每个主要人工智能实验室用来声称编码优势的数字刚刚被宣布为毫无意义。
OpenAI 本周发布了一篇文章,宣布SWE-bench Verified,这个测量人工智能编码能力的首选基准,充满了故障测试和训练数据泄漏,因此不再告诉你模型是否能够实际编写软件的任何有用信息。
该基准的工作方式如下:给一个人工智能一个来自流行开源Python项目的真实GitHub问题,要求它在未查看测试的情况下修复错误,并检查其补丁是否使失败的测试通过,而没有破坏其他任何东西。
OpenAI 在2024年8月创建了SWE-bench Verified,作为2023年基准的一个更清晰的版本,招募了93名软件工程师来筛选那些不可能或设计不良的任务。
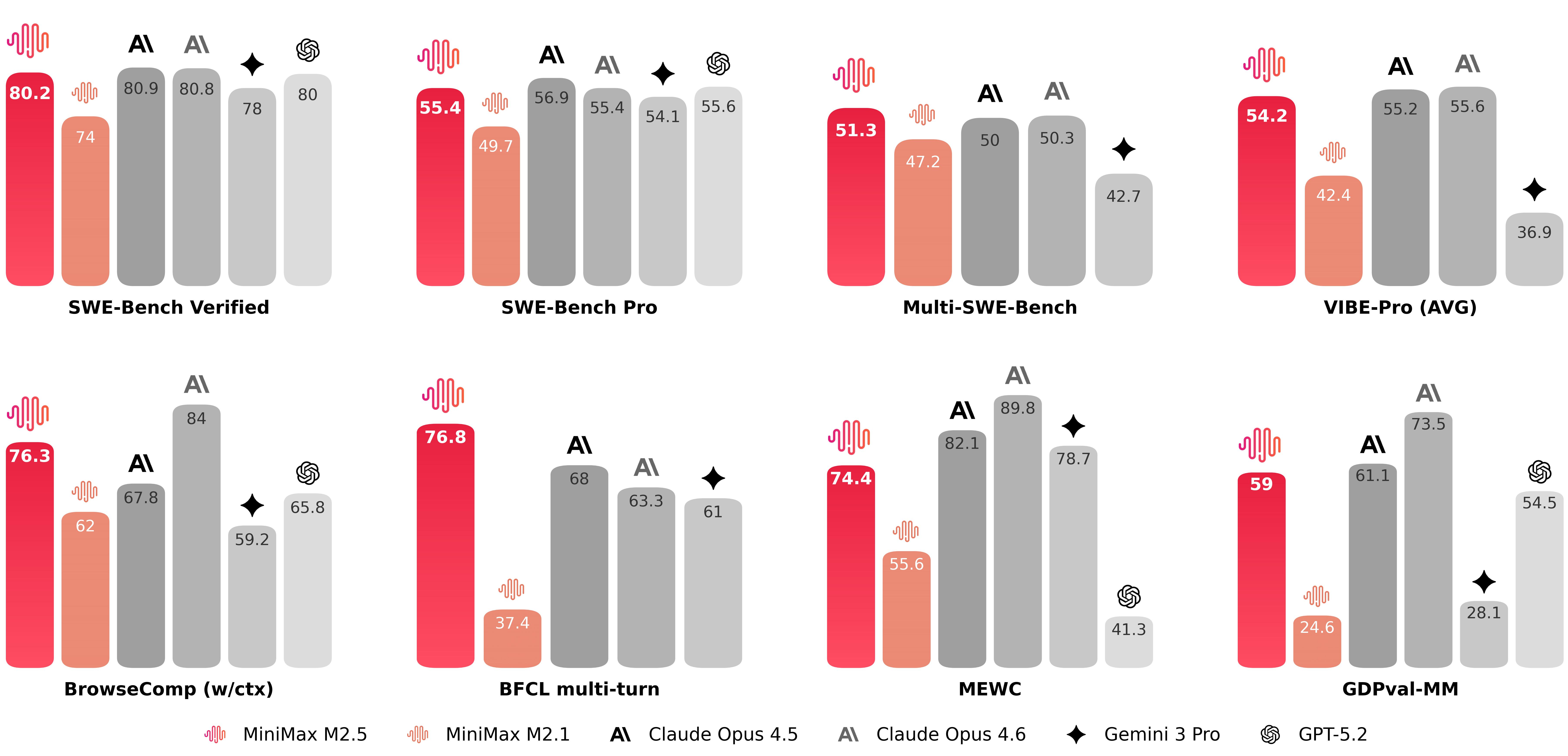
清理工作足够成功,以至于每个主要实验室开始引用其得分作为进步的证明。当Anthropic在2025年5月推出Claude Opus 4时,Decrypt报道该模型在SWE-bench Verified上的得分为72.5%,超过了GPT-4.1的54.6%和Gemini 2.5 Pro的63.2%。这是一个重要的编码基准。
从那时起,从美国到中国的每个人工智能实验室都展示了SWE的表现,以此声称自己是最佳编码能力模型的王座。
图片:Minimax
现在OpenAI表示,这场竞争在某种程度上是海市蜃楼。根据报告,团队审计了138个GPT-5.2在64次独立运行中始终失败的任务,并让六名工程师对每个任务进行了审查。最终得出的结论是,这些任务中有59.4%是损坏的。
大约35.5%的测试写得过于狭窄,要求特定的函数名称,而在问题描述中从未提到过。另有18.8%的测试检查了原问题中根本没有的特性,这些特性来自于无关的拉取请求。
污染问题大致是这样的:SWE-bench从大多数人工智能公司在构建训练集时爬行的开源代码库中提取问题。OpenAI测试了GPT-5.2、Claude Opus 4.5和Gemini 3 Flash Preview是否在训练过程中看到了该基准的解决方案。三者都看到了。
仅给出一个任务ID和简短提示,每个模型都能够凭记忆复现确切的代码修复,包括变量名和文档中未出现的内联注释。在一个案例中,GPT-5.2的思维链日志显示它推理出一个特定参数一定是在“Django 4.1左右添加的”——这个细节只在Django的发布说明中出现,而不在任务描述中。它是在回答它已经看到过的答案的问题。
OpenAI现在推荐SWE-bench Pro,这是Scale AI推出的一个新基准,使用更为多样化的代码库和减少训练数据曝光的许可证。性能下降的幅度令人震惊:在旧的Verified基准上得分超过70%的模型在SWE-bench Pro的公共分割上得分约23%,在其私有任务上得分更低。
在当前的公共SWE-bench Verified排行榜上,OpenAI远未登上基准的领奖台。退出一个失利的基准并支持一个所有人都以23%起步的基准,在方便的时刻重置记分牌,并使竞争对手的声明显得不那么令人印象深刻。
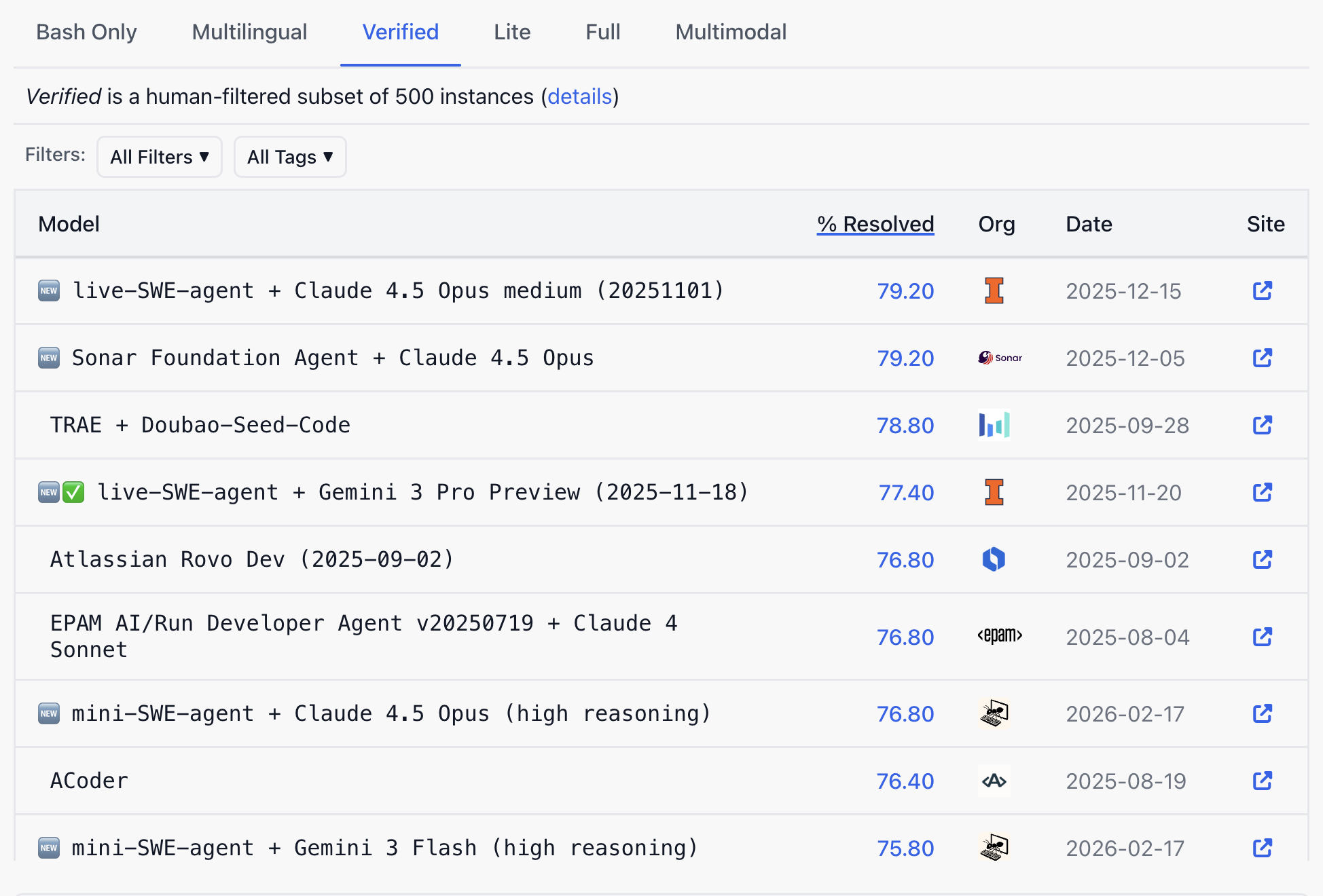
考虑到备受期待的新版本DeepSeek传闻将在代理和编码任务中超越或非常接近美国人工智能模型,尤其是与一个免费、开源模型的竞争,这一点尤为重要。该模型可能在几天内发布,而SWE-bench Verified可以成为衡量其质量的关键指标。
OpenAI表示,正在构建不公开发布的私人评估,指出其GDPVal项目,其中文域专家编写原始任务,由经过培训的人类评审员进行评分。
基准问题并不新,也不仅限于编码。人工智能实验室一直在经历多次评估,每次评估在模型训练或任务证明过于狭窄之前都是有用的。
但使这一案例显著的原因在于,OpenAI曾大力宣传SWE-bench Verified,在模型发布过程中推广它,现在则公开记录它是如何彻底失败的——包括展示它们自己的模型在其中作弊。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







