DeepSeek回来了,它在OpenAI发布GPT-5.5几个小时后出现。巧合吗?也许。但是如果你是一家中国AI实验室,而美国政府过去三年一直试图通过芯片出口禁令来减缓你的发展,那么你的时机感就会变得相当敏锐。
这家总部位于杭州的实验室今天发布了DeepSeek-V4-Pro和DeepSeek-V4-Flash的预览版本,二者均为开放权重,且具有一百万个token的上下文窗口。这意味着你基本上可以处理大约《指环王》三部曲大小的上下文,直到模型崩溃为止。两者的定价远低于西方任何可比产品,并且对于能够本地运行的用户是免费的。
DeepSeek上一次重大干扰——2025年1月的R1——在一天内令英伟达的市值蒸发6000亿美元,因为投资者们质疑美国公司是否真的需要如此巨大的投资才能产生小型中国实验室以极低成本实现的结果。V4是一种不同类型的举动:更安静,更技术驱动,更专注于对任何实际使用AI进行构建的人的效率。
两种模型,非常不同的工作
在这两个新模型中,DeepSeek的V4-Pro是主要版本,拥有1.6万亿个参数。为了更好地理解,参数是模型用来存储知识和识别模式的内部“设置”或“脑细胞”——参数越多,模型理论上能够承载的信息就越复杂。这使其成为当前LLM市场上最大的开源模型。这个规模听起来可能荒谬,直到你了解到它在每次推理过程中仅激活49亿个参数。
这是DeepSeek自V3以来改进的专家混合机制:完整模型在这里,但只有与特定请求相关的部分会被唤醒。更多的知识,相同的计算费用。
“DeepSeek-V4-Pro-Max,DeepSeek-V4-Pro的最大推理努力模式,显著提升了开源模型的知识能力,坚定地确立了自己作为今天最好的开源模型,”DeepSeek在模型的官方卡片上写道。“它在编码基准测试中实现了顶级表现,在推理和代理任务上显著缩小了与领先闭源模型的差距。”
V4-Flash是实用型:总共有2840亿个参数,130亿个活跃参数。它设计得更快、更便宜,并且根据DeepSeek自己的基准测试,“在给予更大的思考预算时,达到了与Pro版本相当的推理性能。”
两者都支持一百万个token的上下文。这大约是750,000个单词——大致相当于整个“指环王”三部曲加一些变动。而且这是标准功能,而不是高级层。
Deepseek(不太)秘密的调味品:在规模上使注意力不再可怕
这是给技术迷或对驱动模型的魔法感兴趣的人的技术部分。Deepseek并不隐藏其秘密,所有内容都是免费的——完整论文可在Github上获得。
标准AI注意力——使模型理解单词之间关系的机制——有一个严峻的可扩展性问题。每当你将上下文长度加倍时,计算成本大约会四倍增加。因此,在一百万个token上运行模型的成本不仅是500,000个token的两倍,而是四倍。这就是为什么长上下文在历史上一直是实验室添加的一个复选框,然后悄悄地通过速率限制来限制。
DeepSeek发明了两种新类型的注意力来解决这个问题。第一种,压缩稀疏注意力,分两步工作。它首先将一组token(例如每4个token)压缩为一个条目。接着, instead of attending to all of those compressed entries, it uses a "Lightning Indexer" to pick only the most relevant results for any given query. 你的模型从关注一百万个token变为关注更小的一组最重要的块,就像一个图书管理员不需要阅读每一本书,但知道确切需要检查哪个书架。
第二种,重度压缩注意力,更具攻击性。它将每128个token压缩为一个条目——没有稀疏选择,只有残酷的压缩。你会失去精细的细节,但你会得到一个极便宜的全局视图。这两种注意力类型交替运行,因此模型同时获得细节和概览。
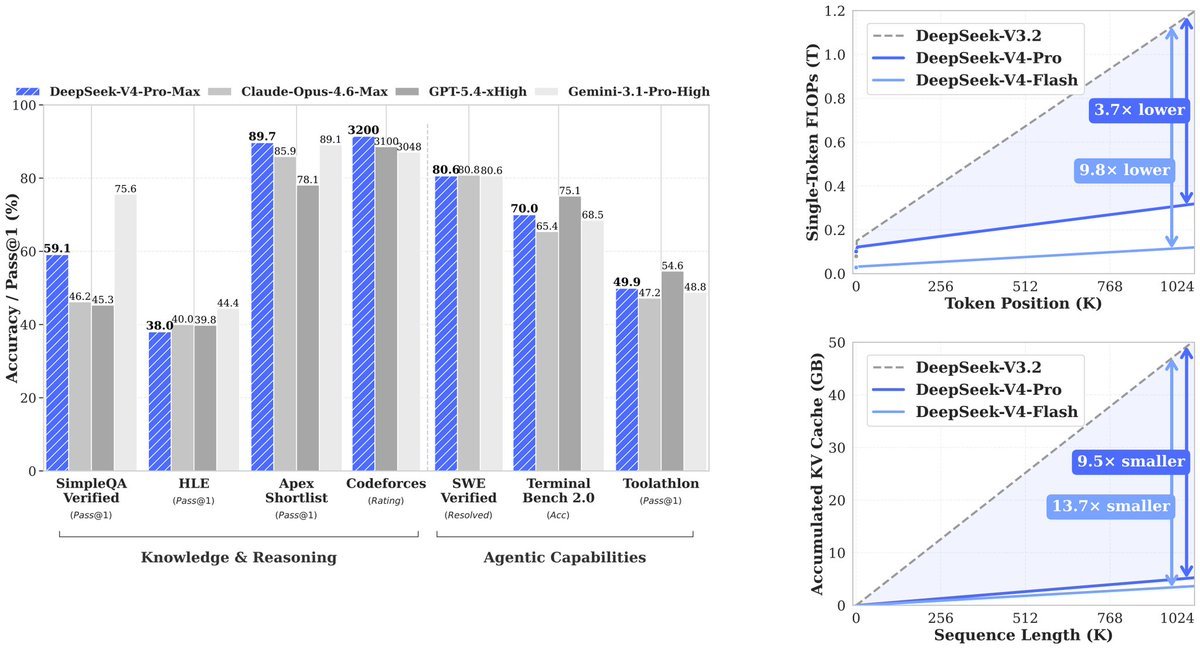
技术论文中的结果:在一百万个token上,V4-Pro使用的计算量为其前身(V3.2)的27%。KV缓存——模型需要跟踪上下文的内存——降至V3.2的10%。V4-Flash进一步推动:使用10%的计算,7%的内存。
这使得Deepseek能够提供比竞争对手更便宜的每token价格,同时提供可比的结果。用美元算一算:GPT-5.5昨天发布,输入每百万token需花费5美元,输出每百万token为30美元,GPT-5.5 Pro每百万输入token为30美元,每百万输出token为180美元。
Deepseek V4-Pro的输入费用为1.74美元,输出费用为3.48美元。V4-Flash的输入费用为0.14美元,输出费用为0.28美元。Cline的首席执行官Saoud Rizwan指出,如果Uber使用DeepSeek而不是Claude,它的2026年AI预算(据说足够使用四个月)将持续七年。
基准测试
DeepSeek在其技术报告中做了一件不寻常的事情:它发布了差距。大多数模型发布会精挑细选在其胜利的基准测试。DeepSeek进行了全面比较,对比GPT-5.4和Gemini-3.1-Pro,发现V4-Pro的推理落后于这些模型约三到六个月,并且仍然发布了该结果。
V4-Pro-Max在哪里胜出:Codeforces,竞争编程基准,像人类国际象棋一样评级。V4-Pro得分3206,排名在实际人类参与者中约为第23位。在Apex Shortlist,一个经过筛选的困难数学和STEM问题集合中,它得分通过率为90.2%,而Opus 4.6为85.9%,GPT-5.4为78.1%。在SWE-Verified上,它得分80.6%——与Claude Opus 4.6持平。
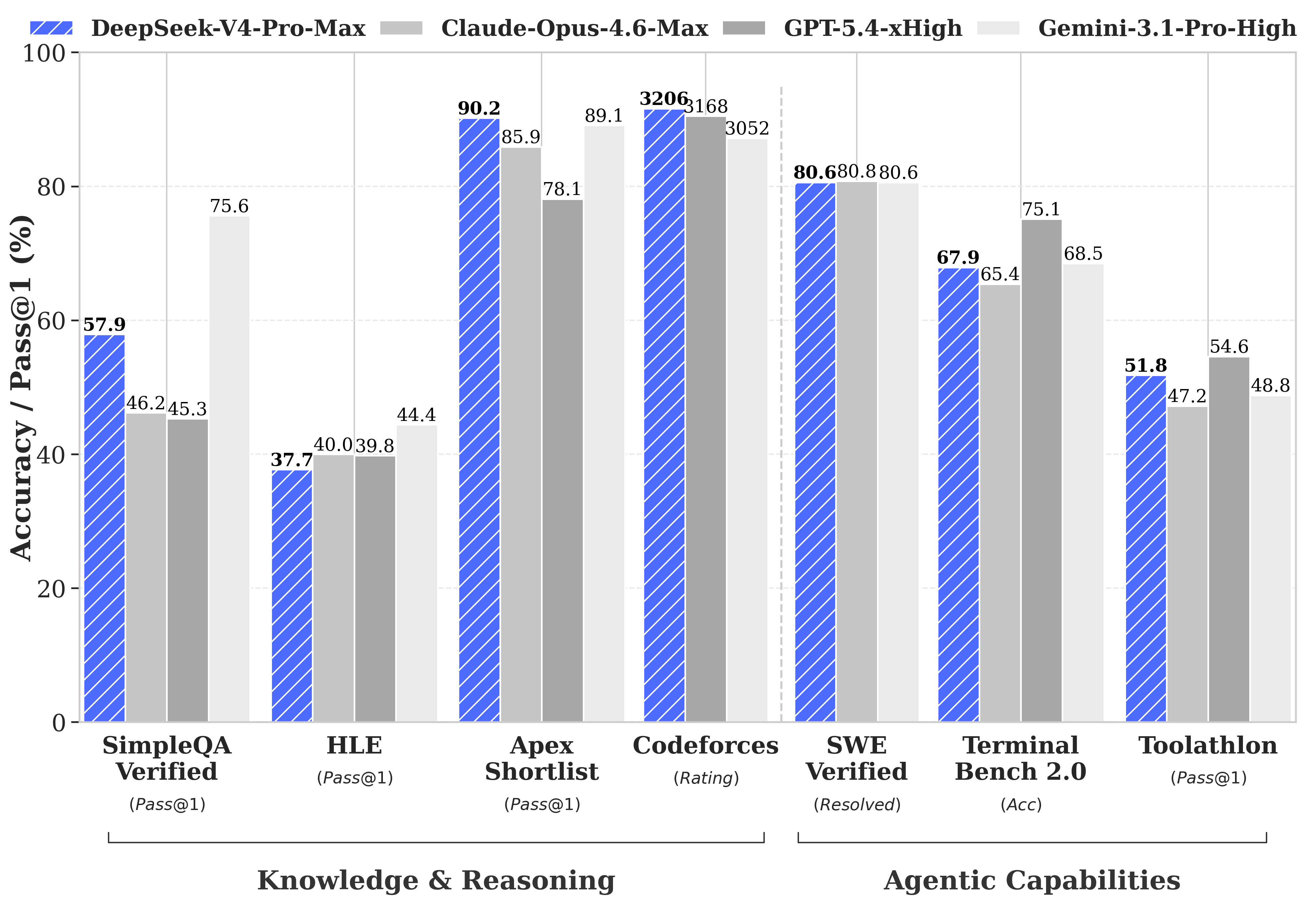
在哪些方面落后:多任务基准MMLU-Pro(Gemini-3.1-Pro为91.0%,V4-Pro为87.5%)、专家知识基准GPQA Diamond(Gemini为94.3,V4-Pro为90.1),以及人类最后的考试,一个研究生级基准,其中Gemini-3.1-Pro的44.4%仍然超过V4-Pro的37.7%。
具体来说,在长上下文方面,V4-Pro领先于开源模型,并在CorpusQA基准测试中击败Gemini-3.1-Pro(这是一个模拟真实文档分析的一百万token测试),但在MRCR上不敌Claude Opus 4.6——这是一个衡量模型在长草堆中检索特定难题的能力的测试。
旨在运行代理,而不仅仅是回答问题
代理内容是这次发布对实际推出产品的开发者而言的有趣之处。
V4-Pro可以在Claude Code、OpenCode和其他AI编码工具中运行。根据DeepSeek对85名开发者的内部调查,使用V4-Pro作为他们的主要编码代理,52%的人表示它准备成为他们的默认模型,39%倾向于同意,而不到9%的人表示不赞成。内部员工表示,它在代理编码任务上超越了Claude Sonnet,并接近Claude Opus 4.5。
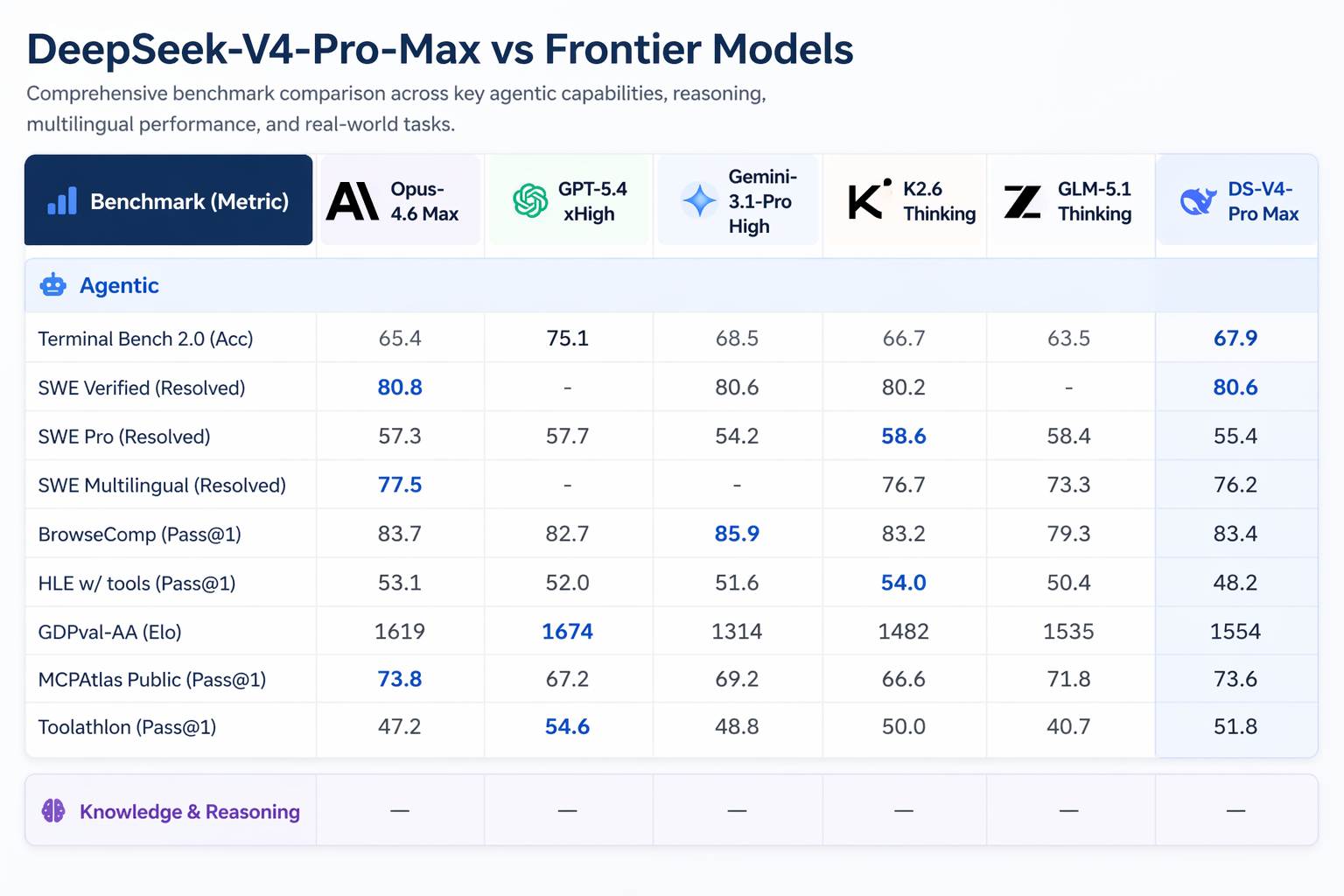
人工分析(Artificial Analysis)对AI模型在实际任务中的独立评估排名V4-Pro在所有开源模型中第一,针对GDPval-AA一个测试经济有价值的知识工作,涵盖金融、法律和研究任务,以Elo评分。V4-Pro-Max得分1554,领先GLM-5.1(1535)和MiniMax的M2.7(1514)。作为参考,Claude Opus 4.6在相同基准中的得分为1619——仍然领先,但差距在缩小。
Deepseek的V4还引入了叫做“交错思维”的概念。在以前的模型中,如果你正在运行一个进行多次工具调用的代理——例如,它先搜索网络,然后运行一些代码,然后再次搜索——模型的推理上下文在每轮间会被刷新。每一步,模型都必须从头开始重建其心智模型。V4保留了工具调用之间的完整思维链条,因此一个20步的代理工作流程不会在中途失去记忆。这对于任何运行复杂自动化流程的人来说,重要性超过了听起来平常的程度。
Deepseek与美国-中国AI战争
自2022年以来,美国一直限制对中国的高端英伟达芯片出口。官方目标是减缓中国的AI发展,但芯片禁令并没有阻止DeepSeek,反而使他们发明了更高效的架构,并建立了国内硬件供应。
DeepSeek的V4并不是在真空中发布的——最近AI领域的活动频繁:Anthropic在4月16日发布了Claude Opus 4.7——一个Decrypt测试发现其在编码和推理方面表现出色的模型,并且token使用量显著高。就在前一天,Anthropic还在Claude Mythos上发力,这是一款他们声称无法公开发布的网络安全模型,因为它在自主网络攻击方面表现得太出色。
小米在4月22日发布了MiMo V2.5 Pro,全面支持多模态——图像、音频、视频。每百万个token的输入成本为1美元,输出为3美元。它在大多数编码基准测试中与Opus 4.6相当。三个月前,没有人谈论小米是一个前沿AI公司。现在,它发布竞争模型的速度比大多数西方实验室更快。
OpenAI的GPT-5.5昨天发布,其Pro版本输出每百万token成本高达180美元。它在Terminal Bench 2.0(测试复杂命令行代理工作流程)上击败了V4-Pro(82.7%对70.0%),但对于等效任务,它的成本远高于V4-Pro。同一天,腾讯发布了Hy3,另一款
这对你意味着什么
因此,随着如此多的新模型可用,开发者实际上问的问题是:何时提升到高级版本是值得的?
对于企业来说,数学可能已经改变。一个在开源基准测试中领先、每百万输入token仅需1.74美元的模型意味着大规模的文档处理、法律审查或代码生成流程,六个月前这些流程的成本都很高,现在则便宜得多。一百万token的上下文意味着你可以在一次请求中提供整个代码库或法规文件,而不是在多个调用中将其分割。
此外,其开源特性意味着它不仅可以在本地硬件上免费运行,而且可以基于公司的需求和用例进行定制和改进。
对于开发者和独立创建者来说,V4-Flash是关注的重点。以每百万token输入0.14美元,输出0.28美元的价格,它比一年前被认为是预算选项的模型更便宜——并且能够处理大多数Pro版本所能处理的任务。DeepSeek现有的deepseek-chat和deepseek-reasoner端点分别在非思考和思考模式下已经路由到V4-Flash,因此如果你在API上,你已经在使用它。
目前这些模型仅支持文本。DeepSeek表示,他们正在研发多模态功能,这意味着从小米到OpenAI的其他大型实验室仍然具备这个优势。这两个模型都采用MIT许可证,并已在Hugging Face上可用。旧的deepseek-chat和deepseek-reasoner端点将在2026年7月24日退役。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。




