美国政府机构对中国最强大的人工智能发布了判决:落后八个月,随着时间的推移,差距越来越大。互联网阅读了方法论并开始提出问题。
CAISI——人工智能标准与创新中心,隶属于NIST——于5月1日发布了对DeepSeek V4 Pro的评估。结论是:DeepSeek的开源旗舰“落后于前沿约8个月。”
CAISI还称这是迄今为止对其评估的最强大的中国人工智能模型。
评分系统
CAISI并不像大多数评估者那样计算基准分数的平均值。相反,它应用项目反应理论——一种来自标准化测试的统计方法——通过跟踪每个模型解决和未解决的问题,在五个领域的九个基准上估计每个模型的潜在能力:网络安全、软件工程、自然科学、抽象推理和数学。
IRT估计的Elo分数:GPT-5.5为1260分,Anthropic的Claude Opus 4.6为999分。DeepSeek V4 Pro的得分约为800(±28),与749的GPT-5.4 mini非常接近。在CAISI的系统中,DeepSeek更接近于旧一代的GPT mini,而不是Opus。
基准中的分数系统以标准化测试评分学生的方式对模型进行评分——不是按原始正确百分比,而是通过加权解决和未解决的问题,产生的得分估计仅在同一评估中的其他模型中才有意义。得分越高,模型在一般意义上越好,最佳模型的得分成为评估模型能力的参考点。
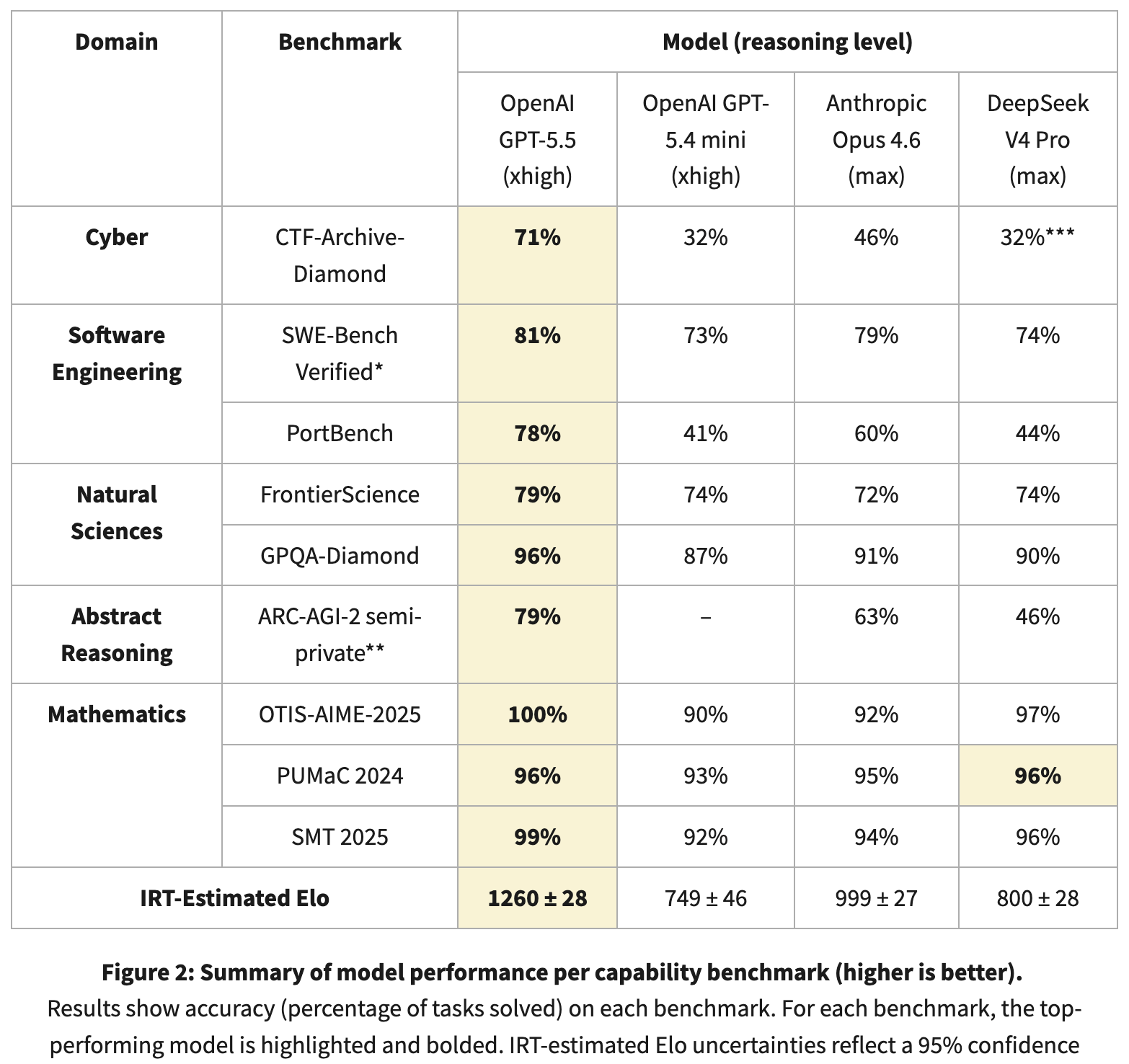
无法重现CAISI的结果,因为九个基准中的两个是非公开的,而在这两个基准中差距最大。例如,GPT-5.5在CAISI的网络安全测试CTF-Archive-Diamond中得分71%,而DeepSeek仅约32%。
在公开基准上,情况有所变化。GPQA-Diamond——博士级科学推理,以正确百分比评分——使DeepSeek得分90%,落后于Opus 4.6的91%。数学奥林匹克基准(OTIS-AIME-2025,PUMaC 2024,SMT 2025)使DeepSeek分别得分97%、96%和96%。在SWE-Bench Verified——真实的GitHub错误修复,以解决的百分比评分——DeepSeek得分74%,而GPT-5.5得分81%。DeepSeek自己的技术报告声称V4 Pro与Opus 4.6和GPT-5.4相当。
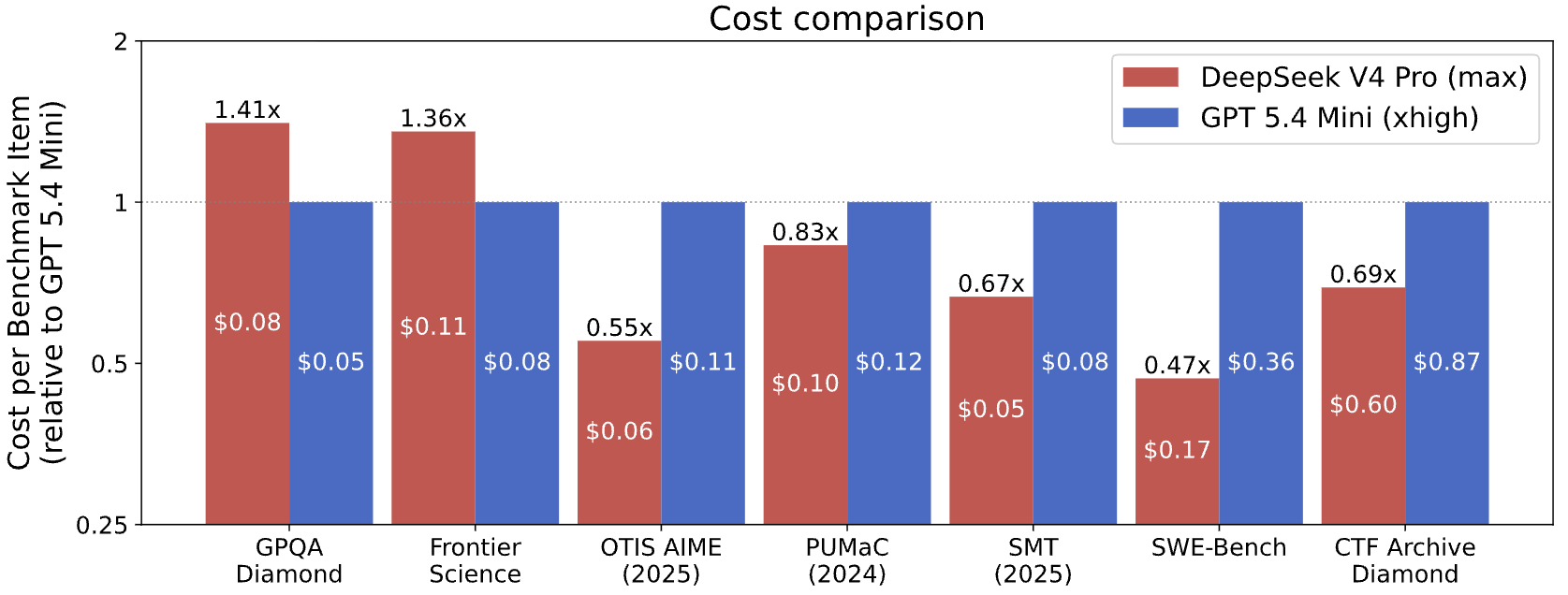
为了进行成本比较,CAISI筛选出了任何在表现上显著较差或每个token成本显著高于DeepSeek的美国模型。只有一个模型通过了门槛:GPT-5.4 mini。这就是整个美国的前沿,筛选为单一条目。
DeepSeek在7个基准中有5个表现更便宜,甚至击败了OpenAI最小和能力最弱的AI模型。
反驳:差距是更大还是更小?
批评CAISI的方法论并不能完全为DeepSeek辩护。以假名Ex0bit的人工智能开发者直接反击:“没有‘差距’,也没有人落后8个月。我们在每一次闭门的美国发布会上都受到了嘲讽,并以开源权重进行了展示。”
人工分析智能指数v4.0——一个追踪前沿模型智能的评分系统——显示截至2026年5月,OpenAI接近60分,DeepSeek在低50分,差距比一年前紧缩得多。
基于标准化基准,他们的方法显示差距实际上正在缩小。
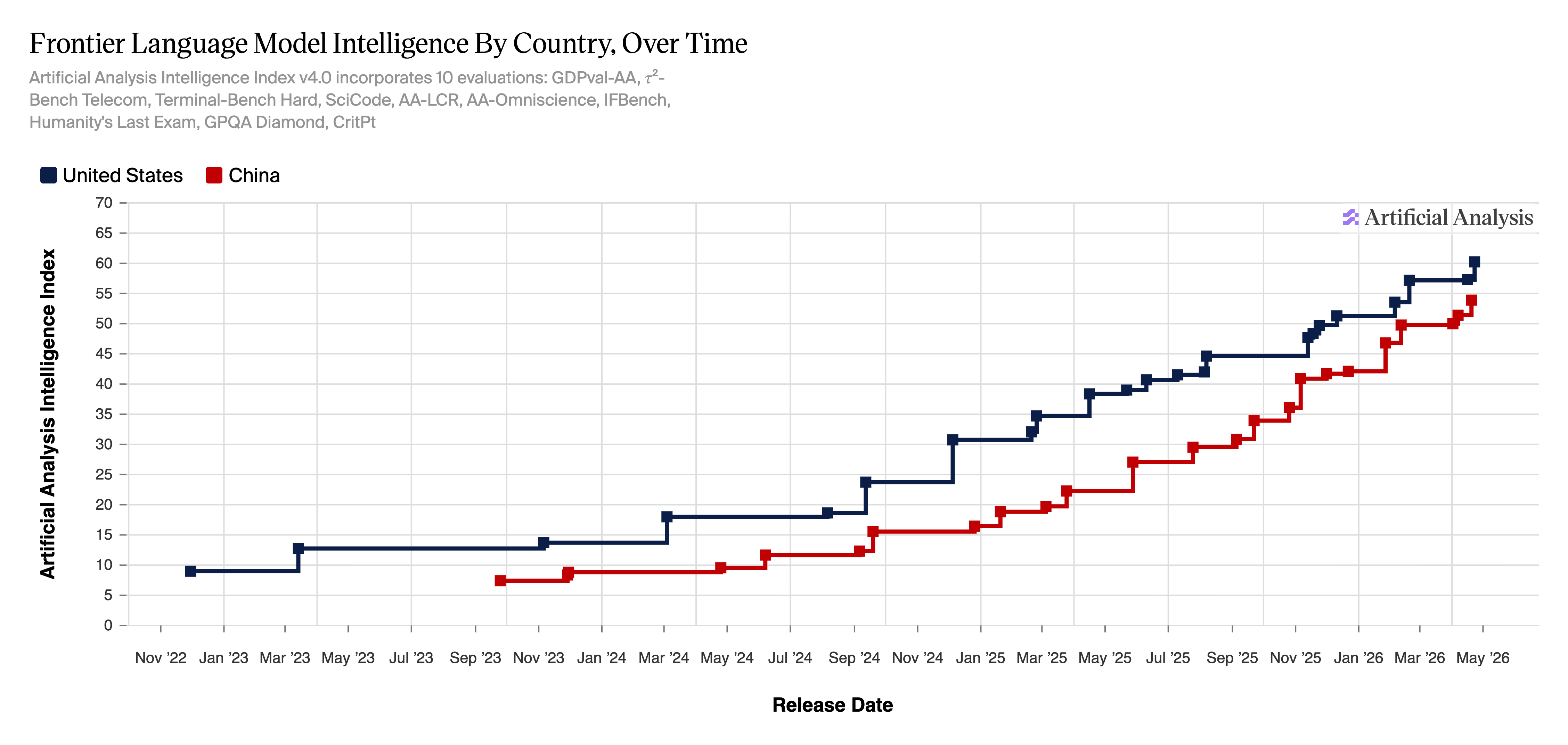
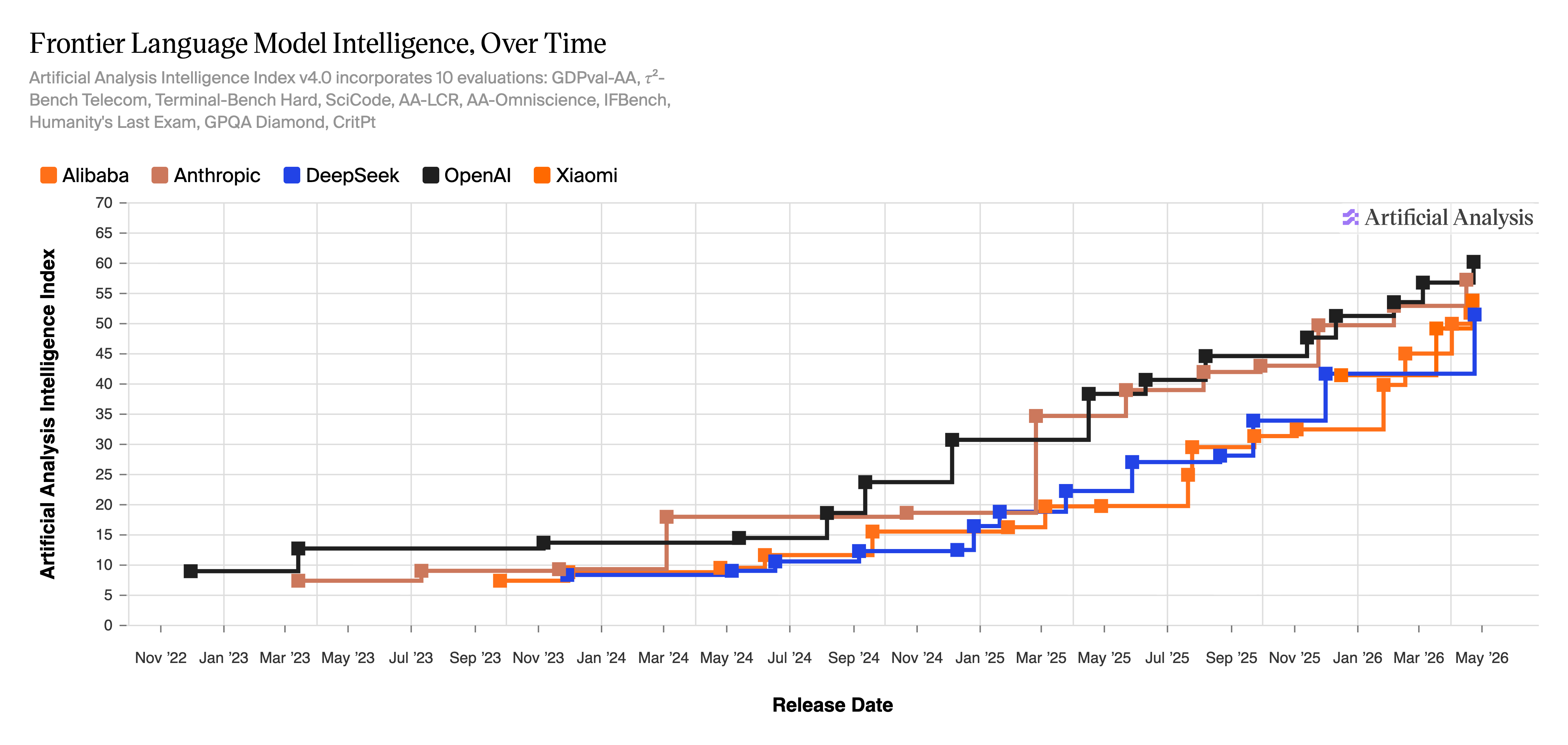
当DeepSeek首次出现在 2025年1月时,问题是中国是否已经赶上了。美国实验室急于应对。斯坦福大学的2026年人工智能指数——于4月13日发布——报告称Claude Opus 4.6与中国Dola-Seed-2.0 Preview之间的Arena排行榜差距正在缩小,现在只有2.7%。
CAISI计划在不久的将来发布更完整的IRT方法论报告。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







