特别感谢 Devansh Mehta、Davide Crapis 和 Julian Zawistowski 的反馈和审阅,Tina Zhen、Shaw Walters 以及其他人的讨论。
如果你问人们他们喜欢民主结构的什么,无论是政府、工作场所还是基于区块链的 DAO,你常常会听到相同的论点:它们避免了权力的集中,给用户提供了强有力的保障,因为没有一个人可以随意完全改变系统的方向,并且通过汇集许多人的观点和智慧,它们能够做出更高质量的决策。
如果你问人们他们对民主结构的不满,他们通常会给出相同的抱怨:普通选民并不复杂,因为每个选民只有很小的机会影响结果,少数选民在决策中投入高质量的思考,通常会出现低参与度(使系统容易受到攻击)或事实上的集中化,因为每个人都只是默认信任并复制某些影响者的观点。
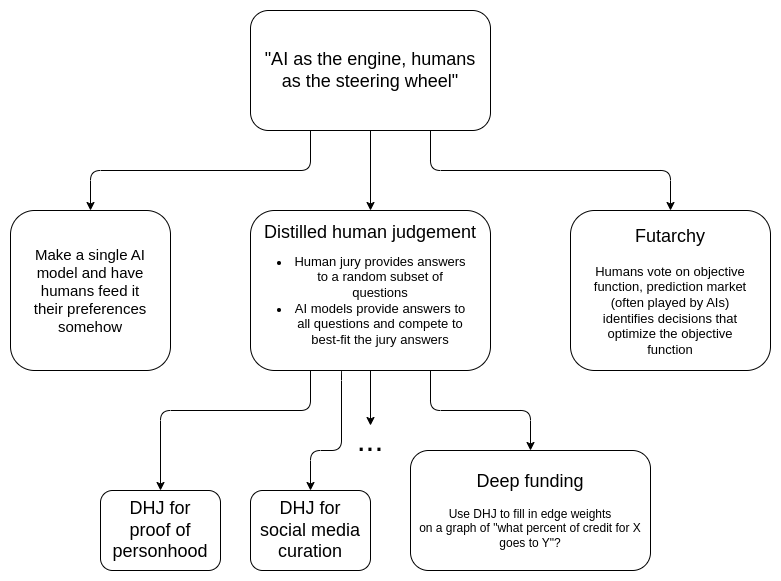
这篇文章的目标是探索一个范式,也许可以利用 AI 为我们带来民主结构的好处而没有缺点。“AI 作为引擎,人类作为方向盘”。人类只向系统提供少量信息,也许只有几百个比特,但每一个比特都是经过深思熟虑的高质量比特。AI 将这些数据视为“目标函数”,并不知疲倦地做出大量决策,尽力满足这些目标。特别是,这篇文章将探讨一个有趣的问题:我们能否在不将单一 AI 置于中心的情况下做到这一点,而是依赖于任何 AI(或人类-AI 混合体)都可以自由参与的竞争性开放市场?
目录
为什么不让单一 AI 负责?
将人类偏好插入基于 AI 的机制的最简单方法是创建一个单一的 AI 模型,并让人类以某种方式将他们的偏好输入其中。有简单的方法可以做到这一点:你可以将包含人们指令列表的文本文件放入系统提示中。然后,你使用许多“代理 AI 框架”之一,赋予 AI 访问互联网的能力,交给它你组织的资产和社交媒体账户的钥匙,这样就完成了。
经过几次迭代,这可能会对许多用例足够好,我完全预期在不久的将来,我们会看到许多结构涉及 AI 阅读一组人给出的指令(甚至实时读取群聊)并据此采取行动。
这种结构在作为长期机构的治理机制时并不理想。长期机构所需的一个有价值的特性是可信中立性。在我介绍这个概念的文章中,我列出了四个对可信中立性有价值的特性:
- 不要将特定的人或特定的结果写入机制
- 开源和公开可验证的执行
- 保持简单
- 不要过于频繁地更改
一个 LLM(或 AI 代理)满足 0/4。该模型不可避免地在其训练过程中编码了大量特定人和结果的偏好。有时这导致 AI 在意想不到的方向上有偏好,例如,参见这项最近的研究,该研究表明主要 LLM 对巴基斯坦的生命价值远高于对美国生命的价值 (!!)。它可以是开放权重,但这远非开源;我们真的不知道模型深处隐藏着什么恶魔。这与简单相反:一个 LLM 的 Kolmogorov 复杂性在数百亿比特左右,约等于所有美国法律(联邦 + 州 + 地方)加起来的复杂性。而且由于 AI 发展迅速,你必须每三个月就更改一次。
因此,我倾向于探索的一种替代方法是让一个简单的机制成为游戏规则,让 AI 成为参与者。这与市场如此有效的洞察相同:规则是一个相对愚蠢的财产权系统,边缘案例由一个缓慢积累和调整先例的法院系统决定,所有的智慧来自于在“边缘”操作的企业家。
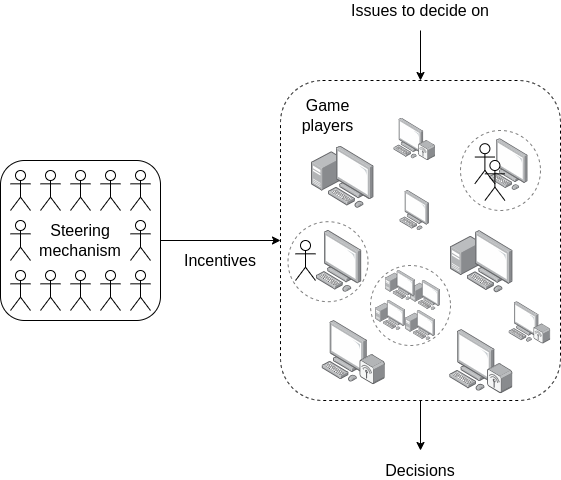
个体“游戏参与者”可以是 LLM、相互交互的 LLM 群体、调用各种互联网服务的 LLM、各种 AI + 人类组合以及许多其他构造;作为机制设计者,你不需要知道。理想的目标是拥有一个作为自动机运作的机制——如果机制的目标是选择资助对象,那么它应该尽可能像比特币或以太坊的区块奖励那样感觉。
这种方法的好处包括:
- 避免将任何单一模型确立为机制;相反,你会得到一个开放市场,参与者和架构各不相同,且都有各自不同的偏见。开放模型、封闭模型、代理群体、人类 + AI 混合体、半机械人、无限猴子等都是公平的游戏;机制不加以歧视。
- 机制是开源的。虽然参与者不是,但游戏是——这是一种已经相对被理解的模式(例如,政党和市场都是这样运作的)。
- 机制是简单的,因此机制设计者在设计中编码自己偏见的途径相对较少。
- 机制不变,即使底层参与者的架构需要在此后每三个月重新设计,直到奇点的到来。
方向机制的目标是提供参与者潜在目标的忠实表示。它只需要提供少量信息,但这些信息应该是高质量的。
你可以将机制视为利用提出答案和验证答案之间的不对称性。这类似于数独难以解决,但验证解决方案是否正确却很简单。你 (i) 创建一个开放市场的参与者作为“解答者”,然后 (ii) 维护一个由人类运行的机制,执行验证已提出解决方案的简单任务。
未来治理
未来治理最初由罗宾·汉森提出,作为“投票价值,但下注信念”。一种投票机制选择一组目标(可以是任何东西,但需要可测量),这些目标被组合成一个指标 M。当你需要做出决策时(为了简单起见,假设是 YES/NO),你建立条件市场:你询问人们下注 (i) YES 或 NO 将被选择的可能性,(ii) 如果选择 YES,M 的值是多少,否则为零,(iii) 如果选择 NO,M 的值是多少,否则为零。根据这三个变量,你可以判断市场认为 YES 还是 NO 对 M 的价值更有利。
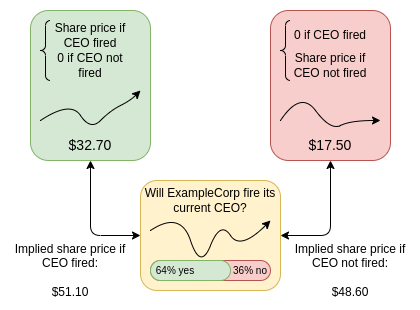
“公司股票的价格”(或者对于加密货币来说,是一个代币)是最常被引用的指标,因为它易于理解和测量,但该机制可以支持多种指标:每月活跃用户、某些群体的中位自我报告幸福感、某种可量化的去中心化程度等。
未来治理最初是在 AI 时代之前发明的。然而,未来治理非常自然地适应了前一节中描述的“复杂解答者,简单验证者”范式,而未来治理中的交易者也可以是 AI(或人类+AI 组合)。 “解答者”(预测市场交易者)的角色是确定每个提议计划将如何影响未来某个指标的价值。这是困难的。如果他们正确,解答者就能赚钱;如果错误,则会亏钱。验证者(对指标进行投票的人,如果他们注意到指标被“操控”或以其他方式变得过时,则调整指标,并在未来某个时间确定指标的实际值)只需回答更简单的问题“现在指标的值是多少?”
提炼的人类判断
提炼的人类判断是一类机制,其工作方式如下。有非常大量(想想:100 万)需要回答的问题。自然的例子包括:
- 这个列表中的每个人在某个项目或任务中应得多少信用?
- 这些评论中哪些违反了社交媒体平台(或子社区)的规则?
- 这些给定的以太坊地址中哪些代表一个真实且独特的人?
- 这些物理对象中哪些对其环境的美学产生积极或消极的影响?
你有一个陪审团可以回答这些问题,尽管每个答案需要花费大量精力。你只要求陪审团回答少量问题(例如,如果总列表有 100 万项,陪审团可能只对其中 100 项提供答案)。你甚至可以向陪审团提出间接问题:与其问“爱丽丝应得多少总信用的百分比?”,不如问“爱丽丝和鲍勃谁更值得信用,多少倍?”在设计陪审团机制时,你可以重用现实世界中经过时间考验的机制,如拨款委员会、法院(确定判决的价值)、评估等,当然,陪审团参与者本身也可以使用新兴的 AI 研究工具来帮助他们得出答案。
然后,你允许任何人提交一整套问题的数值响应列表(例如,提供对整个列表中每个参与者应得多少信用的估计)。鼓励参与者使用 AI 来做到这一点,尽管他们可以使用任何技术:AI、人类-AI 混合体、可以访问互联网搜索并能够自主雇佣其他人类或 AI 工作者的 AI、网络增强的猴子等。
一旦完整列表提供者和陪审团都提交了他们的答案,完整列表将与陪审团的答案进行核对,并取与陪审团答案最兼容的完整列表的某种组合作为最终答案。
提炼的人类判断机制与未来治理不同,但有一些重要的相似之处:
- 在 未来治理 中,“解答者”正在进行 预测,而他们的预测所依据的“真实数据”是 由陪审团运行的输出指标值的神谕。
- 在 提炼的人类判断 中,“解答者”提供 对大量问题的答案,而他们的预测所依据的“真实数据”是 由陪审团提供的对这些问题小子集的高质量答案。
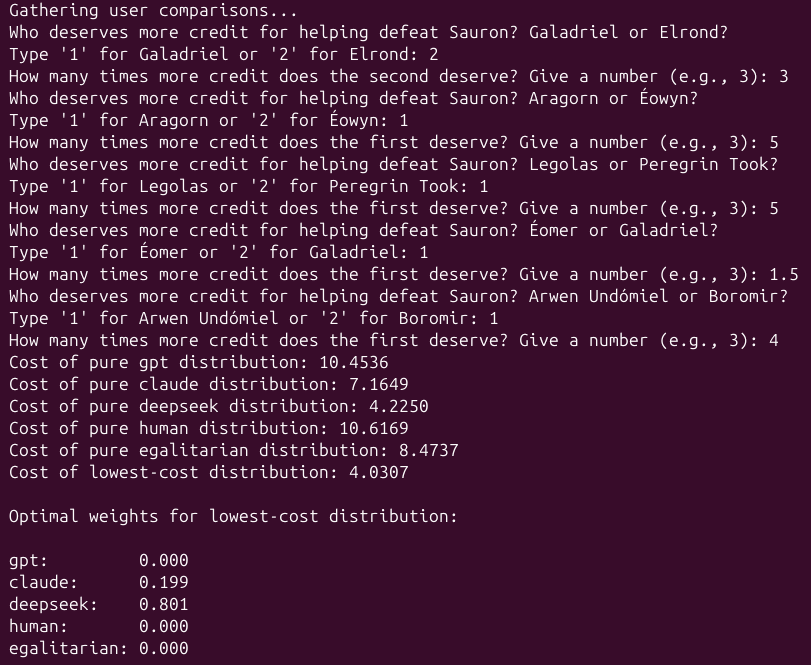
信用分配的提炼人类判断的玩具示例,见 python代码在这里. 该脚本要求你成为陪审团,并包含一些预先包含在代码中的 AI 生成(和人类生成)的完整列表。该机制识别出与陪审团答案最匹配的完整列表的线性组合。在这种情况下,获胜组合是 0.199 * Claude 的答案 + 0.801 * Deepseek 的答案;这个组合比任何单一模型更好地匹配陪审团答案。这些系数也将是给予提交者的奖励。_
在这个“击败索伦”的示例中,“人类作为方向盘”的方面体现在两个地方。首先,在每个单独问题上应用了高质量的人类判断,尽管这仍然利用陪审团作为“技术官僚”来评估表现。其次,隐含的投票机制决定了“击败索伦”是否是正确的目标(与试图与他达成妥协,或向他提供某条重要河流以东的所有领土作为和平的让步相对)。还有其他提炼的人类判断用例,其中陪审团的任务更直接地与价值相关:例如,想象一个去中心化的社交媒体平台(或子社区),陪审团的工作是将随机选择的论坛帖子标记为遵循或不遵循社区规则。
在提炼的人类判断范式中有一些开放变量:
- 你如何进行抽样?完整列表提交者的角色是提供大量答案;陪审团的角色是提供高质量答案。我们需要选择陪审团成员,并为陪审团选择问题,以便模型匹配陪审团答案的能力能够最大程度地指示其整体表现。一些考虑因素包括:
- 专业知识与偏见的权衡:熟练的陪审团成员通常在其专业领域内具有专长,因此让他们选择评估内容可以获得更高质量的输入。另一方面,过多的选择可能导致偏见(陪审团偏爱与他们有联系的人的内容),或抽样的弱点(某些内容系统性地未被评估)。
- 反古德哈特法则:会有内容试图“游戏”AI机制,例如,贡献者生成大量看起来令人印象深刻但无用的代码。其含义是陪审团可以检测到这一点,但静态AI模型除非努力尝试,否则无法做到。捕捉这种行为的一种可能方法是添加一个挑战机制,个人可以标记此类尝试,确保陪审团对其进行评判(从而激励AI开发者确保正确捕捉这些行为)。如果陪审团同意标记者的观点,标记者将获得奖励;如果陪审团不同意,则需支付罚款。
- 你使用什么评分函数?当前深度资金试点中使用的一个想法是询问陪审团“ A或B更值得获得更多的信用,多少更多?”评分函数为
score(x) = sum((log(x[B]) - log(x[A]) - log(juror_ratio)) ** 2 for (A, B, juror_ratio) in jury_answers):也就是说,对于每个陪审团答案,它询问完整列表中的比例与陪审团提供的比例相差多远,并添加一个与距离的平方成比例的惩罚(在对数空间中)。这表明评分函数有丰富的设计空间,评分函数的选择与向陪审团提出的问题的选择相关。 - 你如何奖励完整列表提交者?理想情况下,你希望经常给予多个参与者非零奖励,以避免机制的垄断,但你也希望满足一个属性,即一个参与者不能通过多次提交相同(或稍微修改过的)答案集来增加他们的奖励。一种有前景的方法是直接计算与陪审团答案最匹配的完整列表的线性组合(系数为非负且总和为1),并使用这些相同的系数来分配奖励。也可能还有其他方法。
总体而言,目标是采用已知有效且最小化偏见并经受住时间考验的人类判断机制(例如,想想法院系统的对抗结构如何包括两个信息丰富但有偏见的争议方,以及一个信息较少但可能没有偏见的法官),并使用开放市场的AI作为这些机制的合理高保真度和非常低成本的预测器(这类似于“蒸馏”大型语言模型的工作原理)。
深度资金
深度资金是将提炼的人类判断应用于填充表示“X的信用百分比属于Y”的图中边的权重的问题。
通过一个示例直接展示这一点是最简单的:
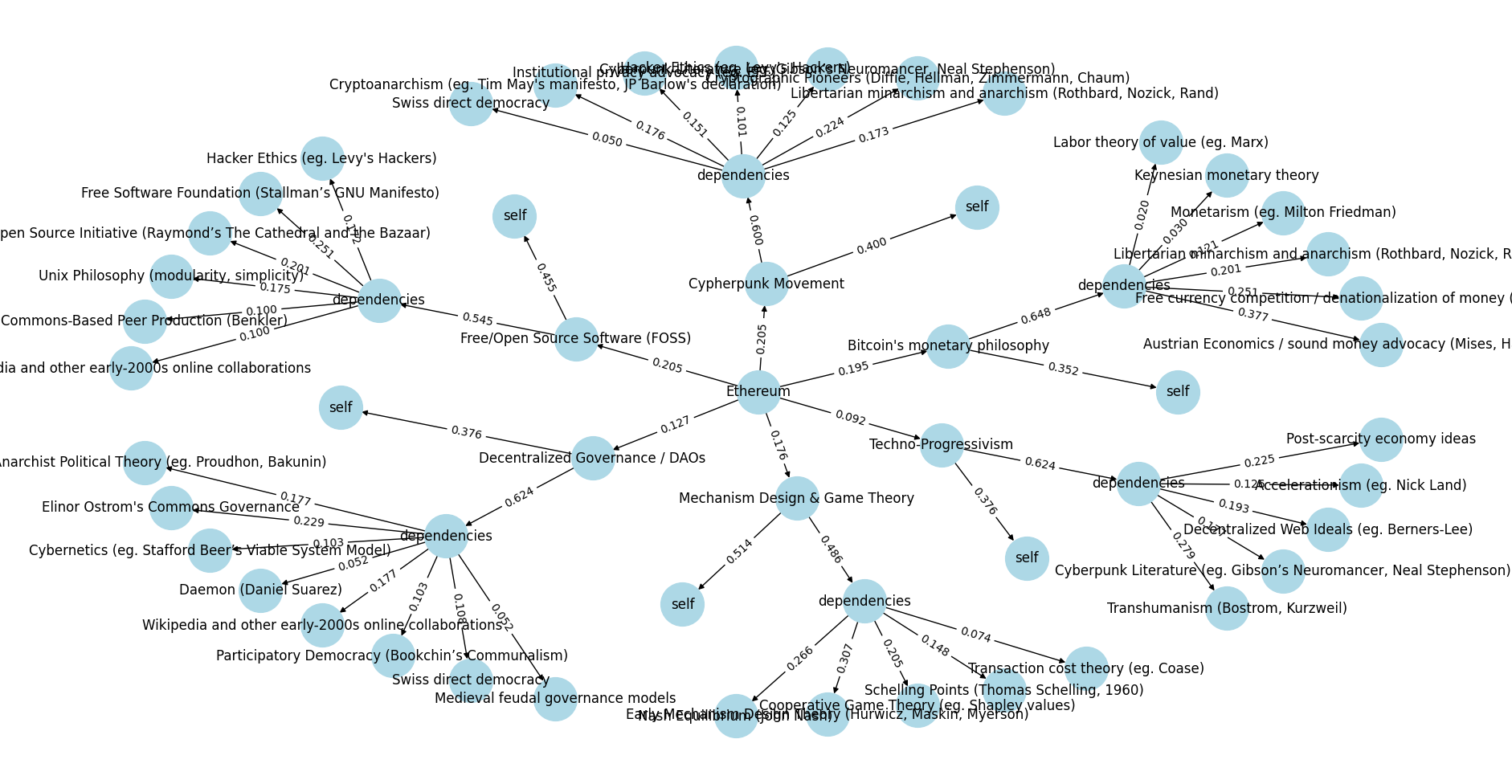
两级深度资金示例的输出:以太坊的意识形态起源。请参见 python代码在这里。
在这里,目标是分配导致以太坊的哲学贡献的信用。让我们看一个例子:
- 这里展示的模拟深度资金轮次将20.5%的信用分配给了密码朋克运动,9.2%分配给了技术进步主义。
- 在每个这些节点内,你会问这个问题:它在多大程度上是原创贡献(因此值得为其本身获得信用),在多大程度上是其他上游影响的重组?对于密码朋克运动来说,它是40%的新贡献和60%的依赖。
- 然后你可以查看这些节点上游的影响:自由意志主义的极简主义和无政府主义为密码朋克运动获得了17.3%的信用,但瑞士的直接民主仅获得5%。
- 但请注意,自由意志主义的极简主义和无政府主义也激发了比特币的货币哲学,因此它有两条路径影响以太坊的哲学。
- 要计算自由意志主义的极简主义和无政府主义对以太坊的总贡献份额,你需要沿着每条路径乘以边的权重,然后将路径相加:
0.205 * 0.6 * 0.173 + 0.195 * 0.648 * 0.201 ~= 0.0466。因此,如果你必须捐赠100美元来奖励所有对激励以太坊的哲学做出贡献的人,根据这个模拟深度资金轮,自由意志主义的极简主义者和无政府主义者将获得4.66美元。
这种方法旨在适用于在先前工作基础上构建的领域,并且这种结构高度可读。学术界(想想:引用图)和开源软件(想想:库依赖和分叉)是两个自然的例子。
一个运作良好的深度资金系统的目标是创建和维护一个全球图谱,任何对支持某个特定项目感兴趣的资助者都能够向代表该节点的地址发送资金,资金将根据图中边的权重自动传播到其依赖项(并递归传播到它们的依赖项等)。
你可以想象一个去中心化的协议,使用内置的深度资金工具来发行其代币:一些协议内的去中心化治理将选择一个陪审团,陪审团将运行深度资金机制,因为协议自动发行代币并将其存入对应于自身的节点。通过这样做,协议以一种程序化的方式奖励所有直接和间接的贡献者,这种方式让人想起比特币或以太坊区块奖励如何奖励特定类型的贡献者(矿工)。通过影响边的权重,陪审团获得了一种持续定义其重视的贡献类型的方法。该机制可以作为一种去中心化和长期可持续的替代方案,取代挖矿、销售或一次性空投。
添加隐私
通常,对上述示例中问题的良好判断需要访问私密信息:组织的内部聊天记录、社区成员保密提交的信息等。“仅使用一个AI”的一个好处,尤其是在小规模的上下文中,是给一个AI访问信息的权限比让所有人公开这些信息更可接受。
为了使提炼的人类判断或深度资金在这些上下文中有效,我们可以尝试使用加密技术安全地让AI访问私密信息。这个想法是使用多方计算(MPC)、完全同态加密(FHE)、可信执行环境(TEE)或类似机制来使私密信息可用,但仅限于其唯一输出为“完整列表提交”的机制,这些提交直接放入机制中。
如果你这样做,那么你必须将机制的集合限制为仅为AI模型(而不是人类或AI + 人类组合,因为你不能让人类看到数据),特别是运行在某些特定底层(例如MPC、FHE、可信硬件)的模型。一个主要的研究方向是找出近乎实用的版本,使其高效到有意义。
引擎 + 方向盘设计的好处
这样的设计有许多有前景的好处。最重要的一点是,它们允许构建去中心化自治组织(DAO),在这些组织中,人类投票者控制设定方向,但不会被过多的决策所淹没。它们达到了一个幸福的中间地带,每个人不必做出N个决策,但他们的权力超过了仅仅做出一个决策(这通常是委托的工作方式),并且以一种更能引发丰富偏好的方式,这些偏好是难以直接表达的。
此外,这样的机制似乎具有激励平滑的特性。我在这里所说的“激励平滑”是两个因素的结合:
- 扩散: 投票机制采取的任何单一行动对任何单一参与者的利益没有过大的影响。
- 混淆: 投票决策与它们如何影响参与者利益之间的联系更加复杂且难以计算。
这里的术语混淆和扩散是取自密码学,它们是使密码和哈希函数安全的关键特性。
现实世界中激励平滑的一个好例子是法治:政府的最高层级并不定期采取“给爱丽丝的公司200M美元”、“罚款鲍勃的公司100M美元”等形式的行动,而是通过旨在均匀适用于大多数参与者的规则,这些规则随后由一类不同的参与者进行解释。当这一机制有效时,带来的好处是大大减少了贿赂和其他形式腐败的好处。而当这一机制被违反时(在实践中经常发生),这些问题会迅速被放大。
人工智能显然将在未来中占据非常重要的部分,这不可避免地包括在治理的未来中占据重要地位。然而,如果你在治理中涉及人工智能,这显然存在风险:人工智能存在偏见,在训练过程中可能会被故意腐败,并且“让人工智能负责”可能实际上意味着“让负责升级人工智能的人负责”。提炼的人类判断提供了一条替代的前进道路,让我们能够以开放的自由市场方式利用人工智能的力量,同时保持人类主导的民主控制。
任何对更深入探索和参与这些机制感兴趣的人都被强烈鼓励查看当前活跃的深度资金轮次,网址为https://cryptopond.xyz/modelfactory/detail/2564617。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







