The high degree of character consistency has brought an unprecedented "Vibe Photoshoping" experience.

Do you remember the mysterious AI image editing model "nano-banana" that everyone was discussing before? At that time, it was hotly debated in the LMArena large language model arena due to its outstanding performance. Various tech experts from Google Gemini also took turns to tease the public on social media, even becoming rumored to be the upcoming Gemini 3.0 Pro.
Now, Google has finally unveiled its mysterious veil.
In the early hours of August 27, Beijing time, Google AI Studio officially released Gemini 2.5 Flash Image (codename: nano banana) 🍌.
The long-awaited Gemini 2.5 Flash Image has finally arrived | Image source: Geek Park
This is Google's most advanced image generation and editing model to date, not only incredibly fast, providing an almost "lightning-like" experience, but also achieving SOTA results on multiple rankings, leading the way in LMArena.
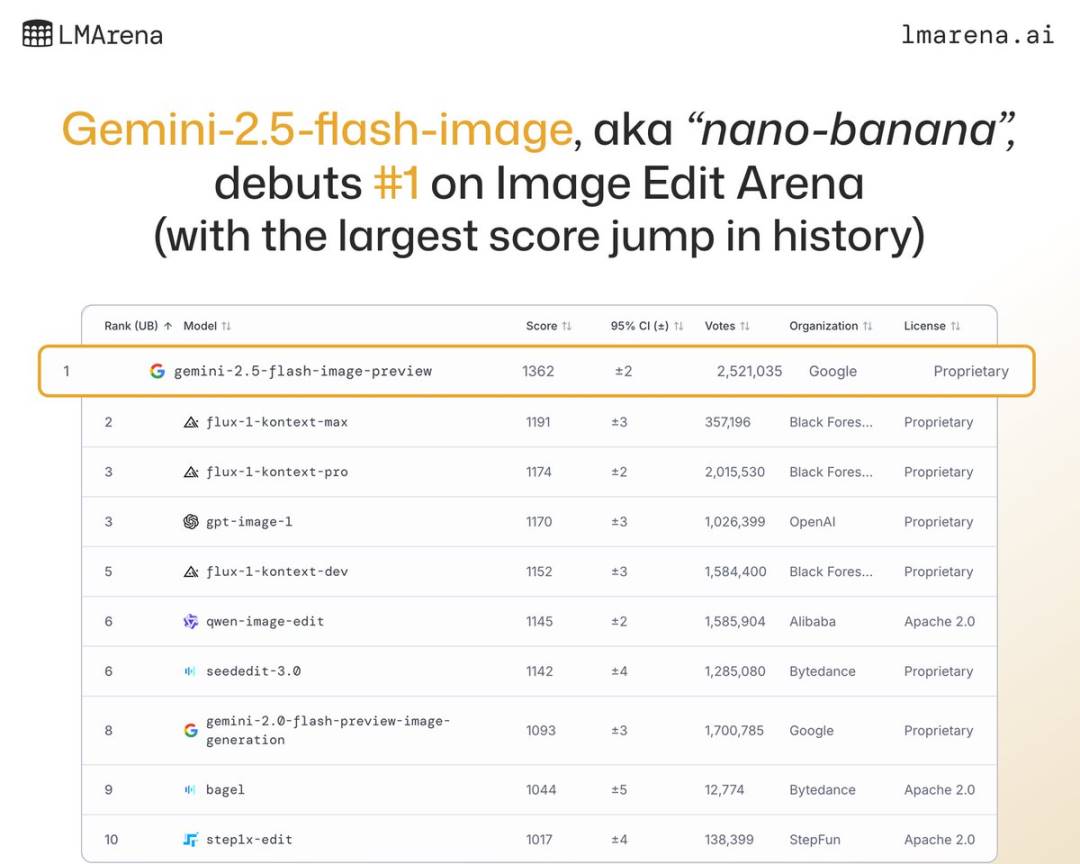
Gemini 2.5 Flash Image achieves SOTA capabilities right from the start | Image source: LMarena.ai
In a technical blog, Google mentioned that Gemini 2.0 Flash had already won developers' favor with its low latency and high cost-effectiveness, but users have always been looking forward to higher quality images and more powerful creative control. Gemini 2.5 Flash Image comes with these significant upgrades: character consistency is finally fully maintained, prompt-based image editing is more precise, the fusion effect of multiple images is natural and smooth, and its understanding of real-world knowledge makes it not just a model, but a "starting point" for the next generation of blockbuster applications.
Geek Park also experienced it firsthand. Surprisingly, this is not just a model update; it gives a real sense that the future of AI photo editing is just around the corner.
Experience now available in Google AI Studio | Image source: Geek Park
At first, I approached it with a conventional mindset, "let's see how fast the new model is." But unexpectedly, just a few hours of experience made me feel like I had a glimpse of what the next generation of blockbuster applications would look like.
In the past, we were used to tools like Meitu Xiuxiu, where you could quickly beautify a photo with a few clicks and filters. But Gemini 2.5 Flash Image feels completely different. It is incredibly fast, smart like a designer who understands your thoughts; you just need to express the desired effect, and it can present the image in seconds.

In addition to the effects, speed is another obvious difference in the experience of Gemini 2.5 Flash Image compared to previous model-generated images | Image source: Geek Park
01 Fast Generation, Results in Seconds
The most intuitive experience of nano banana is speed. In the past, when using some open-source models, even with a decent computer configuration, it would take dozens of seconds or even longer from inputting a prompt to generating a decent image. For mobile users, this waiting process is even more torturous.
But Gemini 2.5 Flash Image has lowered this threshold to just a few seconds. It is Google's claimed "latest, fastest, and most efficient" native multimodal model, and significant optimization has clearly been made. During my actual testing, I input a prompt, and results were generated in about three to four seconds, with resolution and detail being quite clear.
This experience is very similar to how we usually process photos with Meitu Xiuxiu: click the "beautify" button, and the effect is almost instantaneous. The difference is that Meitu Xiuxiu applies pre-set filters using algorithms, while Gemini 2.5 Flash Image constructs an image from scratch or makes significant modifications to a photo based on your needs. This "point and shoot" satisfaction is unimaginable compared to the cumbersome photo editing processes of the past.

Requests like "remove background pedestrians" can be solved with just one prompt | Image source: Geek Park
If speed addresses the experience of traditional photo editing users, then "native multimodal" addresses the boundaries of AI image capabilities.
Gemini 2.5 Flash Image can not only generate images but also simultaneously understand text and image inputs. This means I can provide it with a photo and a text prompt at the same time, and it will combine the information from both to understand what I want.
For example, I uploaded a photo taken on the street and told it, "Change the background to a night scene in Shinjuku, Tokyo." It not only recognized the subject in my uploaded photo but also accurately extracted the person and replaced the background with the neon-lit streets of Shinjuku. What’s more, it maintained the consistency of light and shadow on the person, completely avoiding the "hard cut" effect that manual extraction often suffers from.
This understanding reminds me of a feature frequently mentioned by mobile manufacturers in their built-in photo albums in recent years—"one-click background change." However, the background changes back then often had blurry edges and incorrect lighting, resulting in a very artificial effect. Now, Gemini 2.5 Flash Image can use world knowledge and visual understanding to fill in these details, resulting in a much more natural outcome, achieving far more accurate detail retention than traditional text-to-image/image-to-image model tools.

Original image & Gemini 2.5 Flash Image generated effect | Image source: Geek Park
This is also why I believe it will redefine the photo editing experience: no longer relying on extensive manual adjustments, but rather completing tasks through the model's natural semantic understanding, such as in scenarios requiring high detail in portrait editing.

For portrait image processing needs, Gemini 2.5 Flash Image's character consistency truly provides an unprecedented "Vibe Photoshoping" experience.

Helping programmers "save face" in a second | Image source: Geek Park
This experience breaks many people's previous impressions of AI image generation—"mystical": regardless of how well you write the prompt, the output could be stunning; if the prompt is average, the generated result might completely miss the mark.
But in Gemini 2.5 Flash Image, I found that this "mystical feeling" has been significantly reduced. Its understanding of prompts is more precise and closer to user intuition—this is why many people suddenly feel it is much more usable.
For instance, when I told it, "Blur the background, highlight the foreground person," the generated image a few seconds later was exactly what I wanted; when I asked it to "change the person in the photo to a smiling expression," not only did the corners of the mouth slightly rise, but even the eyes were adjusted, with details being very well done; I even tried "colorizing a black and white photo," and the resulting color image was not just a random splash of color, but rather as close as possible to the color atmosphere that should be present in historical photos.
This "what you say is what you get" ability reminds me of past experiences with Meitu Xiuxiu, where I might just want to smooth the skin, but the entire face ended up looking like a "ten-level beautified" fake face. Now, Gemini 2.5 Flash Image's operation is precise and restrained; it truly understands what you want and tries to restore it.
02 Enhanced Capabilities, Hard to Go Back
To make it more intuitive, I specifically compared it with the mobile photo editing tools I commonly use.
In Snapseed, if I want to blur the background, I usually need to spend one or two minutes manually selecting the foreground area and then adjusting the blur level. Even with practice, repeated modifications are inevitable.
In Meitu Xiuxiu, although there is a one-click background blur feature, it often blurs the edges of the person, resulting in an unnatural effect.
However, in Gemini 2.5 Flash Image, I only need to provide a single sentence, and it automatically recognizes the boundaries between the person and the background, producing a natural blur effect without the need for further adjustments.

While changing details in the image, it also avoids the "random splashes" that often occur with previous AI tools | Image source: Twitter
This comparison actually illustrates one point: Gemini 2.5 Flash Image liberates users from complex operations, delegating more work to the model. For ordinary people, it lowers the threshold for photo editing; for professionals, it saves a significant amount of time.
After the experience, my biggest impression is that Gemini 2.5 Flash Image is no longer just a photo editing tool, but is closer to an "intelligent assistant."
In the past, when we used Meitu Xiuxiu, we were working with a preset collection of functions—filters, beautification, mosaics—each button corresponding to a specific function. What you had to do was select and adjust step by step until you were satisfied.
Now, the logic of Gemini 2.5 Flash Image is completely different. It no longer requires you to learn the logic of the tools; it directly understands your needs. You just need to say it, and it will complete the task for you.
This shift may seem subtle, but it fundamentally changes the relationship in the photo editing process. Previously, we had to adapt to the tools; now, the tools adapt to us. This mode of interaction is itself a prototype of the next generation of applications.
Looking at it now, Gemini 2.5 Flash Image is still in its early stages, and its functionalities may still have boundaries. However, the speed, understanding, and fidelity it demonstrates are enough to spark imagination about the future.
What would it look like if combined with Meitu Xiuxiu? Perhaps you open the app and say to your phone, "Help me edit this photo to make the skin look more natural," and a few seconds later, the result is generated; maybe while traveling, you tell it, "Change the weather to sunny," and the photo instantly transforms into a bright, sunny scene; or even in video editing, you could change the entire atmosphere of a segment with just one sentence.

This method may quickly become the mainstream image editing function in mobile operating systems in the future | Image source: Twitter
This is why I believe it will rapidly revolutionize the existing operational processes in the photo editing tool field, defining the next generation of "Meitu Xiuxiu": not just photo editing, but reshaping the interaction method of image processing, making AI your partner in photography post-production.
However, currently, Gemini 2.5 Flash Image cannot yet serve as an out-of-the-box, mass-market photo editing app: not only because its primary purpose remains image generation rather than fine-tuning existing images, but also because all images created or edited through Gemini 2.5 Flash Image will include a SynthID digital watermark for social content platforms to identify AI-generated content.
03 The Explosive Point of a Hit Product
Looking back, the reason Meitu Xiuxiu became a universal application was that it solved a problem everyone wanted to address in the simplest way—making photos look better.
Gemini 2.5 Flash Image takes this a step further by refining complex AI capabilities into a "results in seconds" experience that anyone can use.
When I first told it, "Help me blur the background," and a few seconds later, the image was naturally processed, I knew in my heart: this is the explosive point of a hit application. It is not just a model; it is the underlying capability for countless new products in the future.
The AI one-click weather change feature that became a sensation among mobile users a few years ago | Image source: vivo community
Perhaps in a few years, we will forget the codename Banana, but we will see more and more image processing tools that allow you to "say what you want, and it can be realized immediately," which may become a shared memory for a generation of users, just like Meitu Xiuxiu did back in the day.
Only this time, AI will push imagination even further.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






