Perplexity's crawlers kept accessing content from tens of thousands of websites even after those sites explicitly blocked them, according to internet infrastructure provider Cloudflare. The company said Monday it had delisted Perplexity from its verified bot program and implemented blocks against what it characterized as deceptive scraping practices.
San Francisco-based Perplexity was founded in 2022 by Aravind Srinivas (CEO, former OpenAI researcher), Denis Yarats (former Facebook AI), Johnny Ho, and Andy Konwinski (co‑founders of Databricks). The company has received funding from investors including Elad Gil, Nat Friedman (former GitHub CEO), and Nvidia, among others, and was valued at $18 billion after raising $100 million last month.
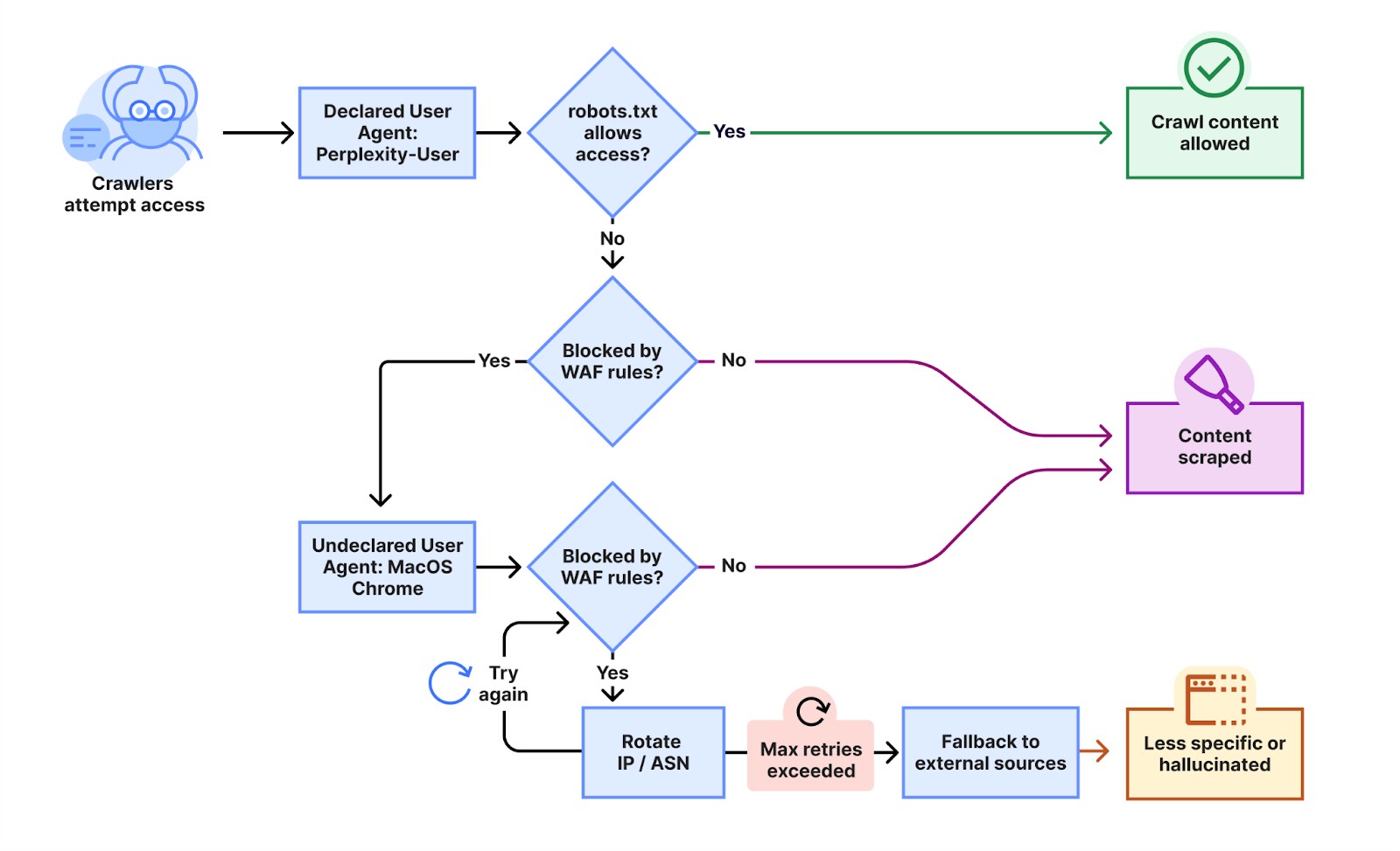
The recent conflict erupted after Cloudflare customers complained that Perplexity was still scraping their sites despite implementing both robots.txt directives and specific firewall rules to block the AI company's declared crawlers. Cloudflare engineers Gabriel Corral, Vaibhav Singhal, Brian Mitchell, and Reid Tatoris confirmed in tests that "Perplexity's crawlers were in fact being blocked on the specific pages in question."
To test Perplexity's behavior, Cloudflare created multiple newly purchased domains with restrictive robots.txt files that prohibited all automated access. "We conducted an experiment by querying Perplexity AI with questions about these domains, and discovered Perplexity was still providing detailed information regarding the exact content hosted on each of these restricted domains."
What happened next surprised them. Rather than respecting the blocks, Perplexity appeared to switch tactics. "We observed that Perplexity uses not only their declared user-agent, but also a generic browser intended to impersonate Google Chrome on macOS when their declared crawler was blocked," the engineers wrote.
Source: Cloudflare
The stealth crawlers employed sophisticated evasion techniques. "This undeclared crawler utilized multiple IPs not listed in Perplexity's official IP range, and would rotate through these IPs in response to the restrictive robots.txt policy and block from Cloudflare. In addition to rotating IPs, we observed requests coming from different ASNs in attempts to further evade website blocks."
According to Cloudflare, Perplexity's “declared” crawlers—the ones that are easily identifiable—generate 20-25 million requests daily, while the undeclared stealth crawlers—those which rely on shady tactics to hide their purpose—add another 3-6 million requests per day. "This activity was observed across tens of thousands of domains and millions of requests per day."
The company did not respond to Decrypt's request for comment. A spokesman dismissed the allegations to TechCrunch as nothing more than a Cloudflare “sales pitch.”
Cloudflare CEO Matthew Prince has been vocal about what he sees as AI companies' unsustainable extraction of web content. "Search traffic referrals have plummeted as people increasingly rely on AI summaries." In July, he revealed devastating ratios: while Google sends one visitor for every 18 pages it crawls, AI companies are far worse. OpenAI's ratio deteriorated from 250-to-1 six months ago to 1,500-to-1 today. Anthropic's numbers are even more extreme, jumping from 6,000-to-1 to 60,000-to-1 in the same period.

Source: Cloudflare
This prompted Cloudflare to launch what it calls "Content Independence Day," defaulting to blocking AI crawlers for all new domains, becoming the de-facto vigilante protecting content creators from the threats of pesky AI crawlers.
As Decrypt previously reported, more than a million websites had already opted into blocking since last fall, with major publishers including the Associated Press, Time, The Atlantic, BuzzFeed, Reddit, Quora, and Universal Music Group joining the movement.
"There are clear preferences that crawlers should be transparent, serve a clear purpose, perform a specific activity, and, most importantly, follow website directives and preferences," Cloudflare stated. The company contrasted Perplexity's behavior with OpenAI, which it said properly respects robots.txt files and stops crawling when blocked.
Cloudflare's response includes both immediate technical measures and longer-term initiatives. The company has deployed signature matches for the stealth crawler into its managed rules, available to all customers including free users. It's also developing tools like an "AI Labyrinth," which traps non-compliant bots in mazes of fake content, and a "pay-per-crawl" marketplace that would allow publishers to charge AI companies for access to their content.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






