Open-source models are slowly but steadily surpassing closed-source models.
Source: China Entrepreneur Magazine

Image source: Generated by Wujie AI
"Abandon generative models and do not study LLMs (large language models); we cannot achieve human-level intelligence in AI solely through text training." Recently, Meta's Chief AI Scientist Yann LeCun once again criticized generative AI at the 2025 AI Action Summit in Paris.
Yann LeCun believes that while existing large models operate efficiently, their reasoning processes are divergent, and the generated tokens may not fall within the range of reasonable answers, which is why some large models produce hallucinations. Although many current generative models allow AI to pass the bar exam and solve mathematical problems, they cannot perform household chores. What humans can do without thinking is very complex for generative AI.
He also stated that generative models are fundamentally unsuitable for creating videos; the AI models that can generate videos do not understand the physical world; they are merely generating beautiful images. Yann LeCun supports models that can understand the physical world and proposed a joint embedding prediction architecture (JEPA) that is more suitable for predicting video content, always believing that only AI that can truly understand the physical world can achieve artificial intelligence on par with human intelligence.
Finally, Yann LeCun emphasized the necessity of open-source AI platforms. In the future, we will have universal virtual assistants that will regulate all our interactions with the digital world. They should be able to speak all the languages in the world, understand all cultures, all value systems, and all centers of interest. Such AI systems cannot come from a few companies in Silicon Valley; they must be accomplished through effective collaboration.
Key points are as follows:
- We need human-level intelligence because we are accustomed to interacting with people. We look forward to the emergence of AI systems with human-level intelligence. In the future, ubiquitous AI assistants will become a bridge between humans and the digital world, helping humans interact better with the digital world.
- We cannot achieve human-level intelligence in AI solely through text training; this is impossible.
- At Meta, we refer to AI that can achieve human-level intelligence as advanced machine intelligence. We do not like the term "AGI" (artificial general intelligence) and prefer to call it "AMI," which sounds similar to the word "friend" in French.
- Generative models are fundamentally unsuitable for creating videos. You may have seen AI models that can generate videos, but they do not truly understand physics; they are just generating beautiful images.
- If you are interested in achieving human-level intelligence in AI and you are in academia, do not study LLMs, as you are competing with hundreds of people who have tens of thousands of GPUs, which is meaningless.
- AI platforms need to be shared; they should be able to speak all the languages in the world, understand all cultures, all value systems, and all centers of interest. No single company in the world can train such foundational models; it must be accomplished through effective collaboration.
- Open-source models are slowly but steadily surpassing closed-source models.
The following is the full text of the sharing (with some omissions):
Why We Need Human-Level AI
It is well known that we need human-level artificial intelligence, which is not only an interesting scientific question but also a product demand. In the future, we will wear smart devices, such as smart glasses, through which we can access AI assistants at any time and interact with them.
We need human-level intelligence because we are accustomed to interacting with people. We look forward to the emergence of AI systems with human-level intelligence. In the future, ubiquitous AI assistants will become a bridge between humans and the digital world, helping humans interact better with the digital world. However, compared to humans and animals, current machine learning is still very poor. We have not yet created machines that possess human learning abilities, common sense, and the ability to understand the physical world. Both animals and humans can act based on common sense, and these actions are essentially goal-driven.

Therefore, almost all artificial intelligence systems currently in use do not possess the characteristics we desire. They recursively generate one token after another and then use the marked tokens to predict the next token. The way these systems are trained is by putting information at the input end and then trying to reproduce the information at the output end. It is a causal structure that cannot cheat or use specific inputs to predict itself; it can only look at the tokens around it. Thus, it is very efficient, and people refer to it as a general large model, which can be used to generate text and images.
However, this reasoning process is divergent. Each time you generate a token, it may not fall within the range of reasonable answers and may take you further away from the correct answer. If this happens, subsequent corrections are impossible, which is why some large models produce hallucinations and nonsensical outputs.
Currently, these artificial intelligences cannot replicate human intelligence. We cannot even replicate the intelligence of animals like cats or mice, which understand the rules of the physical world and can perform actions based on common sense without planning. A 10-year-old child can complete the tasks of clearing the table and wiping it without needing to learn, while a 17-year-old can learn to drive in 20 hours. However, we have not yet been able to create a household robot, indicating that our current AI research and development lack some very important elements.
Our existing AI can pass the bar exam, solve mathematical problems, and prove theorems, but it cannot do household chores. What we consider tasks that can be done without thinking are very complex for AI robots, while tasks that we think are unique to humans, such as language, playing chess, and composing poetry, can now be easily accomplished by AI and robots.
We cannot achieve human-level intelligence in AI solely through text training; this is impossible. Some vested interests may claim that AI intelligence will reach human doctoral levels next year, but this is simply not possible. AI may reach human doctoral levels in specific fields like chess or translation, but general large models cannot achieve this. If we only train AI models specifically targeting certain domain problems, if your question is very standard, the answer can be generated in seconds. However, if you slightly modify the phrasing of the question, the AI may still provide the same answer because it has not truly thought about the problem. Therefore, we need time to develop an artificial intelligence system that can achieve human-level intelligence.
Not "AGI" but "AMI"
At Meta, we refer to AI that can achieve human-level intelligence as advanced machine intelligence. We do not like the term "AGI" (artificial general intelligence) and prefer to call it "AMI," which sounds similar to the word "friend" in French. We need models that can gather information through sensory input and learn, manipulate it in the mind, and learn two-dimensional physics from videos. For example, systems with persistent memory, systems that can plan actions hierarchically, and systems that can reason, then achieve controllable and safe systems through design rather than fine-tuning.
Currently, I know that the only way to build such systems is to change the way current AI systems perform reasoning. The reasoning method of current LLMs is to generate a token by running a fixed number of neural network layers (Transformer) and inputting it, then running a fixed number of neural network layers again. The problem with this reasoning method is that regardless of whether you ask a simple or complex question, when you ask the system to respond with "yes" or "no," it will spend the same amount of computation to answer them. Therefore, people have been cheating, telling the system how to respond. Humans know this reasoning thinking technique, allowing the system to generate more tokens, which will consume more computing power to answer questions.
In reality, reasoning does not work this way. In many different fields, such as classical statistical AI and structural prediction, reasoning works as follows: you have a function to measure the compatibility or incompatibility between your observations and output values. The reasoning process involves finding the value that compresses the information space to a minimum and outputs it; we call this function the energy function. When the results do not meet the requirements, the system will only perform optimization and reasoning. If the reasoning problem is more difficult, the system will spend more time reasoning; in other words, it will take longer to think about complex problems.
In classical AI, many things are related to reasoning and search, so optimizing any computational problem can be simplified to a reasoning problem or a search problem. This type of reasoning is more similar to what psychologists refer to as System 2, which is considering how to act before taking action, while System 1 refers to those things that can be done without thinking, which becomes a subconscious process.
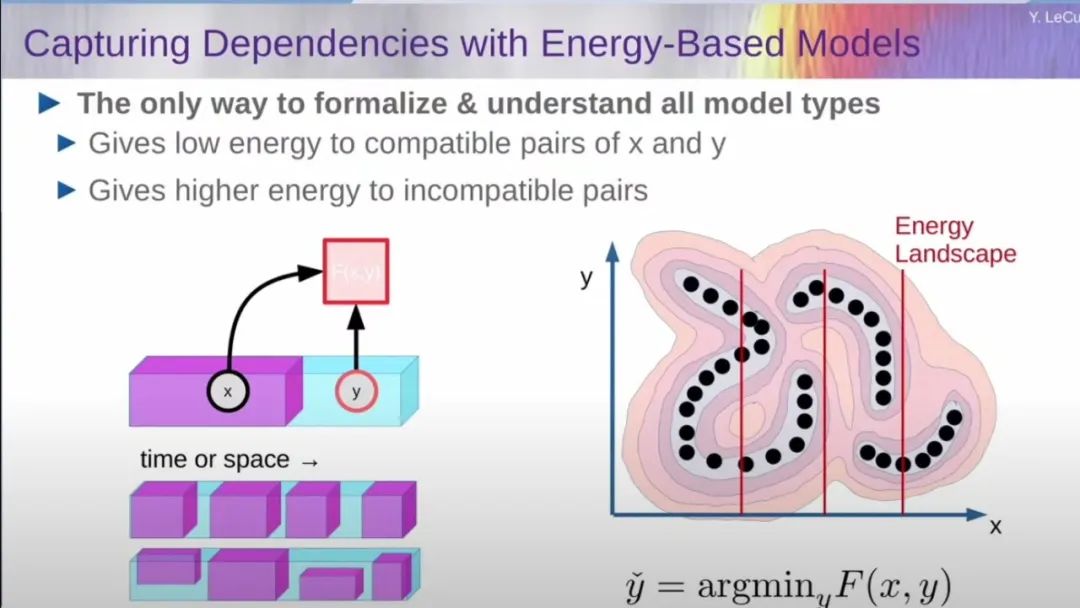
Source: Video screenshot
Let me briefly explain the energy model, which allows us to capture the dependencies between variables through the energy function. Suppose the observation value is X and the output value is Y. When X and Y are compatible, the energy function takes a low value; when X and Y are incompatible, the energy function takes a high value. You do not want to calculate Y solely from X; you just want an energy function to measure the degree of incompatibility. You provide an X and find a Y with lower energy.
Now, let’s take a closer look at how the architecture of the world model is built and how it relates to thinking or planning. The system works like this: observing the world goes through a perception module that summarizes the state of the world. Of course, the state of the world is not completely observable, so you may need to combine it with memory, which contains your thoughts about the state of the world. The combination of these two forms a world model.
So what is a world model? A world model provides a summary of the current state of the world. It gives a sequence of actions you imagine in an abstract demonstration space, predicting the state of the world after you take these actions. If I tell you to imagine a cube floating in front of you and then rotate this cube vertically by 90°, what does it look like? You can easily visualize how it looks after the rotation in your mind.
I believe that before we have truly functional audio and video, we will have human-level intelligence. If we have this world model that can predict the results of a series of actions, we can input it into a task objective to measure how well the predicted final state meets the goals we set for ourselves. This is just a goal function, and we can also set some constraints, viewing them as requirements that the system must meet for safe operation. With these constraints, we can ensure the safety of the system, preventing you from crossing them; they are rigidly defined and fall outside the scope of training and reasoning.
Now, a series of actions should use a world model, repeatedly applied over multiple time steps. If you perform the first action, it predicts the state after the action is completed. When you perform the second action, it predicts the next state, continuing along this trajectory. You can also set task goals and constraints. If the world is not completely certain and predictable, then the world model may need to have latent variables to explain everything we have not observed about the world, which introduces bias into our predictions. Ultimately, what we want is a system that can plan hierarchically. It may have several abstract levels; at a lower level, we plan low-level actions, such as basic muscle control. But at a higher level, we can plan abstract macro actions. For example, if I am sitting in my office at New York University and decide to go to Paris, I can break this task into two sub-tasks: going to the airport and catching the flight. Then I can detail each step: grabbing my bag, going out, taking a taxi, riding the elevator, buying a ticket…
These actions often feel like we are not consciously doing hierarchical planning; they are almost all subconscious actions, but we do not know how to make machines learn to do this. Almost every machine learning process involves hierarchical planning, but the prompts at each level are manually input. We need to train an architecture that can learn these abstract demonstrations on its own, not only the state of the world but also predict the world model and predict abstract actions at different abstract levels, so that machine learning can perform hierarchical planning unconsciously like humans.
How to Make AI Understand the World
With all these reflections, I wrote a long paper three years ago explaining the areas I believe AI research should focus on. I wrote this paper before the explosion of ChatGPT, and to this day, my views on this issue have not changed; ChatGPT has not changed anything. The paper discusses the path to autonomous machine intelligence, which we now refer to as advanced machine intelligence, because the term "autonomous" tends to scare people. I have introduced it in various speeches.
To make the system understand how the world operates, a common method is to train it in the same way we trained natural language systems in the past and apply it to video. If a system can predict what will happen in a video, you show it a short segment of video and then let it predict what will happen next. Training it to make predictions can actually help the system understand the underlying structure of the world. This applies to text because predicting words is relatively simple; the number of words is limited, and the number of labelable items is also limited. We cannot accurately predict which word will follow another or which word is missing in the text, but we can calculate the probabilities for each word that could be generated from the dictionary.
However, we cannot do this for images or videos; we do not have a good way to represent the distribution of video frames, and every attempt to do so essentially encounters mathematical challenges. Therefore, you can try to solve this problem using the statistics and mathematics invented by physicists; in fact, it is best to completely abandon the idea of probabilistic modeling.
Because we cannot accurately predict what will happen in the world. If you train a system to predict just one frame, it will not perform well. So the solution to this problem is to develop a new architecture, which I call the Joint Embedding Prediction Architecture (JEPA). Generative models are fundamentally unsuitable for creating videos. You may have seen AI models that can generate videos, but they do not truly understand physics; they are just generating beautiful images. The idea of JEPA is to run both the observations and outputs simultaneously, so it is no longer just predicting pixels but predicting what happens in the video.
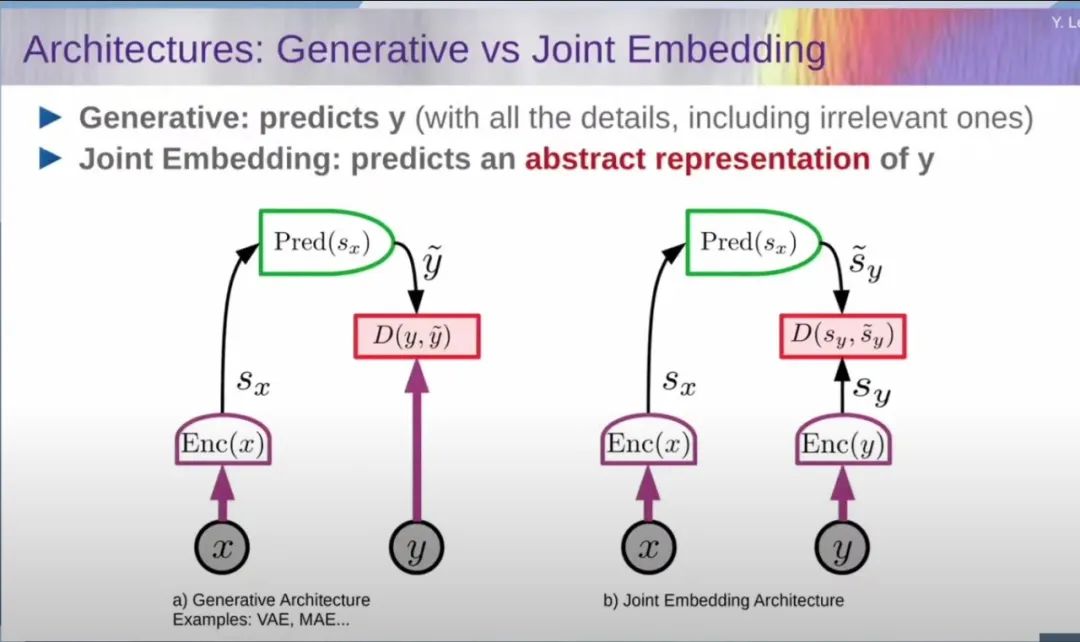
Source: Video screenshot
Let’s compare these two architectures. On the left is the generative architecture, where you input X, the observation, into the encoder, and then make a prediction about Y. This is a simple prediction. On the right, in the JEPA architecture, you run both X and Y simultaneously, possibly with the same or different encoders, and then predict the representation of Y based on the representation of X in this abstract space. This will lead the system to essentially learn an encoder that can eliminate everything you cannot predict, which is what we are really doing.
When we are filming in a room, as the camera starts to move, neither humans nor AI can predict what person will appear in the next frame, what the texture of the wall or floor will be; there are many things we simply cannot predict. Therefore, rather than insisting that we make probabilistic predictions about things we cannot predict, it is better to abandon predicting them and learn a representation where all these details are essentially eliminated, making predictions much simpler and simplifying the problem.
The JEPA architecture has various styles; I will not discuss those latent variables here but will talk about action conditions, which are the most interesting part because they truly represent the world model. You have an observation X, which is the current state of the world, and you input the action you plan to take into the encoder. This encoder is the world model, allowing it to predict the state representation of the world after performing this action. This is how you conduct planning.
Recently, we have conducted in-depth research on Video JEPA. How does this model operate? For example, we first extract 16 consecutive frames from a video as input samples, then mask and damage some frames, and input these partially damaged video frames into the encoder while simultaneously training a prediction module to reconstruct the complete video representation based on the incomplete visual information. Experiments show that this self-supervised learning method has significant advantages, and the deep features it learns can be directly transferred to downstream tasks such as video action classification, achieving excellent performance in multiple benchmark tests.
There is something very interesting: if you show this system a video where some very strange things happen, the system actually tells you that its prediction error is skyrocketing. You filmed a video, took 16 frames from it to measure the system's prediction error, and if something strange happens, like an object spontaneously disappearing or changing shape, the prediction error will rise. It tells you that, despite the system being simple, it has learned a certain degree of common sense; it can inform you if something very strange has happened in the world.
I want to share our latest work—DINO-WM (a new method for establishing visual dynamic models without reconstructing the visual world). Train a predictor with a world image, then run it through the DINO encoder, and finally, the robot may perform an action, allowing it to obtain the next frame of the video. This frame image is then fed back into the DINO encoder to produce a new image, and then train your predictor to predict what will happen based on the actions taken.
Planning is very simple: you observe an initial state, run it through the DINO encoder, then run the world model with imagined actions over multiple time points and steps, and then you have a target state represented by a target image. For example, you run it through the encoder and calculate the difference between the predicted state and the state represented by the target image in the demonstration space, finding a sequence of actions that minimizes the running cost.

Source: Video screenshot
This is a very simple concept, but it works very well. Suppose you have this small T-shaped pattern and want to push it to a specific location. You know where it must go because you have placed the image of that location into the encoder, which will give you a target state in the demonstration space. When you take a series of planned actions, what actually happens in the real world is that you see the internal mental predictions of the action sequence planned by the system, and when you input it into the decoder, it produces a graphical representation of the internal state.
Please Abandon Research on Generative Models
Finally, I have some advice to share with everyone. First, abandon generative models. This is currently the most popular method, and everyone is researching it. You can study JEPA; it is not a generative model; it predicts what will happen in the world in the demonstration space. Abandon reinforcement learning; I have been saying for a long time that it is inefficient. If you are interested in achieving human-level intelligence in AI and you are in academia, do not study LLMs, because you are competing with hundreds of people who have tens of thousands of GPUs, which is meaningless. There are still many problems in academia that need to be solved; the efficiency of planning algorithms is very low, and we must come up with better methods. The JEPA with latent variables in uncertain hierarchical planning is a completely unresolved issue, and scholars are welcome to explore these.

In the future, we will have universal virtual assistants that will always accompany us, regulating all our interactions with the digital world. We cannot allow these AI systems to come from just a few companies in Silicon Valley or China, which means that the platforms we build for these systems need to be open-source and widely accessible. The training costs for these systems are high, but once you have a foundational model, fine-tuning it for specific applications becomes relatively inexpensive and affordable for many.
AI platforms need to be shared; they should be able to speak all the languages in the world, understand all cultures, all value systems, and all centers of interest. No single company in the world can train such foundational models; it must be accomplished through effective collaboration.
Therefore, open-source AI platforms are necessary. The crisis I see in Europe and elsewhere is that geopolitical competition is prompting some governments to essentially declare the release of open-source models illegal because they want to keep scientific secrets to maintain their lead. This is a huge mistake; when you conduct research in secret, you will fall behind, and this is inevitable. What will happen is that other countries in the world will adopt open-source technology, and we will surpass you. This is currently happening; open-source models are slowly but steadily surpassing closed-source models.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








