Original Author: Yi Haotian
In the wave of AI, how can lawyers truly utilize AI without violating their confidentiality obligations? Client contracts cannot be directly pasted into ChatGPT, otherwise, they may face disciplinary actions? This article introduces my setup from the perspectives of lawyers' confidentiality duties, precautions, and the selection of AI service providers.
Lawyer's Confidentiality Obligations
1. China: Article 33 of the Lawyer Law
First is the well-known Article 33 of the Lawyer Law of the People's Republic of China, which stipulates:
“Lawyers shall keep state secrets and commercial secrets known during their practice confidential and shall not disclose clients' privacy. Lawyers shall keep confidential the information and circumstances that clients and others do not wish to be disclosed that they have become aware of during their practice.”
The confidentiality obligation under Chinese Lawyer Law rises to the level of criminal liability. Article 309 of the Criminal Law stipulates the crime of disclosing information on cases that should not be made public. Furthermore, Article 38 of the Measures for the Administration of Lawyers' Practice explicitly prohibits lawyers from disclosing commercial secrets and personal privacy known during their practice.
Currently, local bar associations and the Ministry of Justice have not provided more detailed guidelines on lawyers' use of generative AI. Therefore, we can refer to the requirements set by our American counterparts.
2. USA: ABA Model Rule 1.6 and NY RPC Rule 1.6
If you hold a New York state license (or any U.S. state license), a lawyer's confidentiality obligation concerning client information is not only a matter of professional ethics but an enforceable disciplinary rule.
New York Professional Conduct Rule 1.6 stipulates:
"A lawyer shall not knowingly reveal confidential information... unless the client gives informed consent."
The scope of “confidential information” is extensive—not limited to court secrets but covering all information known to lawyers during representation, including client names, addresses, financial data, transaction terms, business strategies, regardless of the source of information.
More importantly, Rule 1.6(c) states:
"A lawyer shall make reasonable efforts to prevent the inadvertent or unauthorized disclosure of, or unauthorized access to, information relating to the representation of a client."
This means: We not only cannot actively disclose client information, but we must also take reasonable measures to prevent disclosure.
In July 2024, the ABA officially released Formal Opinion 512—the first comprehensive ethical guideline concerning the use of generative AI by the American legal community. This opinion explicitly states:
Before inputting information related to client representation into (generative AI) tools, lawyers must evaluate the possibility of that information being “disclosed to or accessed by” other individuals inside or outside the tool.
Opinion 512 likens AI tools to cloud computing services and requires lawyers to:
- Investigate the reliability, security measures, and data processing policies of the AI tools used
- Ensure that the configuration of the tools protects confidentiality and security
- Confirm that confidentiality obligations are enforceable (e.g., contractual obligations)
- Monitor for violations or changes in provider policies
In simple terms: We cannot directly paste client contracts into ChatGPT unless we have conducted thorough compliance assessments.
This means, regardless of which legal jurisdiction we practice in, confidentiality obligations are an inviolable bottom line.
3. Why does AI complicate confidentiality obligations?
When we input client contracts into consumer-grade AI applications (like ChatGPT, Claude, Kimi, etc.), the text is transmitted to third-party servers. Even if providers claim they will not use data to train their models, the following risks still exist:
- Data Transmission: Client PII (Personally Identifiable Information) leaves our control and enters third-party infrastructure
- Training Risk: Consumer-level products may use the input for model training (need to carefully review service agreements)
- Violation Exposure: We now rely on the providers' security measures to fulfill our own ethical obligations
- Audit Gaps: We cannot verify what happens to the data after transmission
- Informed Consent: Obtaining client consent for each AI interaction is practically unfeasible
Most lawyers either completely refrain from using AI (losing competitive advantage) or adopt a “we'll see later” approach (risking disciplinary actions). Neither option is a good answer. I will discuss the relevant precautions in detail in the third section.
OpenClaw: How to Take the First Step?
1. What is OpenClaw?
OpenClaw is an open-source multi-agent AI assistant platform. In simple terms, it is an “AI gateway” running on our own hardware, capable of managing multiple AI assistants (agents) simultaneously, each with independent roles, memories, and tools.
2. Core Functions
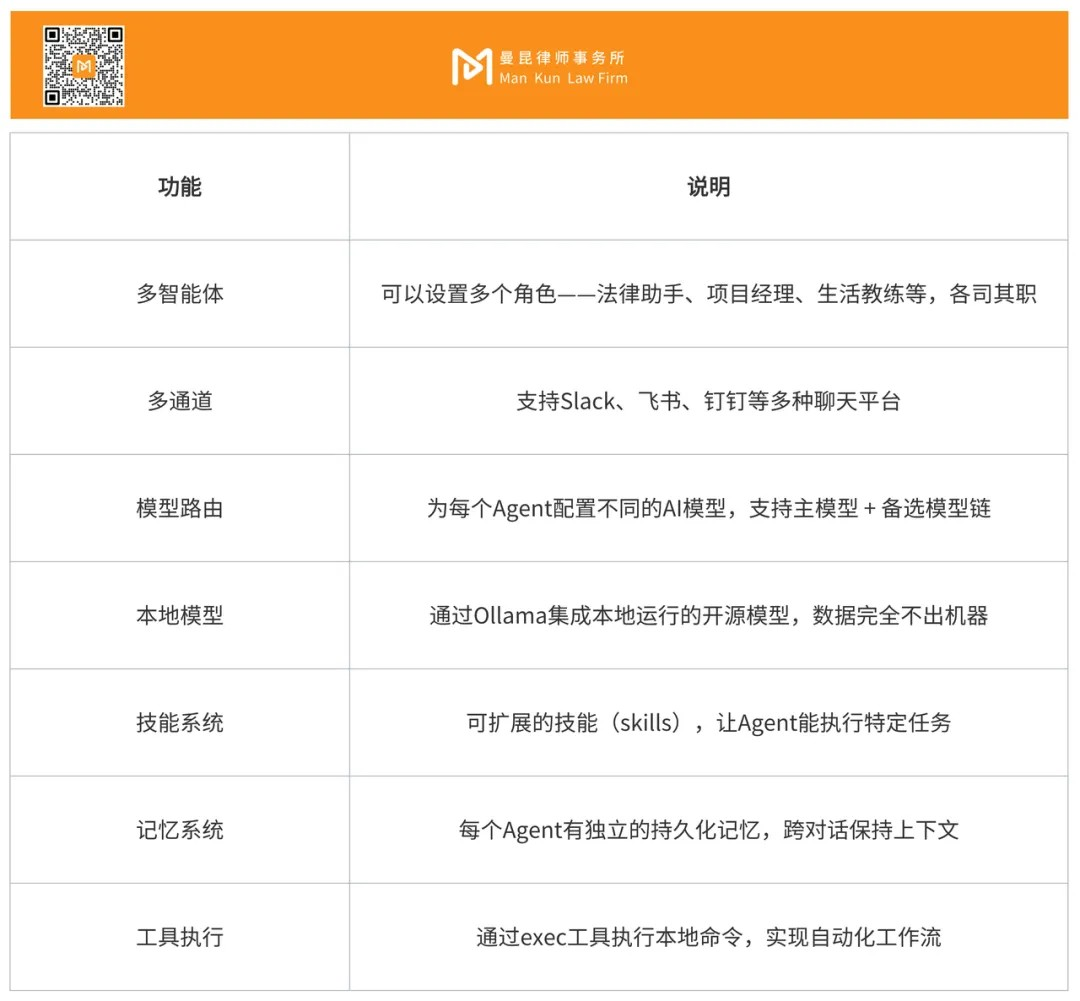
3. How Does It Work?
OpenClaw operates as a “gateway” on our local devices:
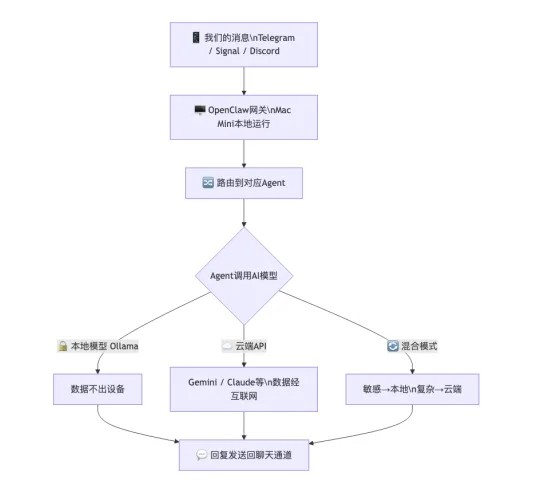
OpenClaw itself is free and open-source, but we need:
- A running device.
Any unused computer or Mac Mini is fine. However, I recommend using a Mac primarily because the current OpenClaw ecosystem is primarily built around Mac/Linux, although many are developing a Windows version, but at this stage, Mac will be more stable.
Rent a VPS from service providers like Alibaba Cloud or Tencent Cloud. Recently, Kimi's official release of one-click deployment for OpenClaw allows for low-cost trials of OpenClaw, which can be a good starting point.
- API keys for AI models (if using cloud models)
You can choose to purchase directly from LLM cloud service providers like Google Gemini, Alibaba Cloud, The Dark Side of the Moon, etc. Purchasing an API from the developer, besides pricing, has the advantage that some cloud service providers offer Batch API. For some large, but non-urgent tasks, the cloud services provide a 50% discount for providing answers after 24 hours.
The second option is large model aggregation platforms (LLM Aggregators), such as OpenRouter, Silicon-based Flow. The advantage of these cloud service providers lies in their unified interface, offering multiple LLM choices and routing features, allowing for automatic conversion between different LLMs.
Or locally install Ollama+ open-source models (if you don't want to rely on the cloud), this can be freely selected based on your host configuration.
4. Why Do I Use Mac Mini?
- Local operation and production environment isolation: An independent computer ensures OpenClaw won't accidentally delete my important work files. Of course, renting a VPS can also achieve physical isolation. However, VPS systems are typically Linux-based and cloud-based, and the user experience is not as smooth as local operation. For tasks that require an excellent network environment, a VPS is still a good option. Moreover, rented VPS typically have low configurations; if you need to rent high configurations, the cost can be significant.
- Apple Silicon unified memory: The unified memory architecture of the M4 chip allows large AI models to be directly loaded into memory for operation, eliminating the need for expensive GPUs. The unified memory architecture merges the common graphics memory + flash storage in Windows into one. This flexibility in calling during the operation of large models is cheaper than buying a separate graphics card.
- 32GB memory: Sufficient to run a 35B parameter MoE model (like Qwen 3.5 35B), with an inference speed of around 18 tokens/second
- Extremely low power consumption, compact size, very low noise: The Mac Mini's standby power consumption is about 5W, and running an AI model at full load is about 15-30W; the monthly electricity cost for running 24/7 is less than 10 yuan. The new Mac Mini is only the size of a palm and can be placed on a shelf or in the corner of a desk. Even under full load, the noise level is very low.
What Should Be Paid Attention to in Confidentiality Work?
When we use OpenClaw or any AI tools for legal work, we need to pay attention to confidentiality at three levels.
1. Confidentiality of Communication Channels
The communication channel between us and the AI assistant is the first line of defense.

I recommend that legal work involving high confidentiality should first use end-to-end encryption software as the communication channel. Some people may ask, clients often contact me via WeChat, right? Indeed, if clients initiate contact via WeChat, then there is an implied consent here. That is, the client agrees to use WeChat as the information transmission channel. If we transfer clients' confidential information through non-encrypted channels on our own accord, then at the very least, we should obtain the client's written consent first.
2. Selection of API Providers: Cost vs. Confidentiality
This is the most critical and often overlooked issue.
- Coding Plan
In recent years, domestic cloud providers have launched highly attractive “coding plans”: providing API access to top models at extremely low prices.
Taking Alibaba Cloud's Bai Lian as an example:
- Lite Package: First month ¥7.9, second month ¥20, thereafter ¥40/month
- Pro Package: First month ¥39.9, second month ¥100, thereafter ¥200/month
- Included models: Qwen3.5-Plus, Kimi K2.5, GLM-5, MiniMax M2.5
The prices are indeed enticing. Moreover, with a subscription model, there is no worry about exceeding API costs. But please pay attention to the following statement in Bai Lian's Coding Plan data policy:
“During the use of the Coding Plan, model inputs as well as contents generated by the model will be used for service improvement and model optimization.”
This means: All the content we input, including legal documents that may contain client information, will be used for model training and optimization. This directly violates confidentiality obligations for lawyers.
- Key Information to Consider When Choosing an API
Since the Coding Plan cannot handle confidential information (of course, the purpose of the cloud service provider launching the Coding Plan is not for us to handle confidential information), directly purchasing API tokens or becoming a preferential option. When selecting AI model APIs, lawyers must review the following points in the service contract:
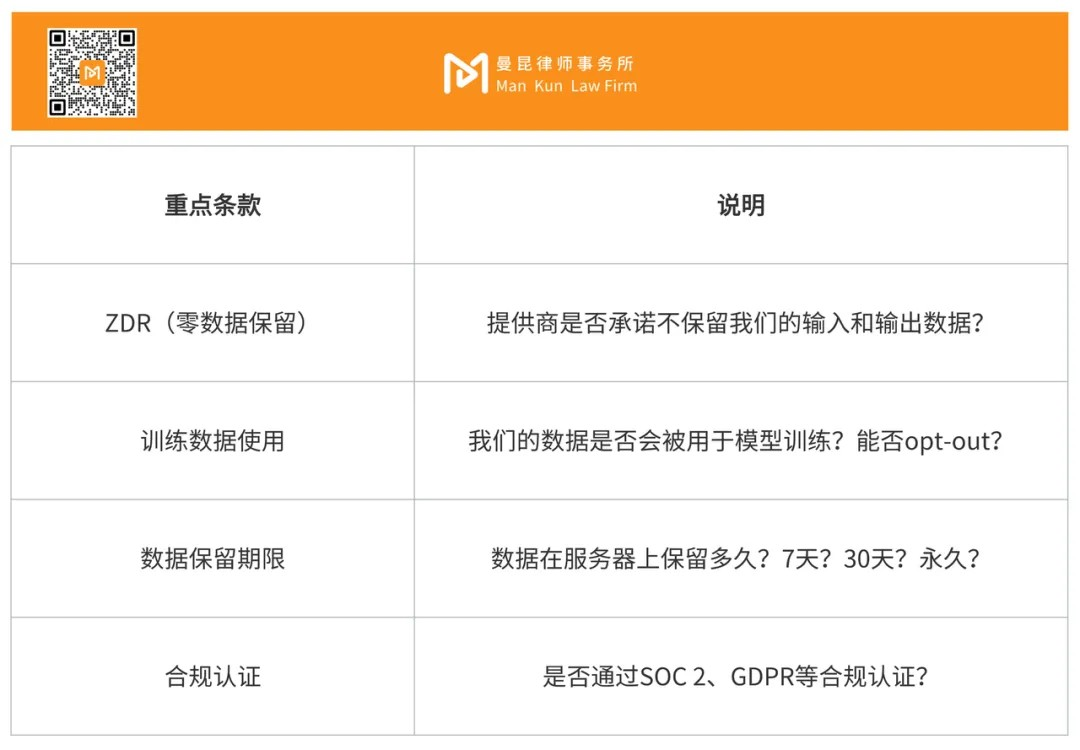
- Comparison of Major API Providers
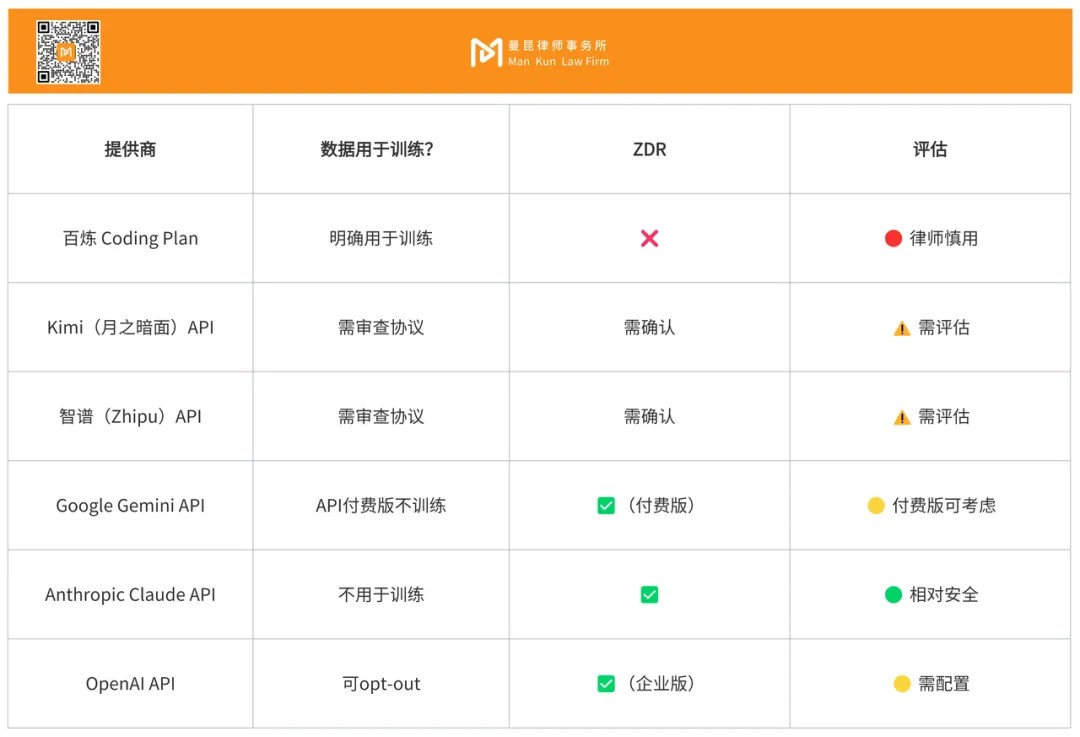
It is important to emphasize that even if API providers claim ZDR and do not use the data for training, lawyers still cannot fully verify the execution of these commitments. I doubt that cloud service providers grant personal users the authority to audit. Referring back to ABA Opinion 512, lawyers should investigate the security measures of AI tools and confirm the execution of confidentiality. If we cannot audit the execution of confidentiality measures, then I believe the API does not meet the requirements of Opinion 512. LLM is a black box, and we cannot confirm what happens to our data after transmission.
3. The Safest Option: Local Models
If we have the highest confidentiality requirements, running models locally is the only solution that can 100% ensure data leakage does not occur.
Advantages:
• Data never leaves the device, 100% privacy
• No API costs, no usage limitations
• No reliance on the network, available anytime
• Not affected by provider policy changes
Disadvantages:
• Inferior inference speed (18 tok/s vs cloud 100+ tok/s)
• Model capabilities are weaker than cutting-edge cloud models (GPT-4o, Claude Opus, etc.)
• Requires hardware investment
• Context window limited by memory
Recommended Local Model:
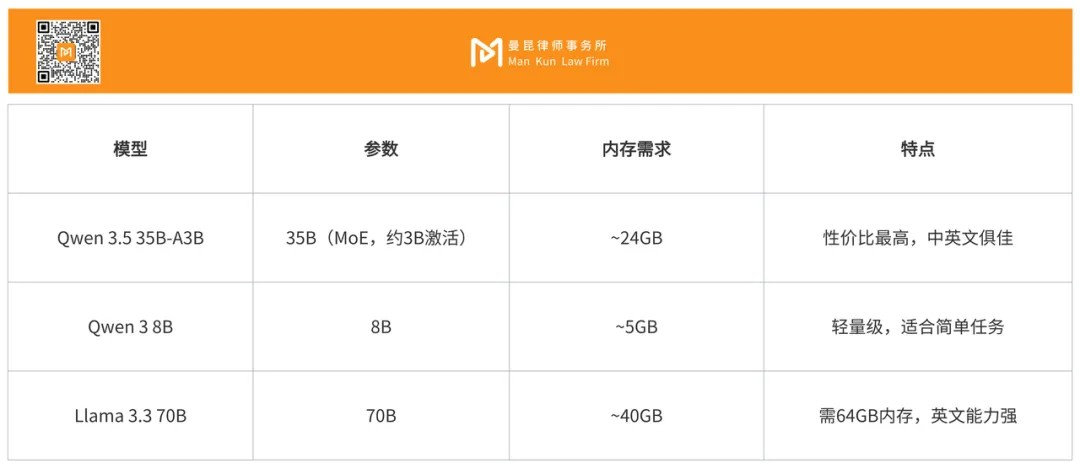
Note: MoE (Mixture of Experts) is a model architecture, although the total parameters are 35B, only about 3B parameters are activated during each inference, significantly reducing computation and memory requirements. This is why a 35B model can run smoothly on a 32GB Mac Mini.
My Configuration
As I am a practicing lawyer in New York, the following is the actual configuration of OpenClaw I built according to Opinion 512.
1. Communication Channel
Signal (end-to-end encryption) serves as the main channel for legal work. All conversations with the legal Agent (Counsel) are conducted through Signal, ensuring complete encryption at the communication level. Daily non-confidential work is conducted via Telegram.
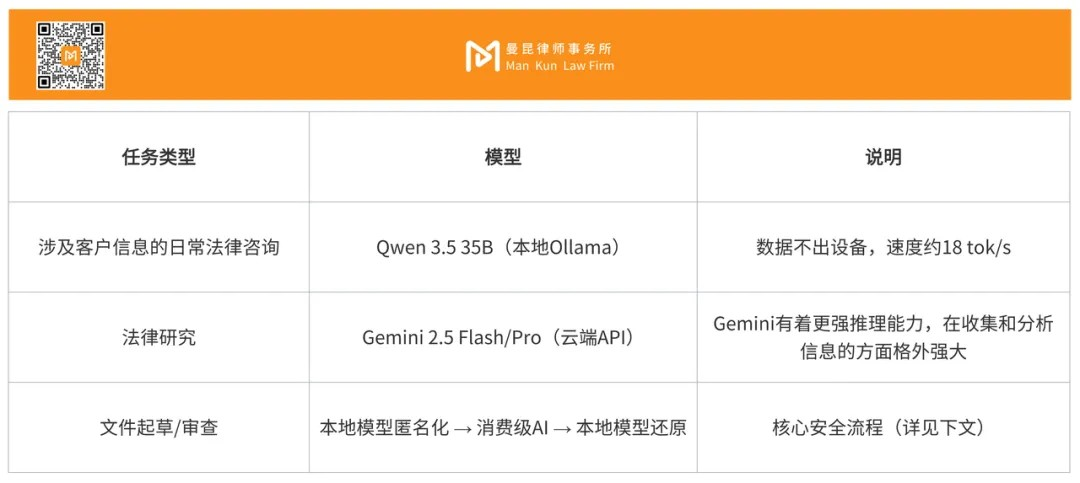
2. Model Configuration
I adopt a mixed model strategy:
3. Core Security Process: Anonymization Pipeline
This is the most important part of the entire configuration. When I need to draft or review sensitive documents using powerful cloud AI:
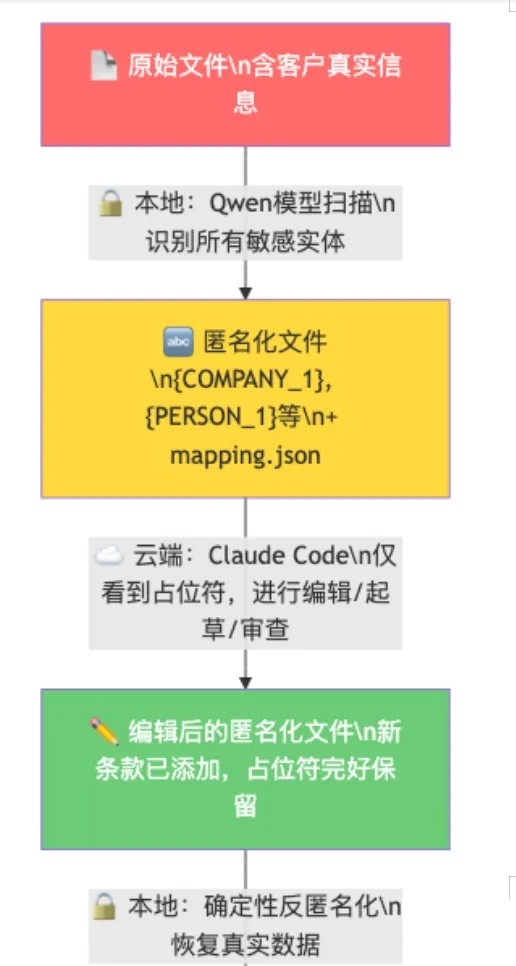
Key Point: mapping.json (mapping table of real data to placeholders) will never leave our device. The cloud AI only sees “{COMPANY_1} acquires 30% stake in {COMPANY_2}”—it does not know and cannot know who the actual parties are.
4. Why Choose Claude Code as a Consumer-grade AI Editing Tool?
- Subscription model: Max plan $100/month or $200/month, which is more economical compared to pay-per-use API
- Latest and most powerful model: Subscription users can directly use the latest released models (like Claude Opus 4)
- Comparison with API Pricing: Claude API input $3/million tokens, output $15/million tokens. Reviewing a complex contract may consume millions of tokens, and pay-per-use pricing would far exceed subscription costs. If price is not a consideration for you, using Opus's API directly after encryption would provide a smoother experience, though it would be more expensive. Based on my current token consumption, if I were to use only the Claude API, it would cost approximately $500+ monthly.
This solution fundamentally meets all the requirements of ABA Formal Opinion 512, as the cloud AI has never received confidential information.
5. Hardware Configuration
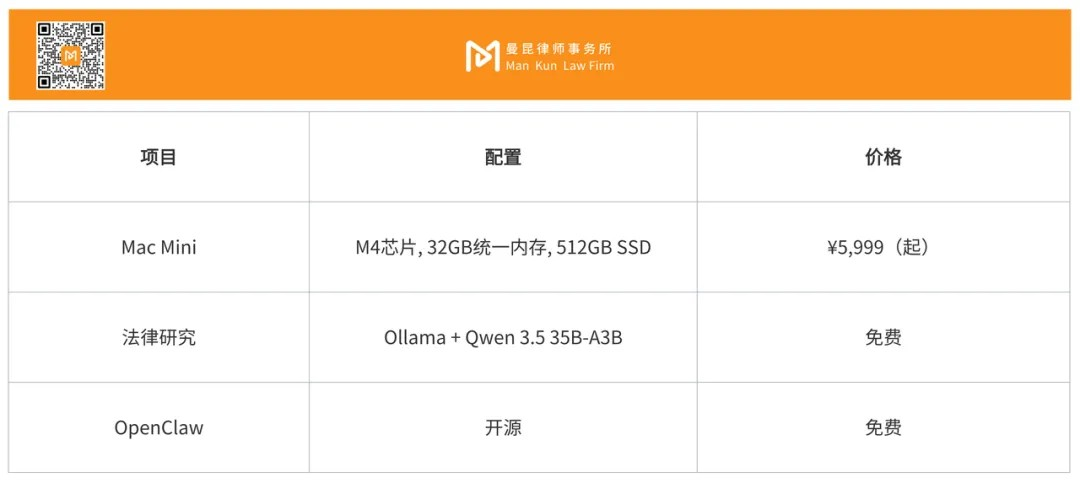
6. Cost Calculation
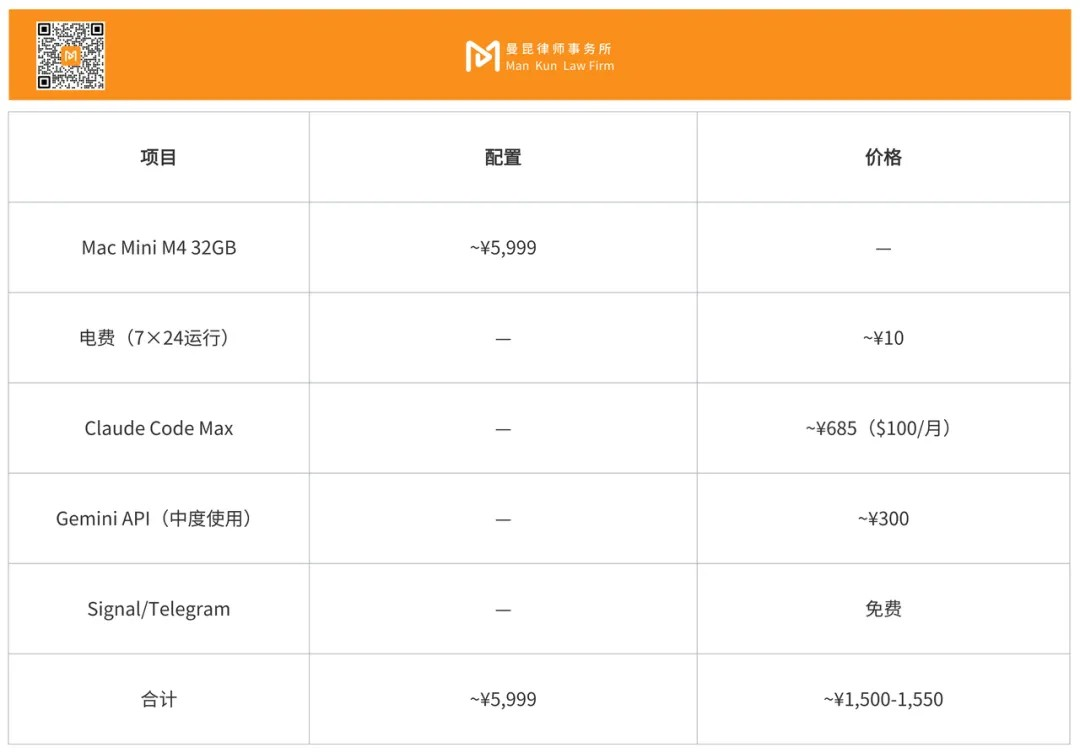
In comparison, the price of enterprise-level legal AI platforms like Harvey AI is $1,000-1,200 per user per month (approximately ¥7,200-8,600), and typically requires at least 20 seats.
7. Open Source Project
I have open-sourced this configuration and workflow on GitHub:
VibeCodingLegalTools(https://github.com/Reytian/VibeCodingLegalTools)—Rule 1.6-compliant AI workflow for legal practice
The project includes:
Complete anonymization/de-anonymization tools (LDA)
- OpenClaw configuration template
- Agent workspace template
- Client memory system template
- Detailed ethical compliance analysis
My Thoughts on Legal AI
1. Complete Localization Is Ideal, but Currently Unrealistic
In an ideal world, lawyers should run AI completely locally—all data stays on their devices, with zero leakage risks. But the reality is:
- Model Capability Gap: There is a significant capability gap between locally runnable models (35B parameter level) and cutting-edge cloud models (trillion parameter level). For simple legal consultations and information retrieval, local models are sufficient. However, for complex contract drafting, multi-round legal reasoning, and high-quality text generation, local models still do not perform well enough.
- Hardware Costs: To run truly powerful local models (like 70B+ parameters), you need 64GB or even more memory, and hardware costs quickly rise. For independent practitioners and small firms, this is not economically viable.
- Model Update Delays: The update speed of open-source models is always slower than that of commercial cutting-edge models.
2. Complete Reliance on the Cloud Also Has Issues
On the other hand, complete reliance on cloud APIs is not a solution either:
Even if API providers promise ZDR (zero data retention) and do not use data for training, it is virtually impossible for lawyers to investigate any suspicious leak.
LLM is a black box. We cannot open it to check whether our data has been used for training. We can only trust the provider's promises.
As lawyers, “trusting” is not a compliance strategy. Rule 1.6 requires “reasonable efforts”——not reasonable trust.
3. Mixed Models Are the Optimal Solution at Present
This is why I choose a mixed model strategy:
1. Daily Consultations → Local Models: Simple legal questions, information retrieval, preliminary analyses are all done locally
2. Complex Tasks → Cloud APIs: Use trusted APIs when stronger reasoning capabilities are needed, but avoid transmitting sensitive information
3. Sensitive Documents → Anonymization Pipeline: When cloud AI is needed to handle confidential documents, first anonymize locally, then hand them over for cloud processing, and finally restore locally
The core idea of this solution is to use technical means (anonymization) to fill the trust gap. We do not need to trust any AI provider to properly safeguard our client data because they have never received client data.
The cloud AI will only ever see “{COMPANY_1}” and “{PERSON_1}”, not our clients' real names.
Conclusion
AI will not replace lawyers. However, lawyers who utilize AI will ultimately replace those who do not.
The key is not whether to use AI, but how to use it. Confidentiality obligations are the cornerstone of legal practice; they should not become barriers to our adoption of AI, but rather be the standard for choosing AI solutions.
What does legal AI sell? I believe there are two things:
1. Knowledge;
2. Tools.
I believe all lawyers already have enough knowledge; they just need a more suitable tool. When the price of a Mac Mini is less than a month's subscription fee for Harvey AI, setting up a compliant tool may be a more practical choice for independent lawyers.
A Mac Mini, an OpenClaw setup, and an encrypted communication pipeline are all that make up a compliant AI legal workstation.
This article does not constitute legal advice. Lawyers should assess the workflow described herein according to the specific ethical rules of their jurisdiction and seek professional ethical guidance when necessary.
References:
- ABA Model Rules of Professional Conduct, Rule 1.6
- ABA Formal Opinion 512 — Generative Artificial Intelligence Tools (2024)
- Lawyers Law of the People's Republic of China (2017 Revision)
- OpenClaw (https://openclaw.ai/)
- VibeCodingLegalTools—GitHub (https://github.com/Reytian/VibeCodingLegalTools)
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。




