Source: Geek Park
Written by: Xu Shan
“I am convinced that this is a feast of technology. Every one of you present today represents the NVIDIA ecosystem.” At the opening of the 2026 GTC, the man who always wears a black leather jacket—Jensen Huang—stepped on stage with his signature confidence.

Unlike previous years, this year marks the 20th anniversary of the CUDA ecosystem. Right from the start, Huang explained how NVIDIA built its own moat step by step from Geforce to ray tracing, and then to AI agents. “Now the CUDA ecosystem has formed a data flywheel.” From his narration, we can see how the CUDA ecosystem he created has achieved a commercial empire.
At this launch event, Huang brought the Vera Rubin, specifically designed for AI agents, with a computing power of 3.6 exaflops. Combined with the latest rack introduced, the throughput of the latest computing power per megawatt has increased by 35 times. In addition, he also launched a CPU designed for extremely high single-thread performance—Vera CPU.
More importantly, NVIDIA also launched an enterprise-level OpenClaw reference solution, NemoClaw. You can directly download, use, and further develop it, and connect it to all SaaS companies worldwide. In comparison, this year NVIDIA has placed less emphasis on robots, autonomous driving, and quantum computing in the keynote speech.
After watching this presentation, you will have a premonition: we are standing at the starting point of a new computing platform revolution. Just like the emergence of Google and Amazon in the last round of transformation, in this round of AI explosion, a batch of world-changing “AI giants” is being incubated.
The long list of companies that Huang holds in every session is his confidence. He is not just defining computing; he is leveraging AI as a fulcrum to forcibly draw global finance, healthcare, manufacturing, and retail into a GPU-dominated “AI era.”
Once again, NVIDIA has seen the future of AI, and now he is pulling the whole world to jump into it.
01 Vera Rubin: 7 breakthrough chips, 5 rack-level systems, 1 supercomputer
Entering the AI Agent era, NVIDIA introduced Vera Rubin. It is designed for the entire lifecycle of AI agents, redefining the CPU, storage, network, and security needed for AI agents at the chip level.
In terms of specifications, Vera Rubin features NVLink 6, achieving a total computing power of 3.6 EFLOPS, serving as a key engine driving the AI agent era. Moreover, compared to the previous generation, the Vera Rubin system achieves 100% liquid cooling, eliminating all traditional cabling.
In terms of overall configuration, the Vera CPU rack is currently designed for orchestration and general workloads. The STX rack is built on BlueField-4 for AI-native storage. Leveraging Spectrum-6 co-packaged optical technology allows horizontal scaling, significantly improving efficiency and reliability.

Meanwhile, the Groq 3 LPX rack deeply connects with Vera Rubin, and the Groq LPU integrates 230MB of on-chip SRAM, further enhancing the overall computation speed of Vera Rubin.
Altogether, each megawatt of computing power achieves a throughput increase of 35 times. Undoubtedly, the Vera Rubin platform, equipped with seven chips and five major rack-level computers, creates a revolutionary AI supercomputer geared towards general intelligence.
When discussing the product design philosophy, Jensen Huang believes that large language models will become larger, generating more and faster tokens to enable quicker thinking. However, at the same time, they must frequently access memory, putting immense pressure on memory, including KV caches, structured data QDF, unstructured data QVS, etc., thus imposing extremely high demands on storage systems. Therefore, the storage systems of the AI era need to be rewritten.
In the Agentic era, AI will also use various tools and require high speeds for web browsers and virtual PCs. Therefore, these PCs and computing nodes must be faster. NVIDIA has developed a new CPU Vera CPU, specifically designed for extremely high single-thread performance, featuring high data output capabilities, strong data processing efficiency, and excellent energy efficiency. It is said to be the only data center CPU in the world adopting LPDFR5X, maximizing both single-thread performance and cost-effectiveness per watt.

The Vera Rubin All-Inclusive Series | Source: NVIDIA
“We designed this CPU to work in coordination with the entire rack, supporting agents in processing tasks. This product is already in mass production. We never imagined we would sell CPUs individually, but now our independent CPU sales are quite impressive. This will undoubtedly become a multi-billion dollar business for us. I am very satisfied with our CPU architecture team,” said Huang.
Huang also demonstrated Rubin Ultra on site. Unlike the standard horizontal insertion of Rubin, Rubin Ultra uses a brand new Groq rack with a vertical insertion. “This Groq rack is very heavy; I definitely cannot lift it, so I won’t try.”

Groq Rack | Source: NVIDIA
On the back of the midplane, NVIDIA has moved away from traditional copper cables. He believes that copper cables have limitations in transmission distance, and instead, this new system connects 144 GPUs. This is the new generation of NVLink. It also installs vertically, connecting to the back of the midplane. The front end is computing, and the back end is the NVLink switch, combined into a giant computer.
Returning to the question, what substantial benefits can the new chip architecture bring? Huang mentioned that chips will ultimately affect the future market positioning and pricing of tokens.
“Tokens are a new commodity. Like all commodities, once they cross the inflection point and mature, they will stratify and tier.” He categorized future tokens as follows:
High throughput, low-speed version, suitable for free packages;
Mid-tier package, larger models, faster speeds, and longer input context lengths;
In the future, there may even be high-end flagship packages, supporting extremely high token generation speeds for critical path tasks or extremely long research scenarios. By then, $150 for every million tokens will also be completely reasonable.
“The larger the model, the higher the intelligence; the longer the input token context, the more accurately relevant the results; the faster the speed, the more comprehensively the thinking and iteration, the smarter the AI. The more intelligent the model, with each step up, the price can be adjusted accordingly. For example, it could be $45 for one tier.” He feels the consumption of future tokens will change everything.
In his scenario, if an investigator uses 50 million tokens daily, at $150 per million, it would be entirely acceptable for a research team. “This is the future of AI.” From the customer’s perspective, he hypothesizes reallocating all computing resources: 25% power used for free packages, 25% for mid-tier packages, 25% for high-end packages, and 25% for deluxe packages. If the total power consumption of the data center is only 1 gigawatt, then customers can decide how to allocate these resources, attracting more users with free packages, while the high-end packages serve the most valuable customers. These combinations ultimately determine your revenue.
Under this simple model hypothesis, he states that using the Blackwell platform can achieve 5 times the revenue growth compared to Hopper. Meanwhile, Vera Rubin can provide a 5 times revenue increase compared to Blackwell.

Vera Rubin | Source: NVIDIA
The Groq computing system is a deterministic data flow processor, utilizing static compilation and compiler scheduling architecture. This means that all timing arrangements, including when data is transmitted, when computations are executed, and how data synchronizes, will be statically planned in advance by the compiler without dynamic scheduling. This architecture is equipped with large-capacity HBM, designed primarily for the inference workload.
Currently, the Groq 3 LPU has entered the mass production stage, with shipments expected to commence in the second half of this year, around the third quarter, targeting the Groq LP product.
As for Vera Rubin, although the early sample debugging of Grace Blackwell was quite complex, requiring simulation of 72 interconnected links, the samples of Vera Rubin have already completed testing, and the first set of Vera Rubin racks is already online and operating normally on Microsoft Azure.
At present, NVIDIA is producing Vera Rubin racks and GB300 racks at full capacity, with a supply chain established to produce thousands of systems weekly.
NVIDIA’s next chip platform architecture is named Feynman architecture.
Moreover, both Groq and Vera Rubin will serve as core components of NVIDIA’s AI factory.
Groq has only 500MB of storage per chip; however, Rubin GPU chips will reach 288GB of HBM4 memory.
A trillion-parameter model will require storing all its parameters on Groq chips, necessitating a large number of chips to ensure storage space. But if placed alongside Vera Rubin, it can accommodate the massive KV cache required for AIGC systems.
Therefore, NVIDIA has restructured the resource allocation for AI inference—assigning the best-suited tasks to the most appropriate chips.
In Huang’s vision, processes like the attention part of the decoding phase within the model, which require extensive computation, can be completed on Vera Rubin; while the token generation part of decoding can be handled on Groq chips.
After tightly coupling with a special mode of Ethernet, these two chipsets can reduce the latency of Alpamayo by nearly half. With the help of NVIDIA’s Dynamo software for scheduling and integration, the Vera Rubin architecture combined with Groq LPU enhances high-level inference performance by 35 times.
02 NemoClaw: The Commercial Reference of AIOS
“OpenClaw is the most popular open-source project in human history, achieving this feat in just a few weeks. Its development speed even surpasses that of Linux back in the day.” Huang mentioned that OpenClaw can interact with any modality and understand it; it can send messages, texts, and emails. It possesses complete I/O capabilities.
“OpenClaw has open-sourced the operating system for agent computers. Just as Windows allowed us to create personal computers back in the day, OpenClaw now enables us to create personal agents.”
Huang believes that for every company, every software company, and every tech company CEO, the most critical question today is: what is your OpenClaw strategy?
“Just as we all need a Linux strategy, an HTTP, and HTML strategy—that opened the internet era; a Kubernetes strategy—that established the mobile cloud era. Today, every company in the world must have an OpenClaw strategy; that is, a strategy for intelligent systems. This is the new generation of computing.”
He believes that in the future, every enterprise's way of working, along with individuals' workflows and even salary payment methods, will change.
Before OpenClaw, the model for enterprise IT was “data centers,” because those large rooms and buildings housed data, people’s files, and structured data of enterprises. Data flowed through software with tools, recording systems, and various fixed workflows in IT, ultimately turning into tools for human and digital workers to use. In the old IT industry, software companies created tools and stored files, while IT consultants aided businesses in using and integrating these tools.
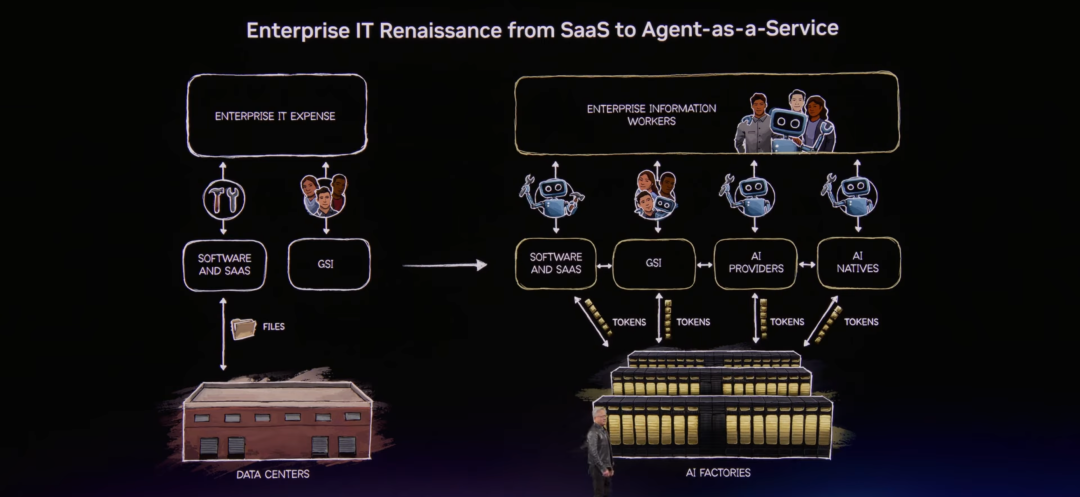
Future Enterprise Structure | Source: NVIDIA
But in the OpenClaw era, after the age of intelligent agents, every IT company, every enterprise, and everySaaS company will become an “Agent-as-a-Service” (AAS) company.
However, there remains a key issue that needs to be resolved—intelligent systems in enterprise networks can access sensitive information, execute code, and communicate externally. They could potentially acquire sensitive content such as employee information, supply chain data, and financial secrets, and transmit this data externally, raising security risks.
Subsequently, NVIDIA launched its own NVIDIA OpenClaw reference solution—Open NemoClaw.
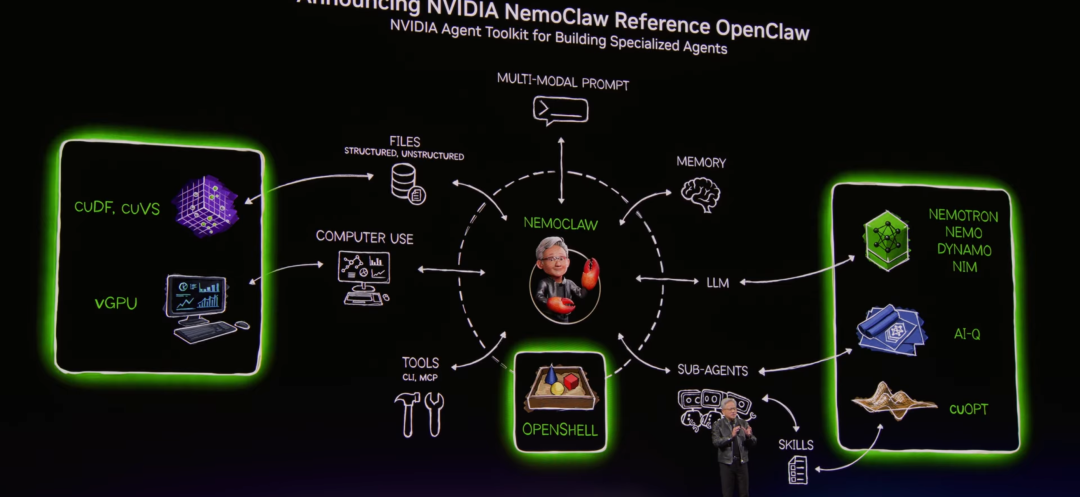
NemoClaw | Source: NVIDIA
It integrates a complete set of AI agent tools, with one of its core technologies being OpenShell’s module, which is now fully integrated into OpenClaw. Users can directly download, use, and further develop it and connect it with the strategy engines of SaaS companies worldwide.
Simultaneously, users can connect with these strategy engines to execute security policies, set up network firewalls, and run privacy routing to protect the internal enterprise environment, allowing agents to operate securely and controllably. Open NemoClaw also supports users in building custom agents using their exclusive models.
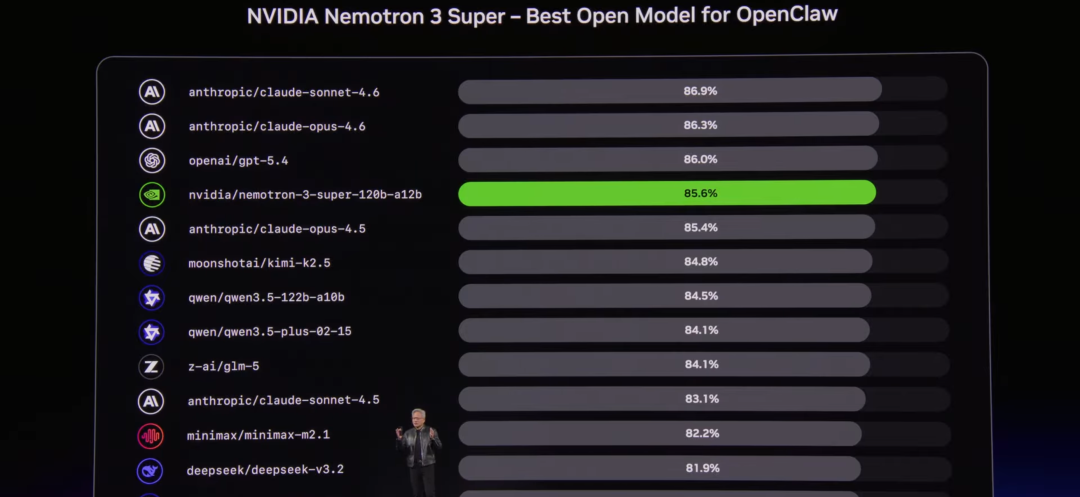
Ranking of NemoClaw equipped with NVIDIA models among OpenClaw-like products | Source: NVIDIA
He believes that one of the future hiring methods in Silicon Valley will be: “How much tokens does this job come with?”
At that time, an employee’s base annual salary could be hundreds of thousands of dollars, while companies might additionally provide half of their salary in tokens, amplifying their productivity by tenfold.
In the future, every software company will be driven by intelligent agents. They will become producers of tokens, users of tokens, and providers of tokens to all customers.
03 Physical AI: BYD and Geely join NVIDIA’s Robotaxi circle, Disney’s Olaf makes a surprise appearance
After discussing the changes at the application level, Jensen Huang shifted the focus to physical AI and showcased his physical AI family.

NVIDIA’s Physical AI Layout Family Photo | Source: NVIDIA
Currently, NVIDIA has three types of computers: those for training, those for data generation and simulation, and in-vehicle computers installed in robotic entities.
NVIDIA also announced a range of new partners. “The moment for self-driving ChatGPT has arrived. Now we are confident that vehicles can fully achieve successful autonomous driving,” Huang said.
NVIDIA announced that its autonomous taxi (Robotaxi) platform has added four new partners: BYD, Hyundai, Nissan, and Geely. These manufacturers collectively produce 18 million vehicles annually. Along with previously partnered companies like Mercedes, Toyota, and General Motors, the number of vehicles supporting Robotaxi in the future will be quite substantial. NVIDIA also announced that it will connect these supported Robotaxi vehicles to the operational networks of partners in multiple cities.
In the future, traditional radio towers will transform into NVIDIA Aerial AI RIM intelligent base stations. They will become “Robotaxi radio towers.” At that time, companies will be able to comprehend traffic conditions and intelligently adjust beam shaping to maximize fidelity while conserving energy.
He also mentioned that with NVIDIA Alpamayo, vehicles now possess reasoning capabilities, enabling them to drive safely and intelligently in various scenarios. We can allow vehicles to explain their decision-making processes and immediately comply with voice commands.
For example, we can say to the car: “Hey Mercedes, can we accelerate a bit?” The vehicle can respond: “Of course, I’m speeding up now.” By combining traditional simulation with neural simulation, they generate massive synthetic data and train strategic models on a large scale.
This time, NVIDIA has also developed multiple open-source tools: Isaac Lab: used for training and evaluating robots in simulation Newton: a scalable, GPU-accelerated differential physics simulation engine Cosmos World Model: used for neural simulation GR00T open-source robotic foundational model: used for robotic reasoning and action generation.
At the end of the keynote, Disney’s Olaf from Frozen robot took the stage. Disney’s robot is currently undergoing simulation training with NVIDIA. “Personally, one of the robots I’m most looking forward to is the one from Disney,” Huang remarked.

Jensen Huang waves goodbye with Olaf at GTC | Source: NVIDIA
This year, Jensen Huang has thrown out not just directions and slogans at GTC, but a complete set of tools that can be practically used by current AI entrepreneurs.
From AI chips, OpenClaw agent systems, to physical AI, robotics, and large-scale autonomous driving implementation. He has provided answers to the paths that the AI industry must take over the next few years, the hardest problems to solve, and the most painful bottlenecks. Every enterprise and every developer can find their place within this new framework.
From this year onwards, AI will no longer be about accumulating parameters, stacking computing power, or telling stories; it is moving towards enterprises, becoming practical. This may not just be a victory for a single company, but the flywheel of AI is starting to truly spin.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






