编译:深潮TechFlow
Curve Finance的创始人@newmichwill最近在推文中表示,加密货币的主要目的在于DeFi(去中心化金融),而AI(人工智能)根本不需要加密货币。虽然我同意DeFi是加密领域的重要组成部分,但我并不认同AI不需要加密货币的观点。
随着AI代理(AI agents)的兴起,许多代理通常会附带一个代币,这让人们误以为加密货币与AI的交集仅仅是这些AI代理。而另一个被忽视的重要话题是“去中心化AI”,这与AI模型本身的训练息息相关。
我对某些叙事的不满在于,大多数用户会盲目地认为某事物在流行时就一定重要且有用,甚至更糟的是,他们认为这些叙事的唯一目标就是尽可能地榨取价值(换句话说,就是赚钱)。
在讨论去中心化AI时,我们首先应该问自己:为什么AI需要去中心化?以及这会带来哪些后果?
事实证明,去中心化的理念几乎总是不可避免地与“激励机制的对齐”这一概念联系在一起。
在AI领域,有许多根本性的问题可以通过加密技术来解决,更有一些机制不仅能解决现有问题,还能为AI增加更多的可信度。
那么,为什么AI需要加密货币呢?
1. 高昂的计算成本限制了参与和创新
无论幸运与否,大型AI模型需要大量的计算资源,这自然限制了许多潜在用户的参与。大多数情况下,AI模型需要海量的数据资源以及实际的计算能力,而这些对于单个个体来说几乎难以承担。
这一问题在开源开发中尤为突出。贡献者不仅需要投入时间来训练模型,还必须投入计算资源,这使得开源开发效率低下。
确实,个体可以投入大量资源来运行AI模型,就像用户可以为运行自己区块链节点分配计算资源一样。
然而,这并不能从根本上解决问题,因为算力仍不足以完成相关任务。
独立开发者或研究人员无法参与诸如LLaMA这类大型AI模型的开发,仅仅因为他们无法承担训练模型所需的计算成本:需要成千上万的GPU、数据中心以及额外的基础设施。
以下是一些规模感知的数据:
→ 埃隆·马斯克(Elon Musk)表示,最新的Grok 3模型使用了10万块Nvidia H100 GPU进行训练。
→ 每块芯片的价值约为3万美元。
→ 用于训练Grok 3的AI芯片总成本约为30亿美元。
这一问题在某种程度上类似于初创企业的建设过程,个体可能拥有时间、技术能力和执行计划,但一开始却缺乏足够的资源来实现愿景。
正如@dbarabander所指出的,传统的开源软件项目只需要贡献者捐赠时间,而开源AI项目则需要时间和大量资源,例如算力和数据。
仅仅依靠善意和志愿者的努力不足以激励足够多的个人或团体提供这些高昂的资源。额外的激励机制是驱动参与的必要条件。
2. 加密技术是实现激励对齐的最佳工具
所谓激励对齐(Incentive Alignment),是指通过制定规则,鼓励参与者在为系统做出贡献的同时,也能获得自身利益。
加密技术在帮助不同系统实现激励对齐方面有无数成功案例,而最显著的例子之一就是去中心化物理基础设施网络(DePIN)行业,它与这一理念完美契合。
例如,@helium和 @rendernetwork这样的项目通过分布式的节点和GPU网络实现了激励对齐,成为了典范。
那么,为什么我们不能将这一模式应用到AI领域,使其生态系统更加开放和可访问呢?
事实证明,我们是可以的。
推动Web3和加密技术发展的核心在于“所有权”。
你拥有自己的数据,你拥有自己的激励机制,甚至当你持有某些代币时,你也拥有了网络的一部分。赋予资源提供者所有权,可以激励他们将自己的资产提供给项目,期待从网络的成功中获得回报。
为了让AI更加普及,加密技术是最优解。开发者可以在项目之间自由共享模型设计,而计算和数据提供者则可以通过提供资源换取所有权份额(激励)。
3. 激励对齐与可验证性密切相关
如果我们设想一个具备适当激励对齐的去中心化AI系统,它应该继承经典区块链机制的一些特性:
-
网络效应(Network Effects)。
-
较低的初始要求,节点可以通过未来的收益获得回报。
-
惩罚机制(Slashing Mechanisms),对恶意行为者进行处罚。
尤其是对于惩罚机制,我们需要可验证性。如果无法验证谁是恶意行为者,就无法对其进行惩罚,这将使系统极易被作弊者利用,尤其是在跨团队协作的情况下。
在去中心化AI系统中,可验证性至关重要,因为我们没有一个集中的信任点。相反,我们追求的是一个无需信任但可验证的系统。以下是可能需要可验证性的多个组件:
-
基准测试阶段(Benchmark Phase):系统在某些指标(如x、y、z)上优于其他系统。
-
推理阶段(Inference Phase):系统运行是否正确,即AI的“思考”阶段。
-
训练阶段(Training Phase):系统是否被正确训练或调整。
-
数据阶段(Data Phase):系统是否正确收集数据。
目前有数百个团队在@eigenlayer上构建项目,但我最近注意到,AI的关注度比以往更高,我也在思考这是否与其最初的再质押(Restaking)愿景相符。
任何希望实现激励对齐的AI系统都必须是可验证的。
在这种情况下,惩罚机制等同于可验证性:如果一个去中心化系统能够对恶意行为者进行惩罚,就意味着它能够识别并验证这些恶意行为的存在。
如果系统是可验证的,那么AI就可以利用加密技术接入全球的计算和数据资源,从而打造更大、更强的模型。因为更多的资源(计算+数据)通常会带来更好的模型(至少在当前的技术世界中是如此)。
@hyperbolic_labs 已经展示了协作计算资源的潜力。任何用户都可以租用GPU,用于训练比他们在家中能够运行的更加复杂的AI模型,而且成本更低。
如何让AI验证既高效又可验证?
有人可能会说,现在有许多云解决方案可以租用GPU,这已经解决了计算资源的问题。
然而,像AWS或Google Cloud这样的云解决方案高度集中化,并且采用所谓的“候补名单策略”(Waitlist Strategy),人为制造高需求的假象,从而抬高价格。这种现象在该领域的寡头垄断格局中尤为常见。
实际上,有大量GPU资源闲置在数据中心、矿场,甚至个人手中,这些资源本可以用于AI模型训练的计算贡献,但却被浪费了。
你可能听说过@getgrass_io,它允许用户将未使用的带宽出售给企业,从而避免带宽资源的浪费,并获得一定的奖励。
我并不是说计算资源是无限的,但任何系统都可以通过优化来实现双赢:一方面,为需要更多资源进行AI模型训练的人提供更开放的市场;另一方面,让贡献这些资源的人获得相应的回报。
Hyperbolic团队开发了一个开放的GPU市场。在这里,用户可以租用GPU用于AI模型训练,节省高达75%的成本,而GPU提供者则可以将闲置资源货币化,获得收益。
以下是其工作方式的概述:
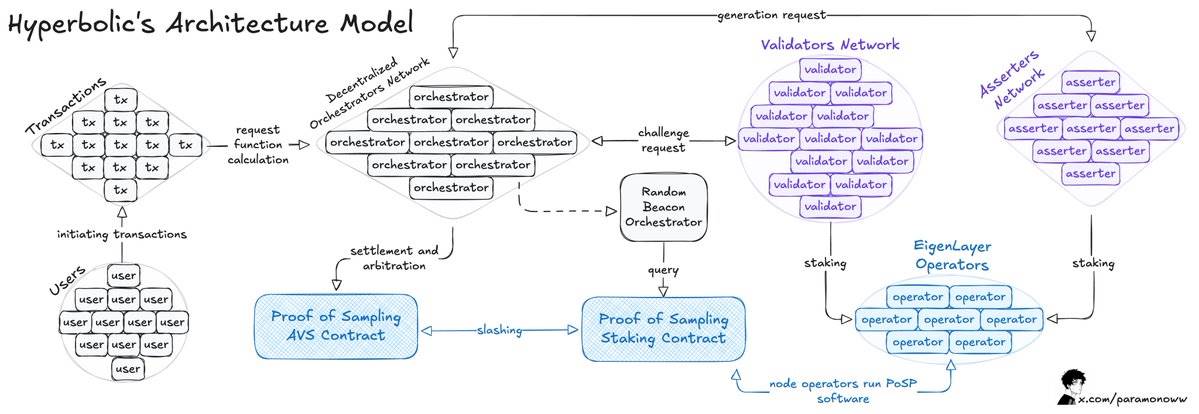
Hyperbolic通过将连接的GPU组织成集群和节点,使计算能力能够根据需求进行扩展。
该架构模型的核心是“采样证明”(Proof of Sampling)模型,其特点是将交易进行采样处理:通过随机选择和验证交易,减少了工作负载和计算需求。
主要问题出现在AI的推理(Inference)过程中,在网络上运行的每次推理都需要被验证,且最好能避免其他机制带来的显著计算开销。
正如我之前所说,如果某件事情可以被验证,那么如果验证结果表明该行为违反规则,就必须对其进行惩罚(Slashing)。
当Hyperbolic采用AVS(Adaptive Verification System,自适应验证系统)模型时,它为系统增加了更多的可验证性。在这一模型中,验证者是随机选出的,用于验证输出结果,从而使系统实现激励对齐——在这种机制下,不诚实的行为是无利可图的。
要训练一个AI模型并使其更完善,主要需要两个资源:计算能力和数据。租用计算能力是一个解决方案,但我们仍然需要从某处获取数据,并且需要多样化的数据以避免模型可能的偏见。
为AI验证来自不同来源的数据
数据越多,模型越好;但问题在于,你通常需要多样化的数据。这是AI模型面临的一个主要挑战。
数据协议已经存在了几十年。无论数据是公开的还是私有的,数据经纪人都会以某种方式收集这些数据,可能会付费,也可能不会,然后将其出售以获取利润。
我们在为AI模型获取合适数据时面临的问题包括:单点故障、审查制度,以及缺乏一种无需信任的方式来提供真实可靠的数据以“喂养”AI模型。
那么,谁需要这样的数据?
首先,是AI研究人员和开发者,他们希望通过真实且适当的输入来训练和推理他们的模型。
例如,OpenLayer允许任何人无需许可地向系统或AI模型添加数据流,并且系统可以以一种可验证的方式记录每一条可用的数据。
OpenLayer还使用了zkTLS(零知识传输层安全协议),这一点在我之前的文章中有详细描述。该协议确保操作员报告的数据确实是他们从来源获得的(可验证性)。
这是OpenLayer的工作原理:
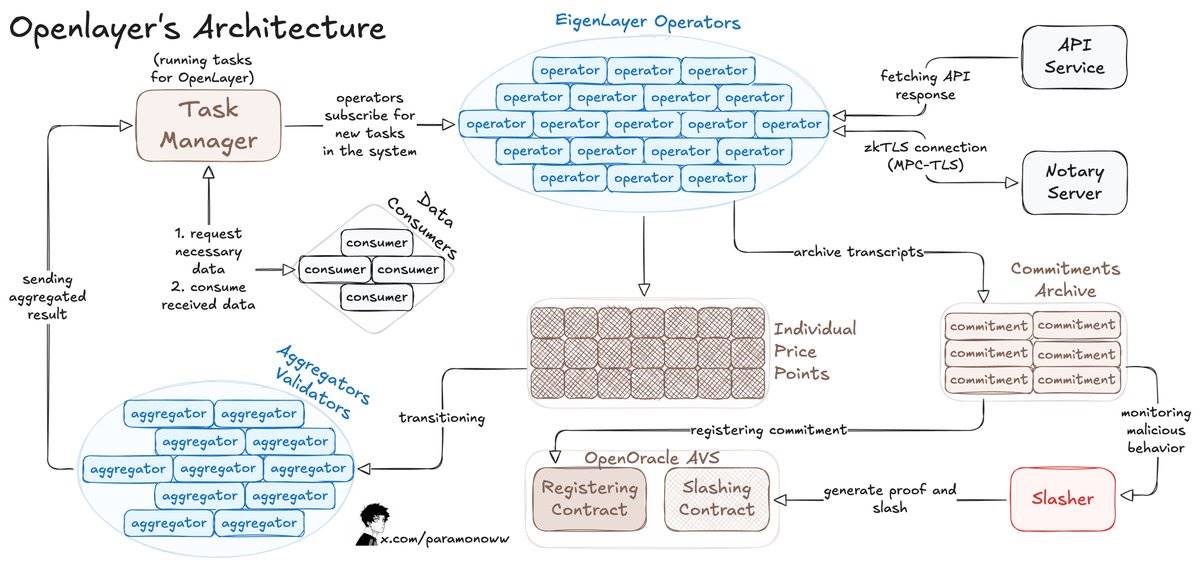
-
数据消费者向OpenLayer的智能合约发布数据请求,并通过合约(链上或链下)使用类似主要数据预言机的API检索结果。
-
操作员通过EigenLayer注册,以保障OpenLayer AVS的质押资产,并运行AVS软件。
-
操作员订阅任务,处理并提交数据到OpenLayer,同时将原始响应和证明存储在去中心化存储中。
-
对于可变结果,聚合器(特殊的操作员)会对输出进行标准化处理。
开发者可以向任何网站请求最新数据,并将其接入网络。如果你正在开发AI相关项目,你可以获得可靠的实时数据。
在我们探讨了AI计算过程和获取可验证数据的方式之后,接下来需要关注的是AI模型的两大核心部分:计算本身及其验证。
AI计算必须通过验证才能确保正确性
在理想情况下,节点必须证明其计算贡献,以确保系统的正常运行。
而在最糟糕的情况下,节点可能会虚假声称提供了计算能力,但实际上并未做任何实际工作。
要求节点证明其贡献,可以确保只有合法的参与者被认可,从而避免恶意行为。这种机制与传统的工作量证明(Proof of Work)非常相似,不同之处在于节点执行的工作类型。
即使我们为系统加入了适当的激励对齐机制,如果节点无法无需许可地证明其完成了某些工作,它们可能会获得与实际贡献不符的奖励,甚至可能导致奖励分配不公。
如果网络无法评估计算贡献,就可能导致某些节点被分配超出其能力的任务,而其他节点则处于闲置状态,最终引发效率低下或系统故障。
通过证明计算贡献,网络可以使用标准化指标(例如FLOPS,每秒浮点运算次数)量化每个节点的努力。这种方式能够根据实际完成的工作分配奖励,而不是仅仅依据节点是否存在于网络中。
来自@HyperspaceAI的团队开发了一种“FLOPS证明”(Proof-of-FLOPS)系统,使节点可以租赁未使用的计算能力。作为交换,他们会获得“flops”积分,这些积分将作为网络的通用货币。
该架构的工作原理如下:
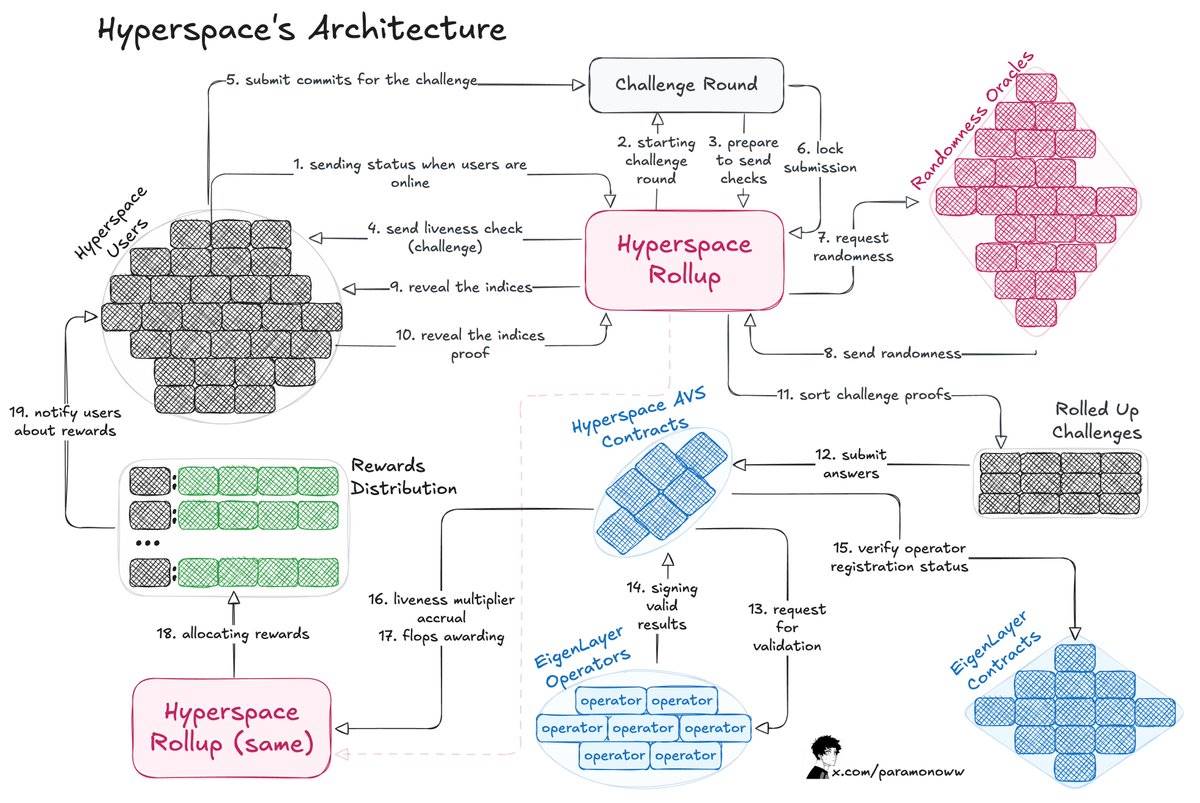
-
流程从向用户发出挑战开始,用户通过提交对挑战的承诺来回应。
-
Hyperspace Rollup管理流程,确保提交的安全性并从预言机获取随机数。
-
用户公开索引,挑战流程完成。
-
操作员检查响应,并将有效结果通知Hyperspace AVS合约,随后通过EigenLayer合约确认这些结果。
-
计算活跃度乘数(Liveness Multipliers),并向用户授予flops积分。
证明计算贡献提供了每个节点能力的清晰图景,因此系统可以智能地分配任务——将复杂的AI计算任务分配给高性能节点,而将较轻的任务分配给能力较低的节点。
最有趣的部分是如何让这一系统具备可验证性,从而任何人都可以证明完成工作的正确性。Hyperspace的AVS系统持续发送挑战、随机数请求,并执行多层验证流程,正如上文所述的架构图所示。
操作员可以放心参与系统,因为结果经过验证且奖励分配公平。如果结果不正确,恶意行为者将毫无疑问地受到惩罚(Slashing)。
验证AI计算结果有许多重要原因:
-
鼓励节点加入并贡献资源。
-
按努力程度公平分配奖励。
-
确保贡献直接支持特定的AI模型。
-
根据节点的验证能力有效分配任务。
AI的去中心化与可验证性
正如@yb_effect所指出的,“去中心化”(Decentralized)和“分布式”(Distributed)是完全不同的概念。分布式仅指硬件分布在不同位置,但仍然存在一个中心化的连接点。
而去中心化意味着没有单一的主节点,训练过程能够处理故障,这与当今大多数区块链的运行方式类似。
如果AI网络要实现真正的去中心化,需要采用多种解决方案,但可以确定的是,我们需要对几乎所有内容进行验证。
如果你想构建一个AI模型或智能体,你需要确保每个组件以及每个依赖项都经过验证。
推理、训练、数据、预言机——所有这些都可以被验证,从而不仅为AI系统引入与激励兼容的加密奖励,还能使系统更加公平和高效。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







