,其他任何特征都无法与之相比。
这一发现促使他构建了整个项目最核心的部分。
第四步:将国际象棋评分系统引入网球
ELO 是一套评估选手技术水平的方法,最早应用于国际象棋。目前国际象棋世界第一 Magnus Carlsen 的评分是 2833 分。

他决定将这套系统应用到网球上:
每位球员起始评分:1500 分
赢球:评分上升;输球:评分下降
核心机制:得失分多少取决于与对手的评分差距击败高评分对手,得分更多,输给低评分对手,扣分更重
他用 2023 年温布尔顿决赛演示这套公式:卡洛斯·阿尔卡拉斯(评分 2063)对阵诺瓦克·德约科维奇(评分 2120),阿尔卡拉斯逆转夺冠。

代入公式计算:阿尔卡拉斯 +14 分,德约科维奇 -14 分。
计算虽简单,但应用在 43 年历史数据上时,威力惊人。
第五步:三巨头统治力的可视化证明
他将费德勒整个职业生涯的 ELO 评分绘制成曲线,从初登职业赛场到退役,每一场比赛都清晰记录。
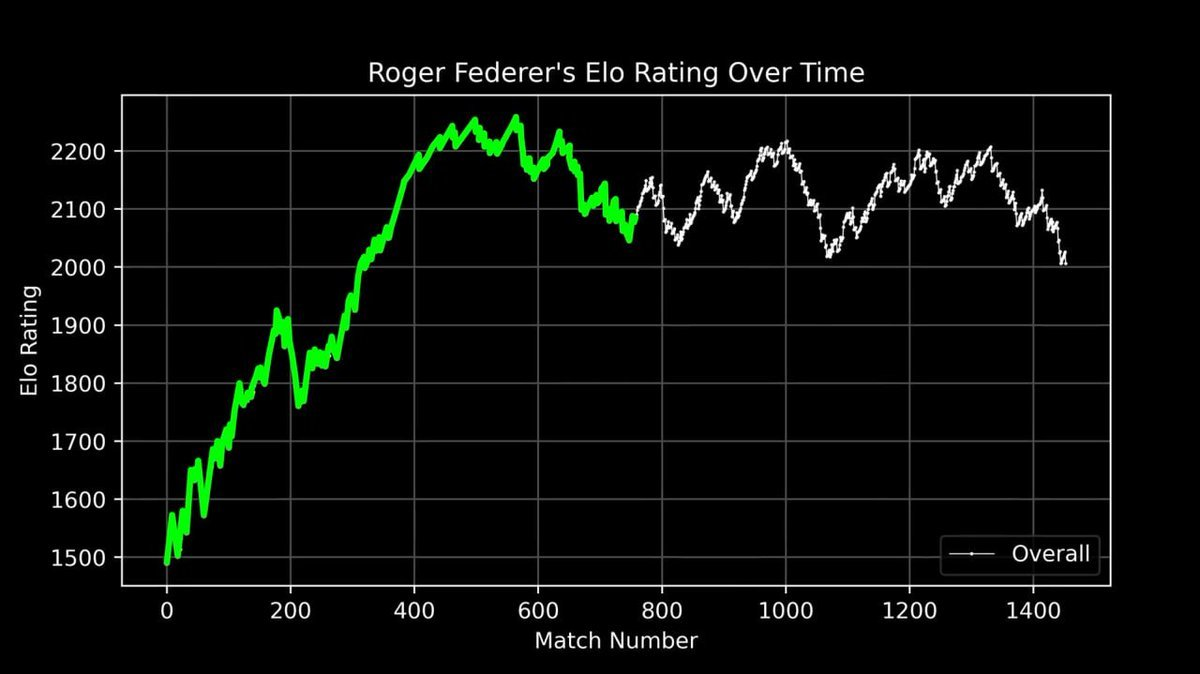
这条曲线完整展现了一段传奇:早期的快速攀升、巅峰期(约第 400 场比赛前后)的绝对统治,以及职业生涯后期的波动起伏。
但真正震撼的,是将费德勒与 1985 年以来所有 ATP 球员放在同一张图上时:
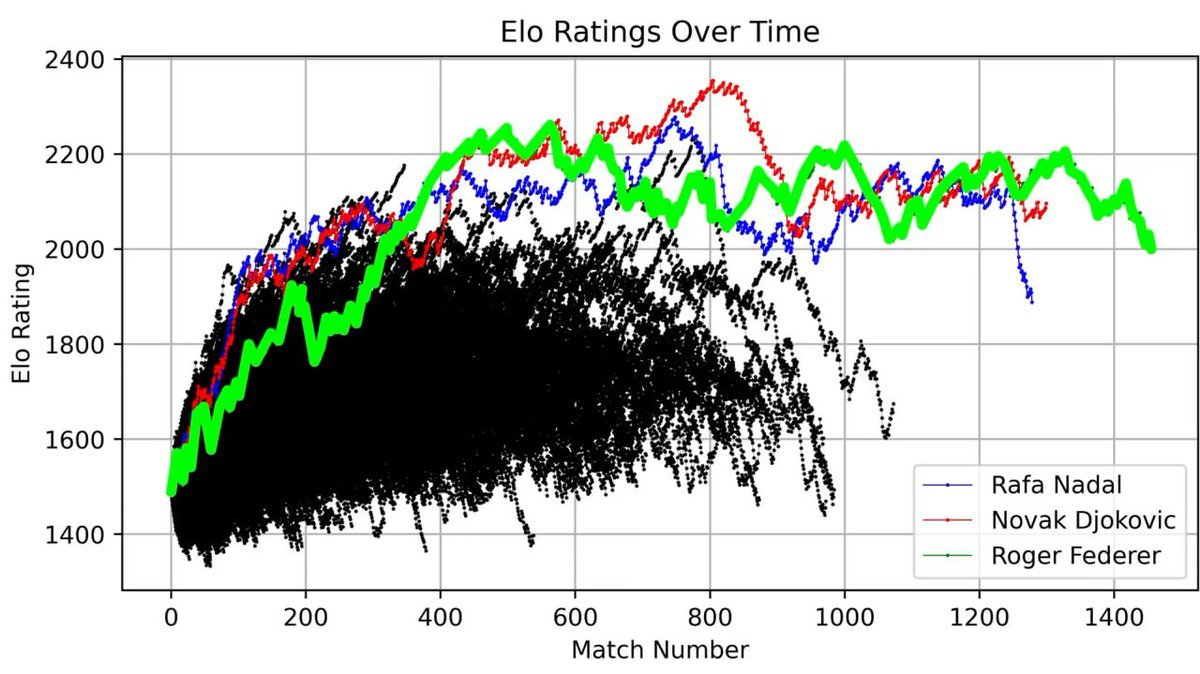
三条曲线高高矗立,远超其他所有人——费德勒(绿)、纳达尔(蓝)、德约科维奇(红)。
「大满贯三巨头」不只是一个称号。当你将 40 年的比赛数据可视化后会发现,这种统治力在数学上清晰可见。
根据他的自定义 ELO 系统,当前世界第一是雅尼克·辛纳(2176 分),其次是德约科维奇(2096 分)和阿尔卡拉斯(2003 分)。
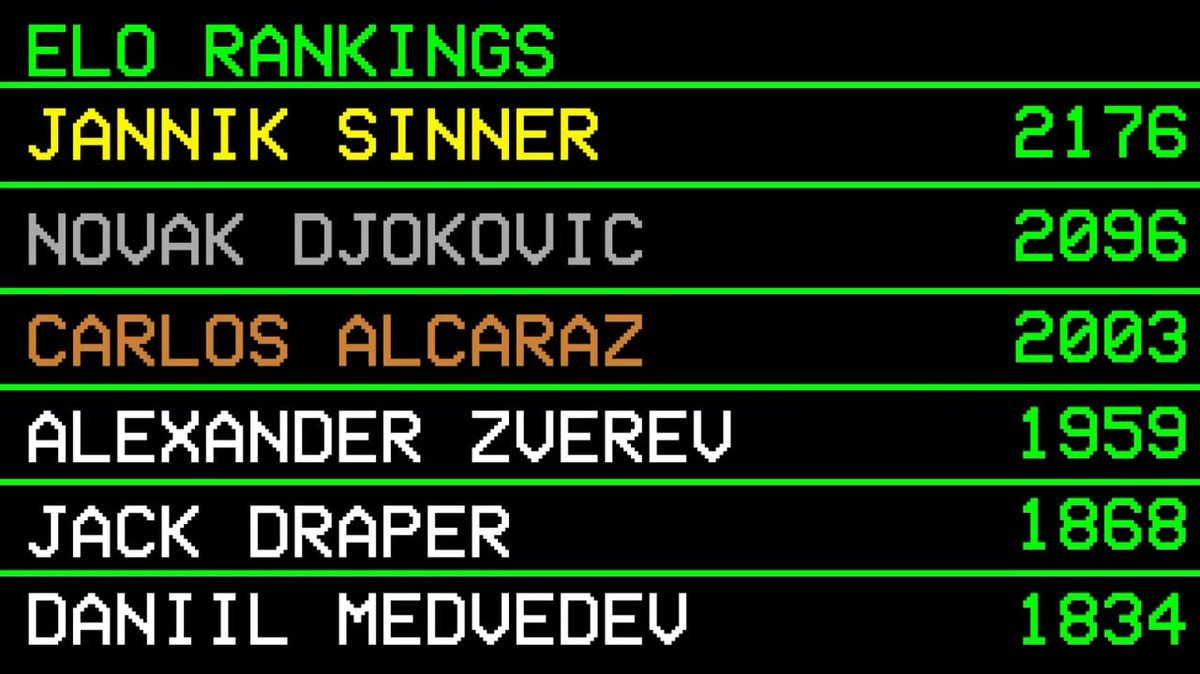
记住辛纳排名第一这一点,这在后面至关重要。
第六步:场地是改变一切的变量
网球比赛的场地类型会彻底改变这项运动的面貌:
红土:慢速,弹跳高
草地:快速,弹跳低
硬地:介于两者之间
在某种场地呼风唤雨的球员,换个场地可能完全崩溃。
所以他为三种场地分别建立了 ELO 评分:红土、草地、硬地。
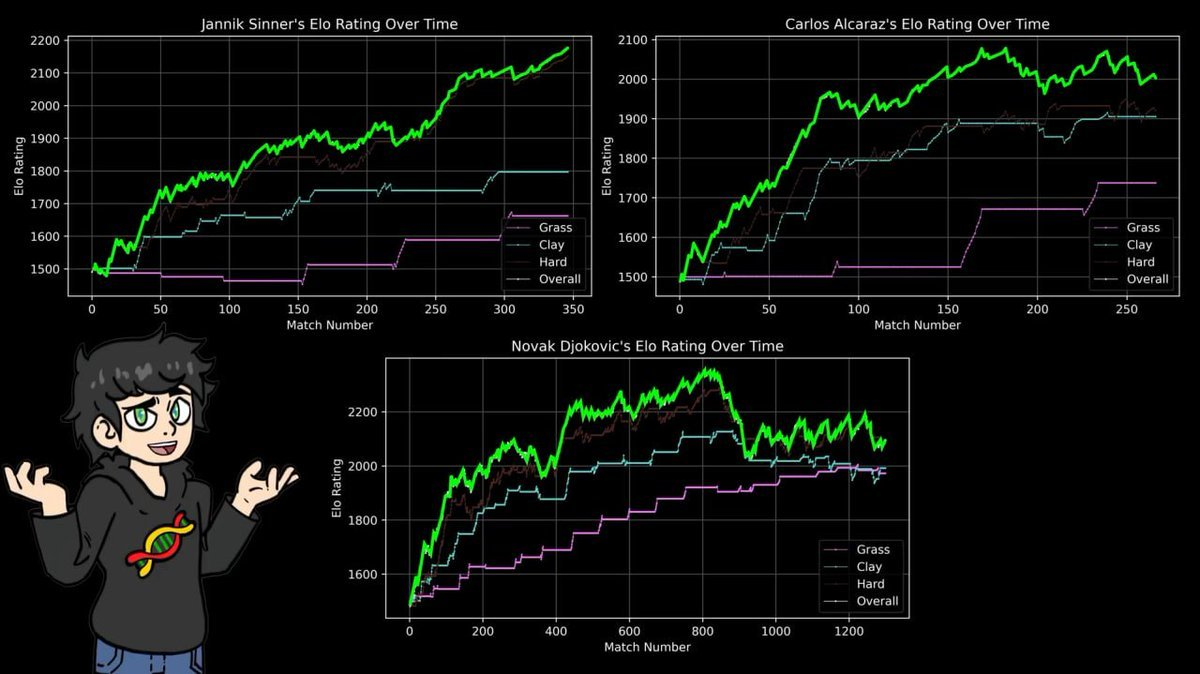
结果印证了每个网球迷心知肚明的事实,并用 43 年的数据作为佐证:
纳达尔在红土上的巅峰评分,超过了费德勒在草地上的最高分,超过了德约科维奇在硬地上的最高分,超过了任何人在任何场地的历史最高峰。
14 座法网冠军,在罗兰加洛斯 112 胜 4 负。
ELO 公式不在乎叙事,不在乎名气,它只处理胜负记录。而它得出的结论,和四十年的体育新闻报道完全一致。
第七步:遇到天花板
数据准备完毕,ELO 系统搭建完成,他开始训练分类器。这个过程完美展示了算法选择的重要性。
决策树:准确率 74%
单棵决策树在完整数据集上达到了 74% 的准确率。听起来不错——直到你发现,单纯用 ELO 差值预测胜者,就能达到 72%。
决策树在他已经手动建好的评分系统基础上,几乎没有带来任何提升。
随机森林:准确率 76%
单棵决策树的问题在于「高方差」——它对训练时恰好选到的数据子集过于敏感。标准解法是随机森林:建立几十棵乃至上百棵决策树,每棵用不同的随机数据子集和特征子集训练,最后通过多数投票决定预测结果。

94 棵各不相同的决策树,共同为每场比赛投票。

结果是 76%。有所提升,但他撞上了天花板。无论怎么调整超参数、重新设计特征、折腾数据,准确率就是过不了 77%。
第八步:突破天花板
接着他尝试了XGBoost——他称之为「随机森林的类固醇版本」。
核心区别在于:随机森林并行建树后取平均,而XGBoost串行建树——每棵新树专门修正前面所有树的错误。它引入了正则化防止过拟合,并刻意保持每棵树的小规模,避免死记硬背训练数据。
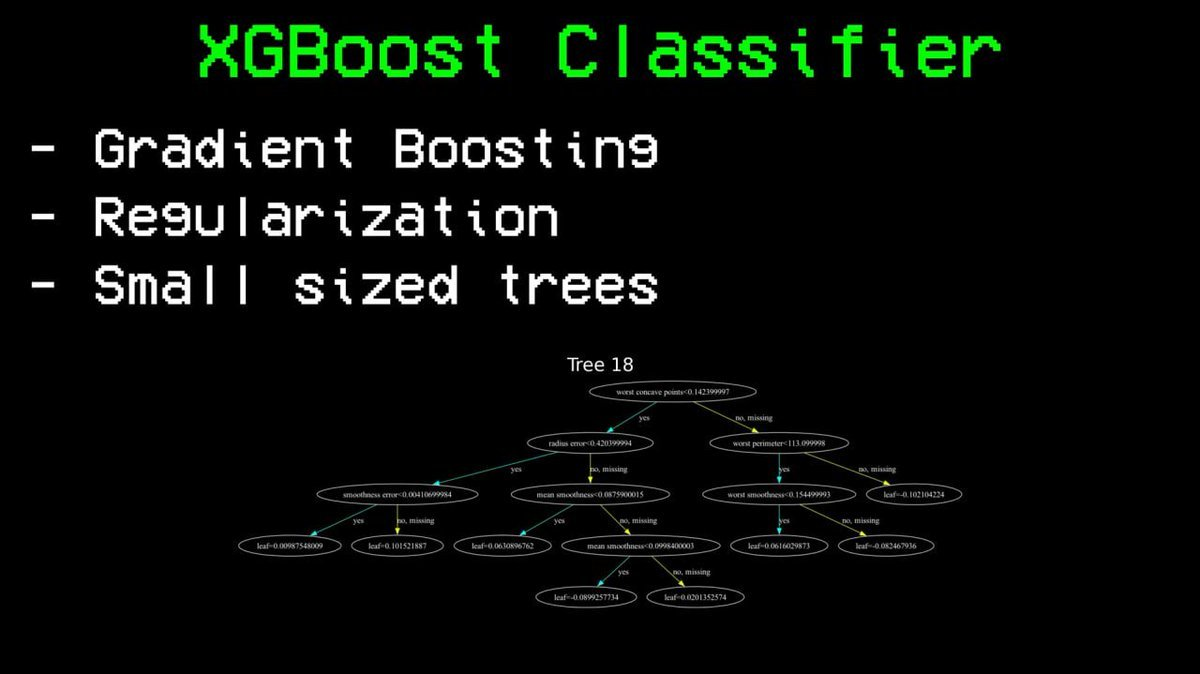
结果:准确率85%。
相比随机森林76%的天花板,这是巨大的突破。同样的数据,同样的特征,唯一改变的是算法。
XGBoost同样认为最重要的三个特征是:ELO差值、场地专项ELO差值、总体ELO。这套从国际象棋借鉴来的评分系统,在81列特征中被验证为最强预测因子。
作为对比,他用同样的数据训练了一个神经网络,准确率83%。虽然不错,但仍输给XGBoost。在这个数据集上,基于树的方法获胜。
第九步:决战时刻——2025 年澳大利亚网球公开赛
以上所有内容,都基于 2024 年 12 月之前的数据训练。
2025 年 1 月的澳大利亚网球公开赛完全不在训练集中,这使它成为完美的测试场:模型究竟掌握了网球的真正规律,还是只会记忆历史模式?

他将完整的赛事签表输入模型,让它预测每一场比赛。
结果:116 场比赛中正确预测 99 场,仅失误 17 场。准确率 85.3%。
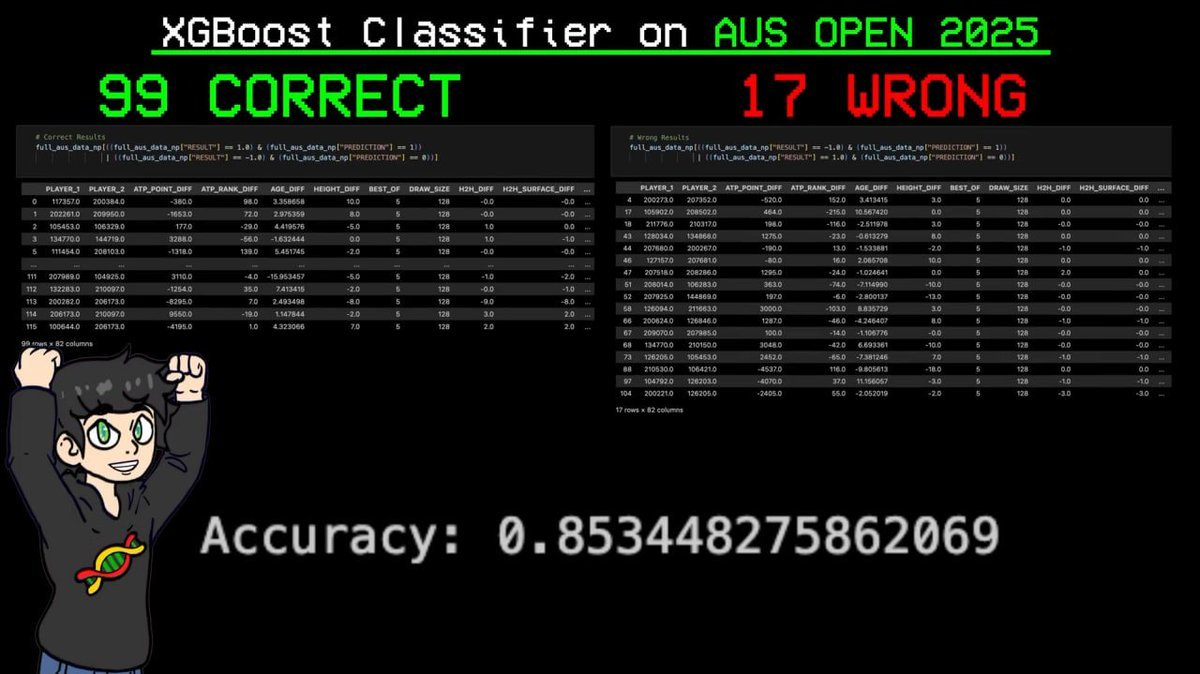
最关键的预测:模型准确预测了辛纳(那个 ELO 系统排名全球第一的球员)在整届赛事中的每一场胜利。
在第一颗球落地之前,AI 就预测出了大满贯冠军。
结语
一个人,一台笔记本电脑,没有专有数据,没有昂贵的基础设施,没有研究团队——就构建出了一套职业网球预测模型,准确率高达 85%,并在赛事开始前预测出了大满贯冠军。
网球数据就在 GitHub 上,完全可复现。
创造奇迹,从未像今天这样触手可及。
真正的差距不在资源,而在于你是否愿意去做。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







