DeepSeek V4 has finally been launched. This is a moment that has been awaited for nearly five months. The 1T parameter MoE main model + 285B parameter Flash version, along with the complete 1.6T Pro version, follows closely behind, fully open-sourced on GitHub under the Apache 2.0 license, with weights and deployment code released simultaneously.
As soon as the model was released, the capital market responded in three independent yet interlocking ways.
Different Reactions from the Capital Market
The A-share computing power chain surged almost across the board. Cambricon achieved 11 consecutive days of gains, rising 3.7% in a single day, with a cumulative monthly gain exceeding 60%. Haiguang Information hit a 10% trading limit, closing at +8.4%. SMIC A shares rose by 4.91%, while Hong Kong shares climbed by 8.81%. Hua Hong's Hong Kong shares reached a peak of +18%, closing at +12%. The Guotai ETF for Sci-tech chips attracted 2.4 billion yuan in a single day, reaching a historical high in scale.
The Hong Kong segment of large model companies showed a different response. Zhihui (02513.HK) dropped 8.07%, with a short-selling ratio of 9.9%. MiniMax (00100.HK) fell 7.40%, with a short-selling ratio soaring to 22.87%. The latter represents the highest single-day short-selling data in the Hong Kong AI sector in the past three months. Both companies are representatives of the Hong Kong AI listing wave expected in the second half of 2025, with their IPO prospectuses stating the core competitiveness as "self-developed foundational large models."
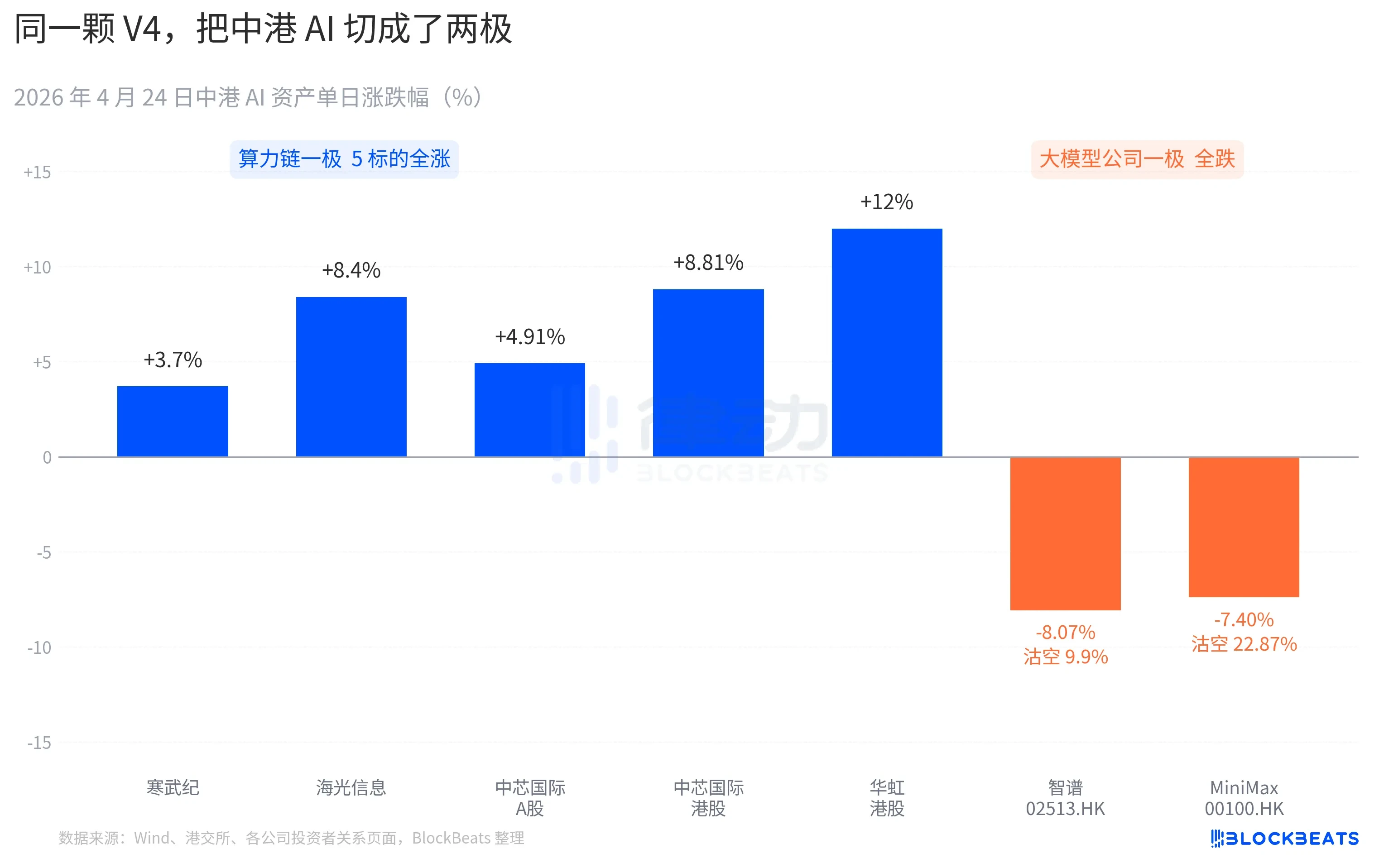
The reaction from the other side of the Pacific was similarly specific. Nvidia opened down 1.8% last night, at one point dropping to -2.6%, closing flat for the day. Bloomberg's market commentary compared this consolidation to the "DeepSeek moment" on January 27th. The difference was that the January event was marked by panic selling, evaporating $600 billion in market value in a single day. This time feels more like a repricing, moderate in scale but clear in direction. A new statement appeared in buy-side research notes: "China's AI inference demand is starting to decouple from North American AI inference demand."
Overlaying these three market segments provides the first judgment rendered by the market within 24 hours of V4's launch. After open-sourcing triumphed, money started to reposition; it was no longer the model itself that defined value, but rather which hardware the model runs on and which industrial chain it belongs to.
11 New Models in 30 Days, V4 Ignites the Open Source Camp
The timing of V4's release window itself is partly why this reaction was amplified.
Zooming out to the past 30 days. Between March 26 and April 24, at least 11 significantly influential large models were released or significantly updated globally, covering nearly all major players. Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Kimi K2.6 from Dark Side of the Moon, Alibaba Qwen3-Next, ByteDance Doubao 2.5 Pro, Tencent Hunyuan 3.0, Kimi K2.6 Plus, and finally DeepSeek V4 released in the early hours of April 23.
On average, a new model was unveiled every 2.7 days. This is a speed so rapid that even fund managers cannot finish reading the release notes. However, a review of the K-line for AI assets in Hong Kong and China over these 30 days reveals that one name left a lasting mark on the market. The GPT-5.5 on April 8 led Nvidia to rise 4.2% in a single day, peaking that day. Then there's DeepSeek V4 on April 23-24, driving the computing power chain in Hong Kong and China to surge consecutively.
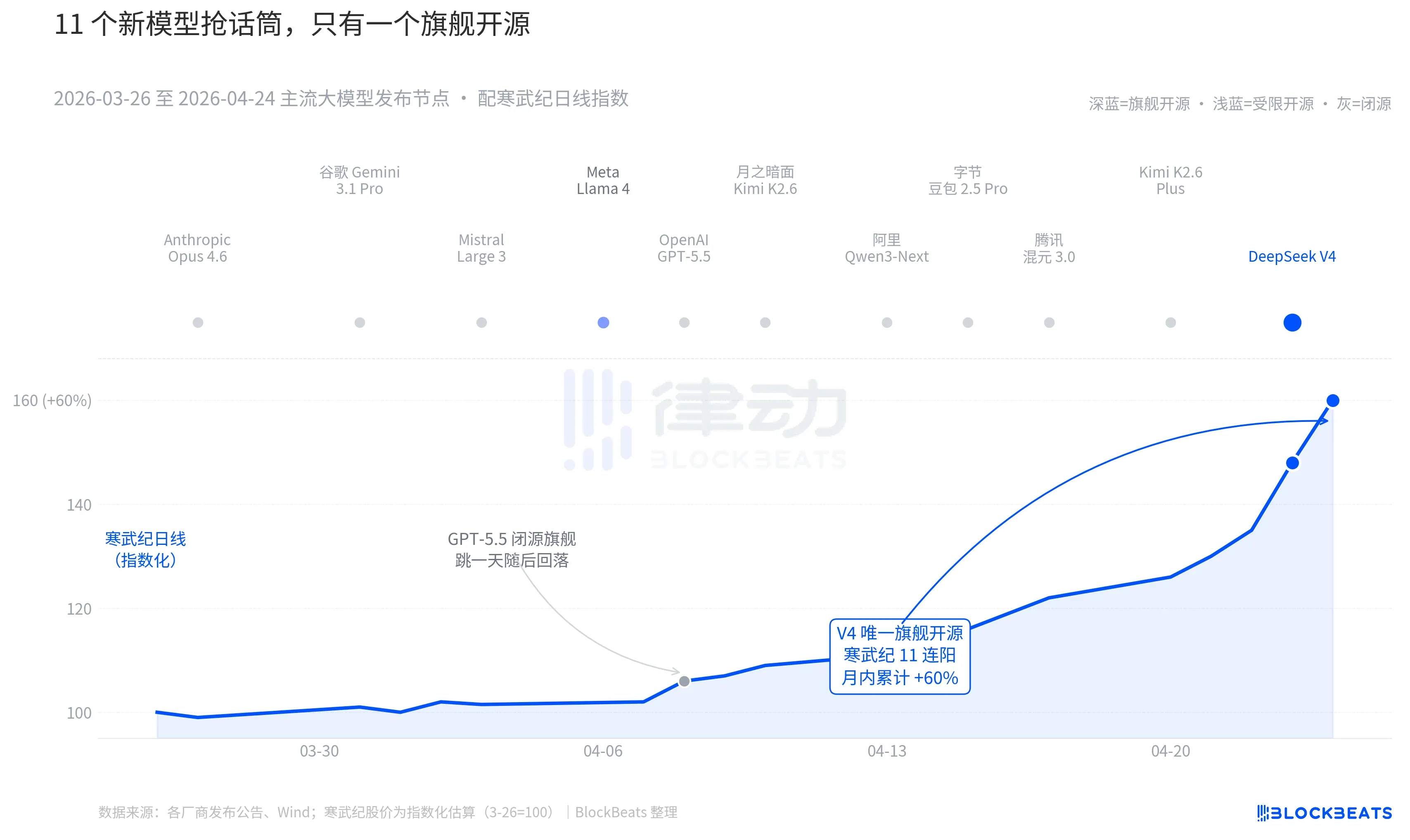
The difference lies not in the capabilities of the models themselves. The gap between these 11 models on the LMArena leaderboard rarely exceeds 50 points, positioning them within a narrow range of "the same tier." The difference stems from the combination of two factors.
The first factor is open-source. Among the top 10 models, only Llama 4 is open-source, but its weight protocol includes a long list of commercial restrictions, leading to lukewarm responses from the European and American developer communities; it fell out of the top ten on the third day after being listed on OpenRouter. V4's protocol is Apache 2.0, without barriers for weights, unrestricted commercial use, and synchronous release of inference code. This has become the first flagship open-source model in the past six months to put pressure on the closed-source camp in terms of performance, price, and openness simultaneously.
The second factor is timing. Against the backdrop of the continuous escalation from the closed-source camp, the narrative around open-source is being consistently squeezed. Opus 4.6 pulled SWE-Bench tasks to new highs, and GPT-5.5 set a low anchor price of $1.25 per million tokens. The debate over whether open-source can catch up with closed-source has persisted in Silicon Valley for two years. V4, with an estimated pre-activation activity of 90 million, pressed pause on this debate.
According to a domestic large fund manager during a roadshow, "Before V4, we discounted the valuation of open-source large models. After V4, this discount has begun to reverse."
DeepSeek Changed the Pricing Table of the Computing Power Supply Chain
In the V4 release notes, there is a line that has never appeared in any official document of Chinese large models: "Day 0 full-stack adaptation for Cambricon Siwei 590 and Huawei Ascend 950PR, deployment code synchronously open-sourced." To understand the significance of this line, it helps to connect three parallel dark lines that have unfolded over the past 12 months. These three dark lines belong to hardware, software, and Silicon Valley's reactions.
The first dark line is on the chip side. Huawei's Ascend 950PR will officially start mass production in December 2025, with FP4 computing power at 1.56 PFLOPS and HBM capacity at 112GB, marking the first time domestically produced AI chips meet Nvidia's B series on hard indicators. In tasks requiring 1T parameters like V4 MoE inference, single-card throughput improves 2.87 times compared to H20. The supporting CANN 8.0 software stack optimizes the LLM inference framework down to the operator level; the Benchmark published by DeepSeek shows that V4 has 35% lower end-to-end inference latency on Ascend super nodes (8 cards 950PR) compared to similar-scale H100 clusters. The data for Cambricon Siwei 590 is even more aggressive, with single-chip FP8 computing power matching H100, priced at less than half.
The second dark line is on the software side. The vLLM mainline merged the Cambricon MLU backend PR on April 22, marking the first time the open-source inference framework has native support for non-Nvidia domestic GPUs. Haiguang Information's DCU follows another route through the ROCm ecosystem but is capable of fully running V4's MoE routing layer. This means that V4's deployment is no longer limited to "only able to run on a specific domestic card" but can now "choose between multiple domestic cards." The dependency on single-point suppliers has been broken, marking a key turning point for production.
The third dark line comes from Silicon Valley. On April 15, Jensen Huang was questioned by analysts about the progress of China's domestic computing power during a press conference at TSMC; his original words were cold yet specific: "If they can really free LLM from CUDA, it will be a disaster for us." Nine days later, DeepSeek provided an answer with a single line in the Day 0 announcement.
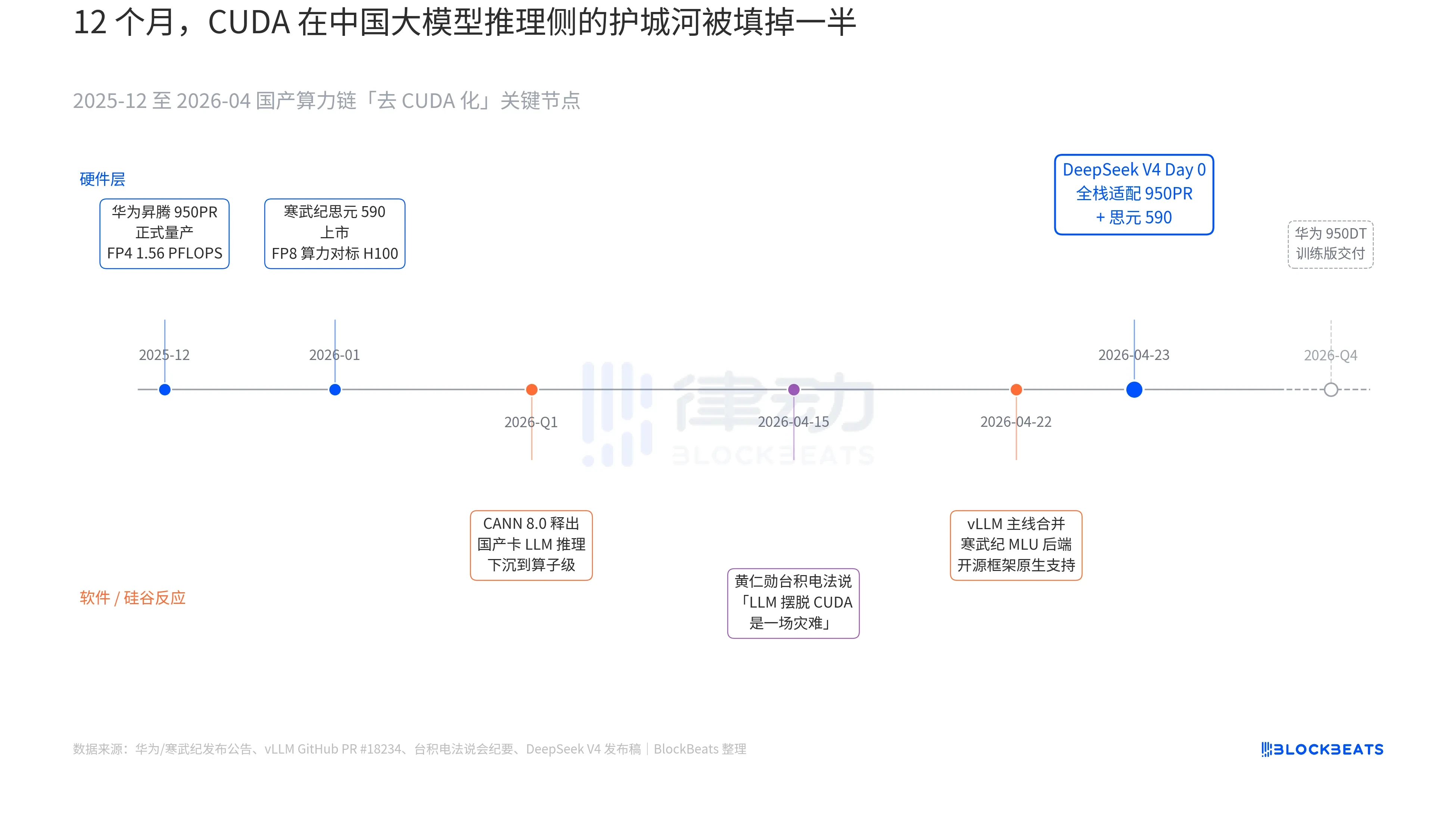
The term "domestic substitution" has become so overused in the past three years that it has lost its meaning. However, after the morning of April 24, this became the first time there were concrete data points for capital markets to price this matter. Single-card throughput, end-to-end inference latency, inference costs, and commercially usable deployment code quietly pushed this long-winded word war past the threshold of production.
The logic behind Cambricon's 11 consecutive days of gains lies here. It is no longer just a "domestic GPU concept stock" but a "DeepSeek V4 inference infrastructure supplier." The same logic can also explain the 12% rise in Hua Hong's Hong Kong shares, which manufactures the 7nm equivalent process of the 950PR. Each V4 token running on domestically produced Ascend chips means that capacity originally set to flow to Nvidia and TSMC has been partially retained in the Pearl River Delta.
The next step has already been paved. In Huawei's roadmap, the 950DT (training version) is planned for delivery in the fourth quarter of 2026, with the corresponding goal being "full-stack training of V5 or models of equivalent scale on a 10,000-card cluster." If this route can succeed, the moat of CUDA in the training side of Chinese large models will downgrade from "necessary" to "optional."
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。




