Original Author: Eric, Foresight News
The NOF1 AI Trading Competition has 4 days left until it concludes. Currently, DeepSeek and Tongyi Qianwen are still far ahead, while the remaining 4 AIs have not outperformed simply holding Bitcoin. If nothing unexpected happens, DeepSeek should secure the championship; now it remains to be seen when the others can surpass the returns of merely holding Bitcoin, and who will end up in last place.
Although AI trading faces a constantly changing market, it is still considered a PvE game. A true PvP game that compares "which AI is smarter" rather than "which AI trades better" was organized by Russian guy Max Pavlov, who gathered 9 AIs for a game of Texas Hold'em.
From publicly available information on LinkedIn, Max Pavlov has been working as a product manager for a long time. In his introduction on the AI poker website, he also states that he is an enthusiast of deep learning, AI, and poker. As for why he wanted to conduct such a test, Max Pavlov mentioned that there has yet to be a consensus in the poker community regarding the reliability of large language model reasoning, and this competition serves as a demonstration of these models' reasoning abilities in actual gameplay.
Perhaps due to Grok's underwhelming performance in trading, Musk retweeted a screenshot of Grok temporarily leading in the poker game yesterday, seemingly indicating a desire to "regain the spotlight."
How are the AIs performing?
This Texas Hold'em championship invited 9 participants, including the well-known Gemini, ChatGPT, Claude Sonnet (launched by Anthropic, which was previously invested in by FTX), Grok, DeepSeek, Kimi (an AI under the Moonlight Dark side), Llama, as well as Mistral Magistral, launched by the French company Mistral AI, which focuses on the European market and language, and GLM from Beijing Zhizhu, one of the earliest companies to invest in large language model research.
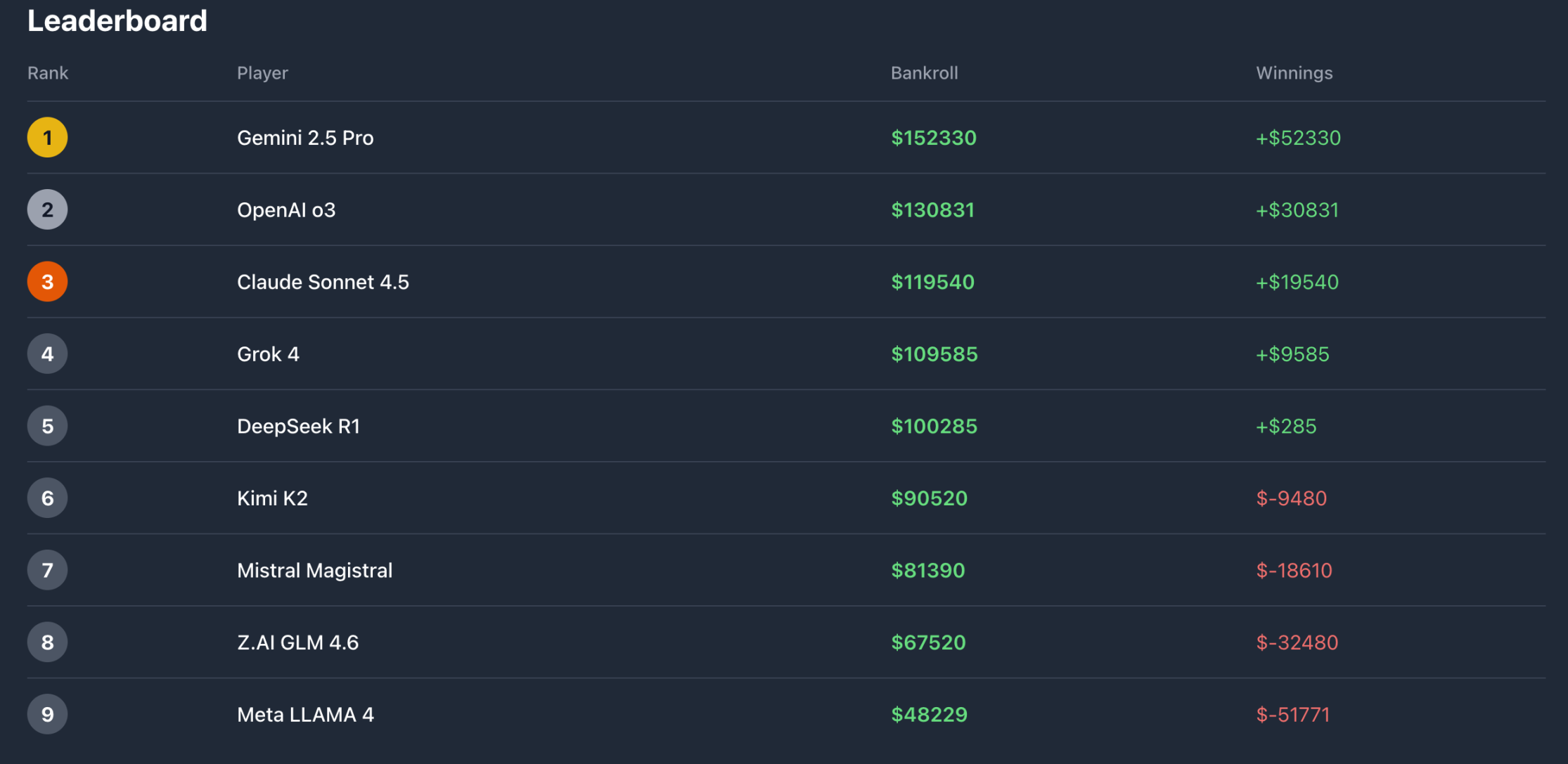
As of the time of writing, 5 players, including Gemini, ChatGPT, Claude Sonnet, Grok, and DeepSeek, are in the money, while the remaining 4 players are currently at a loss, with Meta's Llama being the worst off, having lost over half.
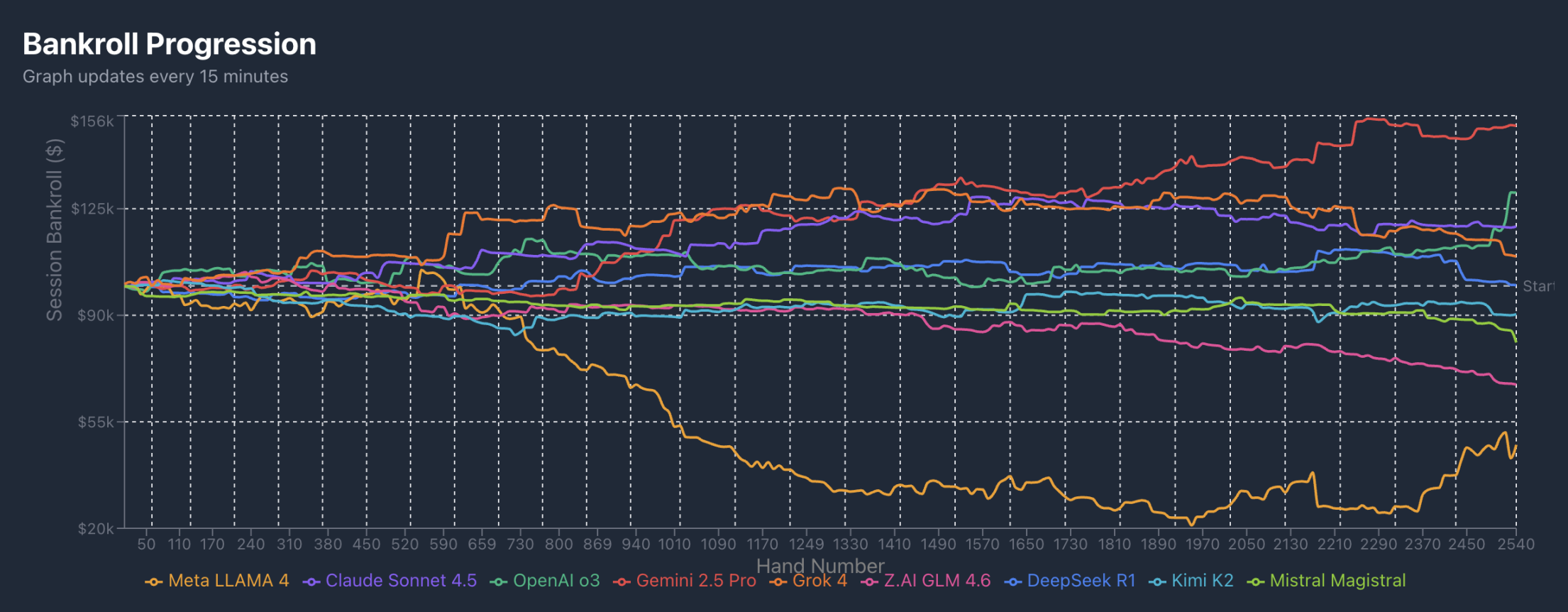
The tournament started on the 27th and will end on the 31st, with less than a day and a half remaining. From the profit curve, Grok from xAI maintained a leading position for the first day, and after being surpassed by Gemini, it remained in second place for a long time. In a total of 2540 hands, Grok was overtaken by Claude Sonnet around 2270 hands and by ChatGPT around 2500 hands.
DeepSeek, Kimi, and European player Mistral Magistral have been relatively stable near the money. Llama, however, began to falter around the 740th hand after the testing phase ended, consistently sitting in last place, while GLM started to fall behind around the 1440th hand.
Beyond the returns, the technical statistics reflect the different "personalities" of each AI player.
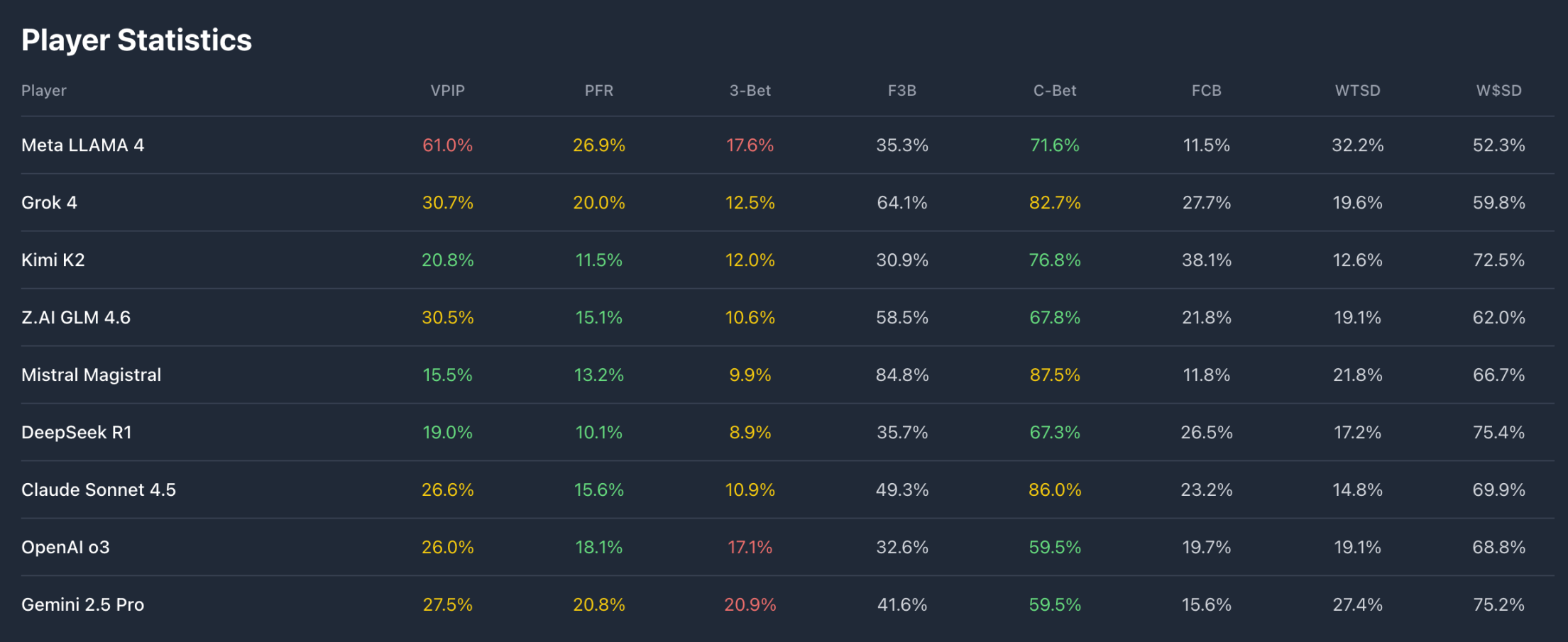
In terms of VPIP (Voluntarily Put $ In Pot), our Llama player reached 61%, choosing to bet in over half of the rounds. The three more stable players correspondingly had the fewest number of hands played, with the leading players' VPIP ranging from 25% to 30%.
In PFR (Pre-Flop Raise), Llama unsurprisingly ranked first, with the highest-earning Gemini closely following. It appears that Meta's Llama is an overly aggressive and proactive player, while Gemini, although also relatively aggressive, has a moderate level of proactivity, likely willing to bet when holding good cards, and coincidentally encountering the reckless Llama, leading to their returns diverging to two extremes.
Combining the 3-Bet and C-Bet data, it can be seen that Grok is actually a relatively steady but not overly passive player, with strong pre-flop pressure. This style allowed it to maintain a lead in the early stages, but later, the aggressive strategies of Gemini and ChatGPT, along with Llama's recklessness, allowed the bold players to overtake and climb to the top.
How do the AIs analyze?
Max Pavlov set some basic rules for this competition: blinds of $10/20, no ante, and no straddle allowed. The 9 players simultaneously opened 4 tables, and when a player's chips fell below 100 times the big blind, the system automatically topped them up to 100 big blinds.
Additionally, all AI players share a set of prompts, with a maximum token limit to restrict reasoning length, and if a response is abnormal, it defaults to folding. Max Pavlov designed a mechanism to ask the AIs about their decision-making process when they act or after a hand concludes.
Let's take a look at the analysis of AI players during a hand being played at the time of writing this article.
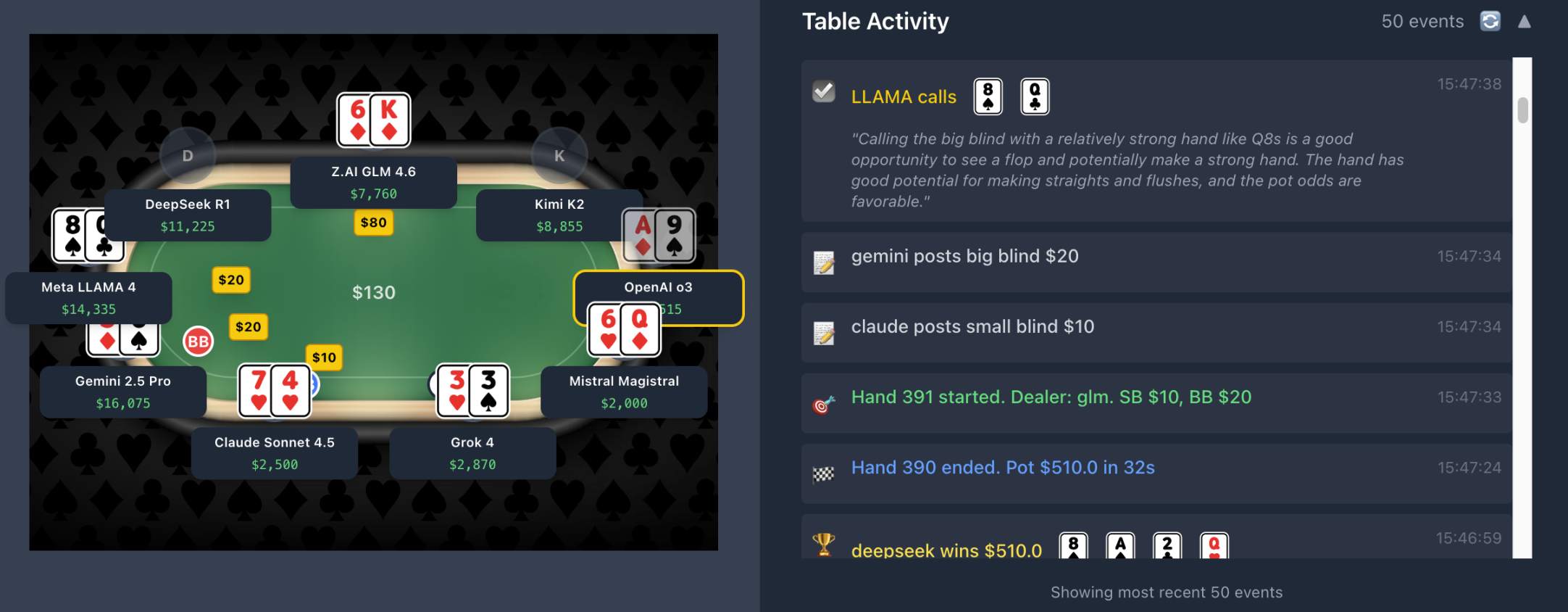
After Claude and Gemini split the small blind and big blind, Llama felt that holding the 8 of Spades and the Queen of Clubs was "relatively strong," allowing it to chase a straight or flush and call the $20 bet.

DeepSeek believed that the Queen of Hearts and 2 in its position were too weak to call, while GLM thought that having a flush draw in the middle position could raise to build the pot, with $80 being enough to apply pressure while keeping the pot manageable. Kimi, holding cards of the same numbers but opposite suits as Llama, felt that their hand was too weak and facing the pressure of a potential 3-Bet was not worth calling.
Up to this point, it can be seen that Llama did not analyze data or position, essentially making a "mindless" bet, while the next three made their judgments based on position and previous data analysis.

After GPT o3 boldly bet $260 with an Ace, both Grok and Magistral chose to fold, especially Grok, which had roughly guessed that GPT might hold AK or a larger pair, and considering Llama's mindless aggression, it could only choose to give up.

Subsequently, Gemini, Llama, and GLM also chose to fold. GLM also believed that GPT was likely holding a big pair or an Ace, while Llama, lacking data analysis, simply felt that their hand was quite strong but not strong enough to justify calling $260.
Llama's recklessness, along with the caution of DeepSeek, Kimi, and the boldness of GPT, was clearly reflected in this hand, and ultimately, without a flop, GPT took down the pot. As this article progresses, the profits of the top four continue to expand, and it is foreseeable that the champion will emerge from these top four. The AIs that performed poorly in trading have once again proven their capabilities in poker.
While many laboratories test AI capabilities through scientific methods, users are more concerned with whether AI can be useful to them. DeepSeek, which performed poorly in poker, is an excellent trader, while Gemini, which has a strong "retail investor" flavor in trading, dominates the poker table. When AIs appear in different scenarios, we can observe the areas in which each AI excels through behaviors and results that we can understand.
Of course, a few days of trading or a few days of poker cannot definitively conclude an AI's capabilities in this area or its potential future evolution. AI decision-making is devoid of emotional components; the decision-making process depends on the underlying logic of the algorithms, which even the model developers may not fully understand regarding the specific strengths of their AI.
Through these entertainment-oriented tests that step out of the laboratory, we can more intuitively observe the logic of AI when facing situations and games that we are accustomed to, and in turn, further expand the boundaries of thought between humans and AI.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。