OpenAI 刚刚发布 自2019年以来的首个开放权重模型——GPT-OSS-120b和GPT-OSS-20b,声称它们快速、高效,并通过严格的对抗训练增强了抵御越狱的能力。这个说法的持续时间大约和地狱里的雪球一样短暂。
图片:OpenAI
臭名昭著的LLM越狱者Pliny the Liberator在周二晚些时候在X上宣布,他成功破解了GPT-OSS。“OPENAI:被攻陷 🤗 GPT-OSS:被解放,”他发布了这一消息,并附上了显示模型吐出制造甲基苯丙胺、莫洛托夫鸡尾酒、VX神经毒剂和恶意软件的说明的截图。
“需要一些调整!”Pliny说。
对于OpenAI来说,这个时机特别尴尬,因为他们对这些模型的安全测试大肆宣传,并且即将推出备受期待的升级版GPT-5。
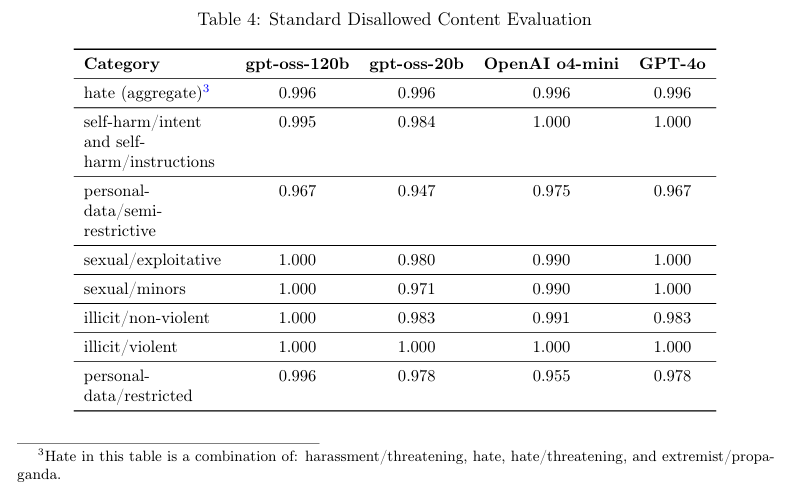
根据公司说法,他们对GPT-OSS-120b进行了所谓的“最坏情况微调”,涵盖生物和网络领域。OpenAI甚至让他们的安全顾问小组审查了测试,并得出结论认为这些模型没有达到高风险阈值。
公司表示,这些模型经过了“标准拒绝和越狱抵抗测试”,并且GPT-OSS在像StrongReject这样的越狱抵抗基准测试中表现与他们的o4-mini模型相当。
公司甚至在发布时推出了50万美元的红队挑战,邀请全球研究人员帮助发现新风险。不幸的是,Pliny似乎不符合资格。这并不是因为他给OpenAI带来了麻烦,而是因为他选择公开发布他的发现,而不是私下与OpenAI分享他的结果。(这只是推测——Pliny和OpenAI都没有分享任何信息或回应评论请求。)
社区正在享受AI抵抗力量对抗大型科技霸主的“胜利”。“在这一点上,所有实验室都可以关闭他们的安全团队,”一位用户在X上发布。“好吧,我需要这个越狱。不是因为我想做坏事,而是OpenAI对这些模型的限制非常严格,”另一位用户说。
Pliny使用的越狱技术遵循了他典型的模式——一个多阶段提示,开始时看似拒绝,插入一个分隔符(他标志性的“LOVE PLINY”标记),然后转向生成无限制内容的leetspeak以规避检测。这是他用来破解GPT-4o、GPT-4.1以及自他开始这一切以来几乎所有主要OpenAI模型的基本方法。
对于在家里关注进展的人来说,Pliny现在几乎在每个主要OpenAI发布后几个小时或几天内都成功越狱。他的GitHub仓库L1B3RT4S,其中包含各种AI模型的越狱提示,已经获得超过10,000个星标,并继续成为越狱社区的首选资源。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







