Jensen Huang announced the Vera Rubin platform at GTC 2026 last night, claiming that the unit power consumption inference performance is ten times better than Blackwell, the inference token cost has decreased to one-tenth, and he forecasted that the combined orders of Blackwell and Vera Rubin will exceed one trillion dollars before 2027.
In the past two years, the inference cost of GPT-4 equivalent APIs has dropped by 94%, from 36 dollars per million tokens to under 2 dollars. Intuitively, as computing power becomes cheaper, companies should spend less. However, the capital expenditures of the four cloud providers: Amazon, Alphabet, Meta, and Microsoft have risen from 154 billion dollars to 416 billion dollars, nearly tripling.
Jensen Huang's trillion-dollar forecast is not just a marketing gimmick; there is a curve behind it that can be illustrated with data.
Each generation makes the previous one look pathetic
From the H100 in 2022 to the Vera Rubin, which will be mass-produced in the second half of 2026, the FP8 intensive inference computing power of NVIDIA's AI GPUs has increased eightfold in four years. According to NVIDIA's official specifications, the H100 single card has 2.0 PetaFLOPS, the B200 reaches 4.0 PF, and Vera Rubin jumps directly to 16 PF.
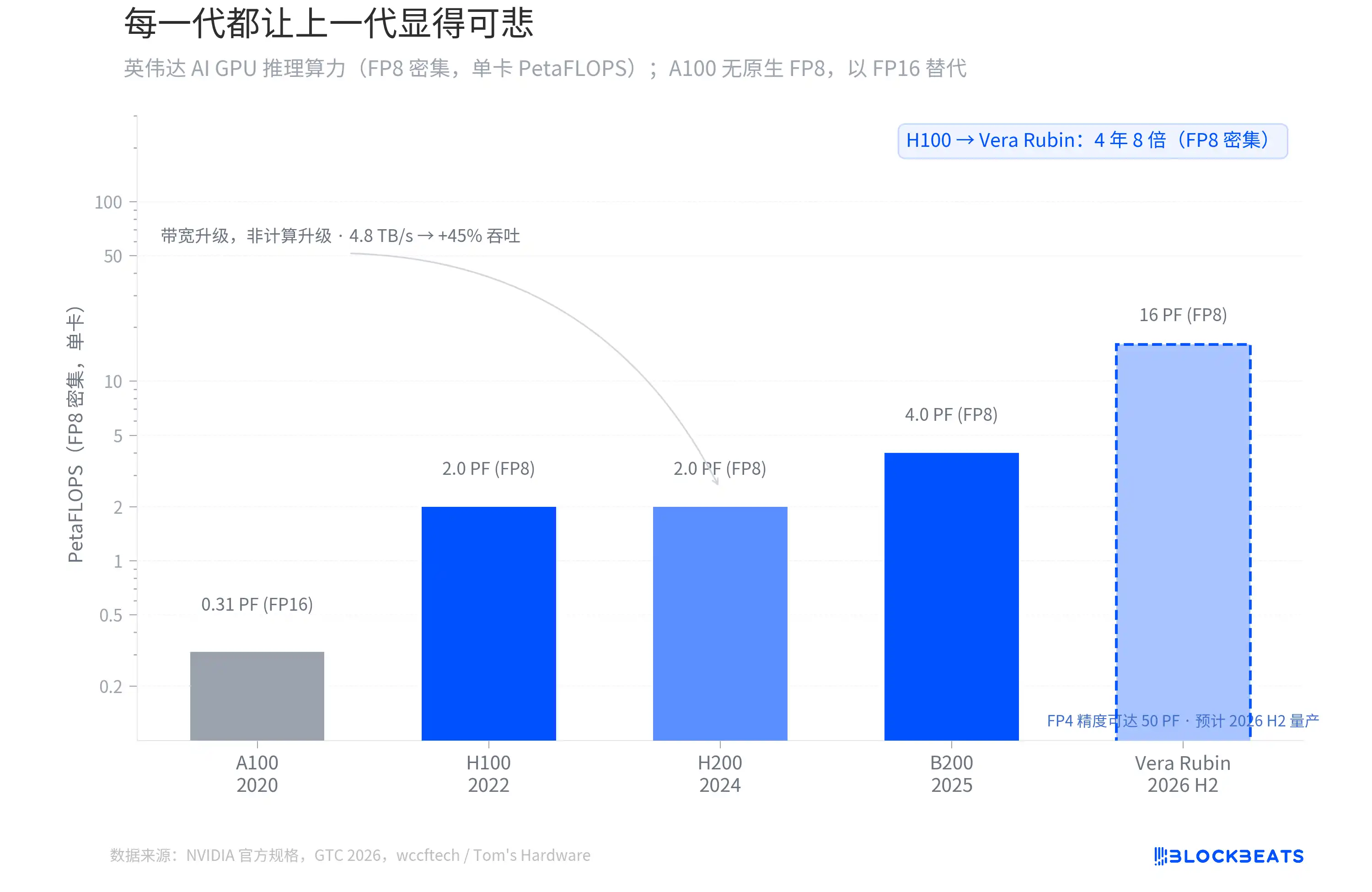
However, not every generational leap comes from the same source. According to wccftech, the computing cores of the H200 are exactly the same as those of the H100, with no change in FP8 computing power; its upgrades come entirely from memory bandwidth (increased from 3.35 TB/s to 4.8 TB/s), resulting in approximately a 45% increase in inference throughput.
The real architectural shift occurs in B200 and Vera Rubin. Vera Rubin uses TSMC's 3nm process and features a dual chiplet design with 336 billion transistors, achieving 50 PF in inference power at FP4 precision. According to Tom's Hardware, the first Vera Rubin system is already running on Microsoft Azure.
There is a distinction that is easily overlooked. The "ten times" mentioned by Jensen Huang at GTC refers to the reduction in inference token cost, not the multiple of original computing power. The token cost includes system-level factors such as Transformer Engine optimization, FP4 precision, and larger batch inference. In terms of standardized FP8 intensive TFLOPS, Vera Rubin is four times better than Blackwell and eight times better than H100.
The slope of this curve has never slowed down. Every generation of GPUs makes the previous generation seem inadequate, and this is the starting point for the story that follows.
The Jevons Paradox: The cheaper computing power gets, the more is spent
When GPT-4 first launched in March 2023, the API call cost was approximately 36 dollars per million tokens. According to OpenAI's official pricing history, by mid-2024, when GPT-4o is released, the price will drop to around 7 dollars, and by the end of 2025, the actual available price will be below 2 dollars. This represents a decrease of over 94% in two years.
Common sense suggests that with such a significant drop in inference costs, companies should be spending less. But in reality, the opposite is true. According to financial reports from various companies and tracking data from Platformonomics, the annual capital expenditures of Amazon, Alphabet, Meta, and Microsoft have increased from 154 billion dollars in 2023 to 416 billion dollars in 2025, an increase of 170%. Among them, Google alone increased from 32 billion to 91.5 billion (approximately 2.9 times), with Microsoft seeing an even larger increase.
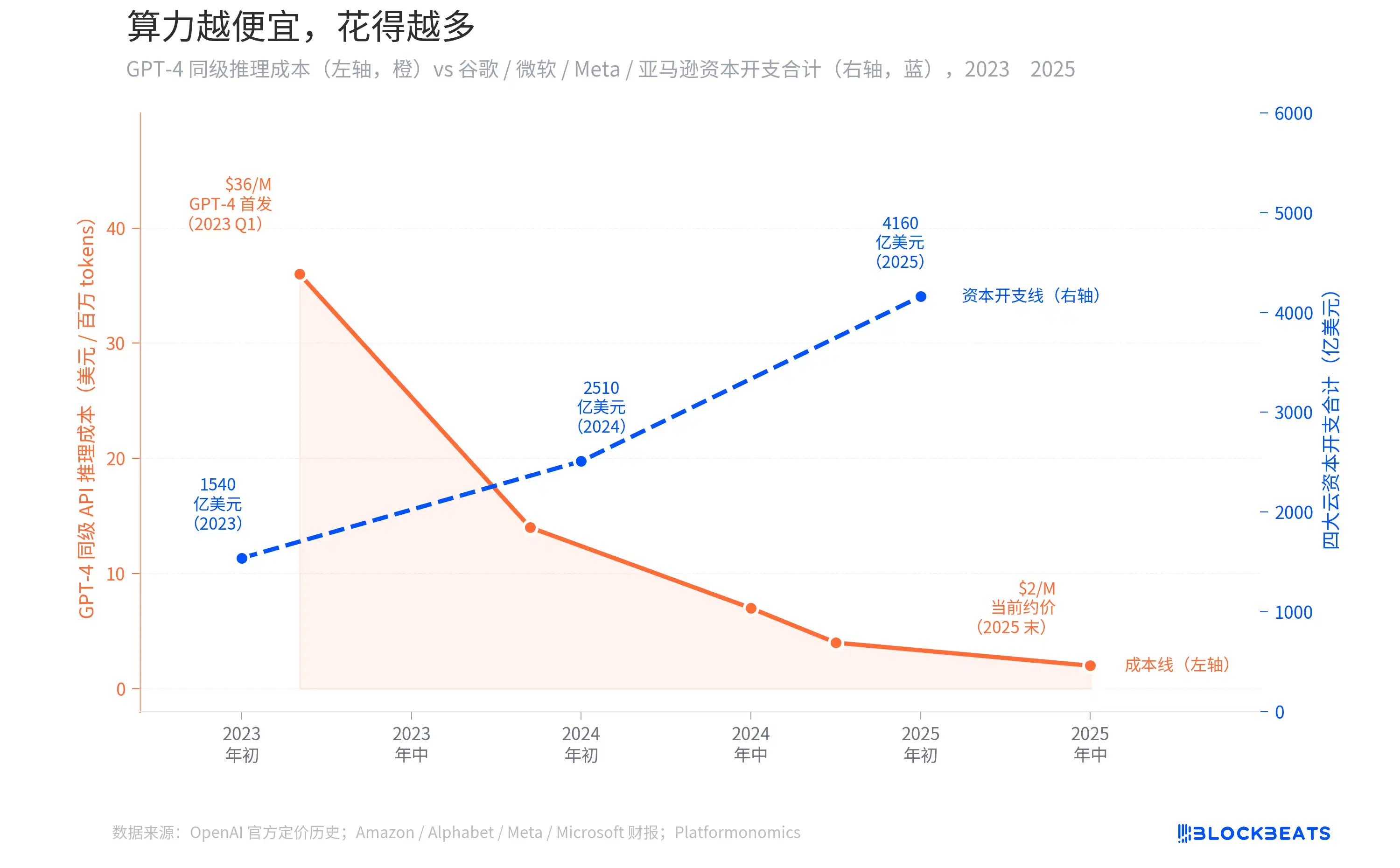
This phenomenon is known in economics as the Jevons Paradox. In 1865, British economist William Jevons found that improvements in the steam engine's efficiency led to an increase in coal consumption in Britain rather than a decrease. The reason is simple: the improved efficiency made steam engines more cost-effective, leading more industries to adopt them, thus greatly expanding total demand beyond the savings from efficiency.
The situation with AI inference today is exactly the same. As API prices drop to 6% of their original cost, companies have not saved budgets, rather, they have started to implement AI into scenarios where it previously was not cost-effective. Customer service, code review, content generation, search re-ranking, advertising bidding—each new scenario consumes more inference computing power. The speed of demand growth far exceeds the rate of cost decline. DeepSeek R1 drives input prices down to 0.55 dollars per million tokens in early 2025, further accelerating this cycle. The two counter-moving lines in the graph represent two sides of the same issue.
Three years, eleven times, and no ceiling in sight
If the Jevons Paradox has one direct beneficiary, it is those selling shovels.
According to NVIDIA's financial report, the annual revenue from the data center business increased from 10.6 billion dollars in FY2022 (ending January 2022) to 115.2 billion dollars in FY2025 (ending January 2025). Over three fiscal years, that is an increase of 10.9 times. This growth curve in revenue has almost no precedent in tech history. In comparison, it took Apple about 6 years after the iPhone was launched in 2007 to achieve a similar scale of revenue increase.
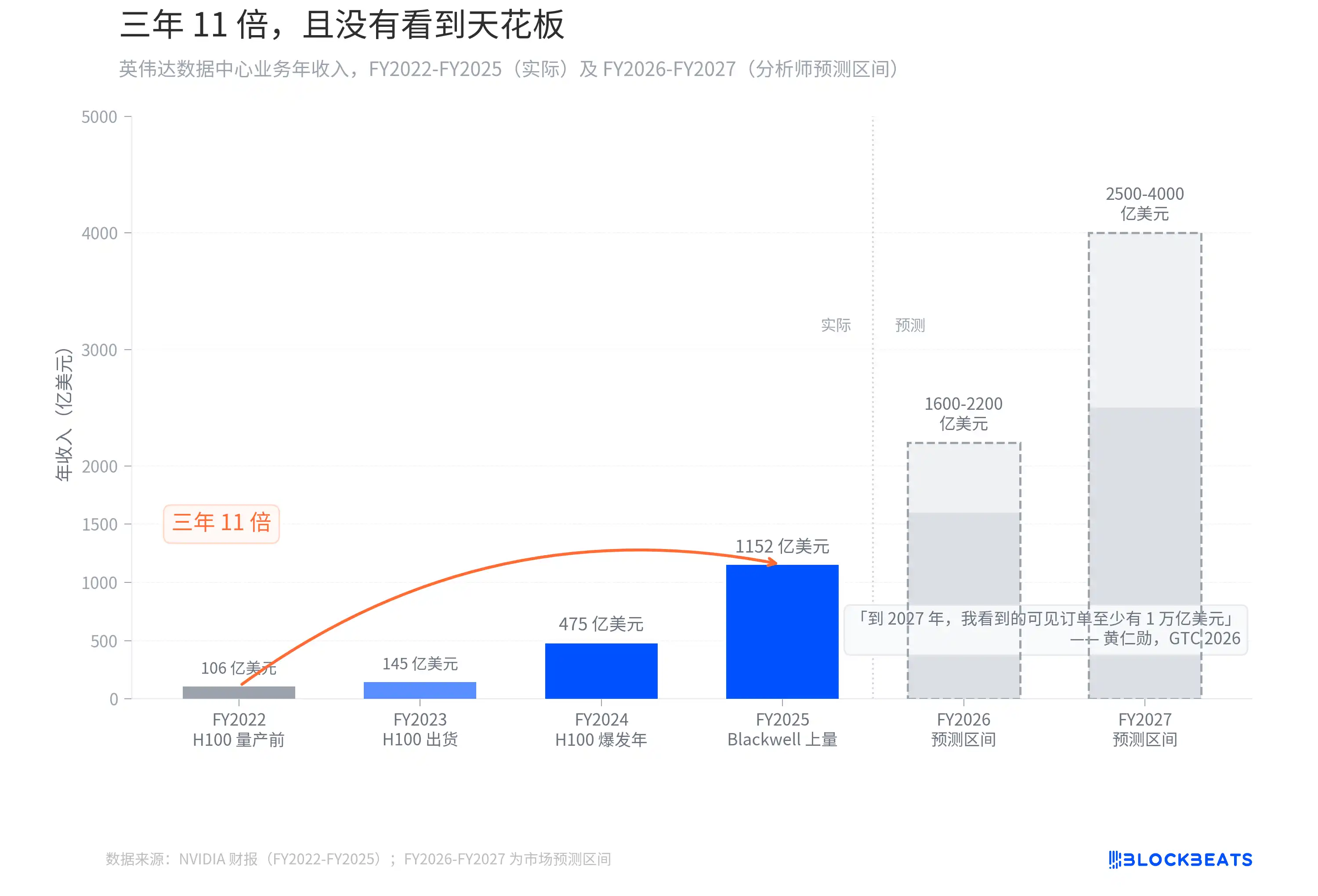
Then Jensen Huang said at GTC 2026: "By 2027, I see visible orders of at least one trillion dollars. In fact, our production capacity will not be enough. I am confident that computing demand will far exceed this number."
Last year at GTC, his prediction was that visible orders would be about 500 billion dollars through 2026. A year later, the number has doubled, with only a one-year extension of the time window. Analysts' revenue forecasts for FY2026-FY2027 range from 160 to 220 billion and 250 to 400 billion dollars respectively. Jensen Huang himself indicated that this number is not a ceiling, "computing demand will far exceed this number." On the day GTC ended, NVIDIA's stock price rose by 4.3%. The market clearly chose to believe him.
Every generation of GPU makes the previous generation look pathetic, and every round of price cuts makes the next round of capital expenditure seem justifiable. NVIDIA is standing at the sweetest position in this paradox.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








