Author:Bassim Eledath
Translated by: Baoyu
The programming capabilities of AI are surpassing our ability to harness them. This is why all those frantic efforts to boost SWE-bench scores haven't aligned with the productivity metrics that engineering leadership truly cares about. The Anthropic team brought Cowork online in just 10 days, while another team using the same model couldn't even manage a single POC (Proof of Concept)—the difference lies in one team bridging the gap between capability and practice, while the other has not.
This gap won't disappear overnight but will gradually narrow in levels. There are a total of 8 levels. Most of the readers of this article have likely passed the first few levels, and you should be eager to reach the next one—because every level up means a huge leap in output, and each improvement in model capabilities further amplifies these returns.
Another reason you should care is the teamwork effect. Your output depends more on your teammates' levels than you might imagine. Suppose you are a level 7 expert, and while you sleep at night, your background agents help you prepare several PRs. But if your code repository requires a colleague’s approval to merge, and that colleague is still at level 2, manually reviewing PRs, then your throughput gets stuck. So helping your teammates level up benefits you too.
Through discussions with various teams and individuals about their practices in using AI-assisted programming, here is the advancement path I have observed (the order is not strictly defined):
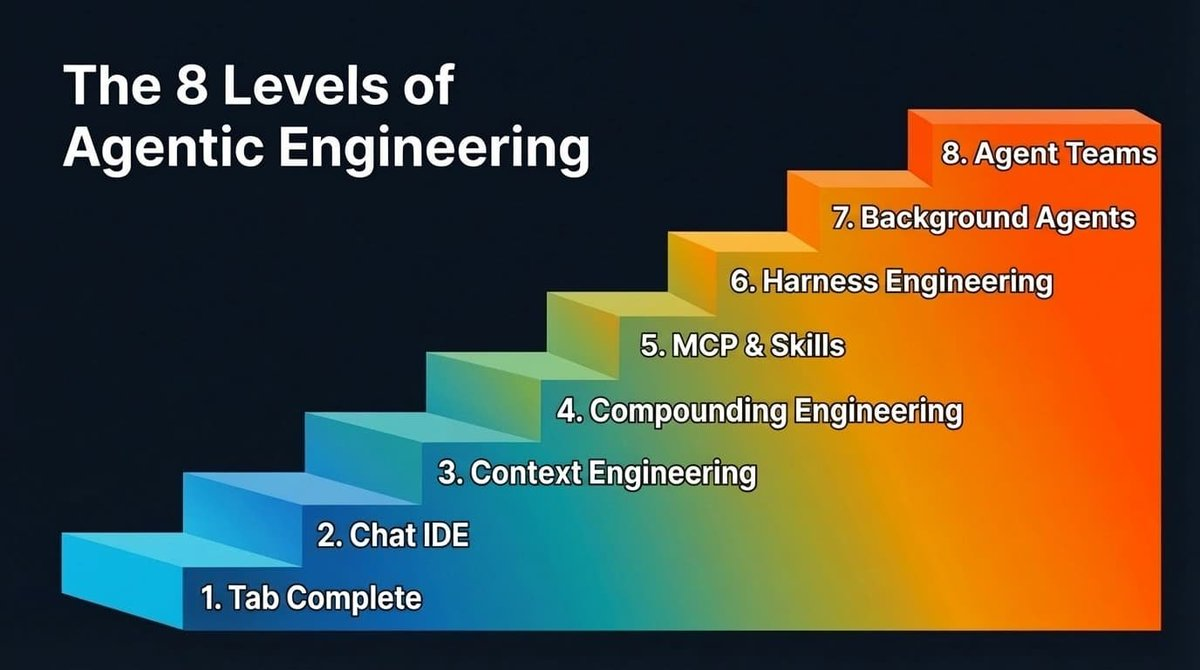
8 Levels of Agent Engineering
Level 1 and 2: Tab Completion and Agent IDE
These two levels I will briefly cover, mainly for completeness. Feel free to skim.
Tab completion is the starting point for everything. GitHub Copilot kicked off this movement—press the Tab key, and code is auto-completed. Many may have forgotten this stage, and newcomers might even skip it altogether. It’s better suited for experienced developers who can outline the code structure first and then let AI fill in the details.
AI-specific IDEs, like Cursor, have changed the game by connecting chat with codebases, making cross-file editing much easier. But the ceiling is still context. The model can only help you with what it can see, and what’s frustrating is that either it hasn't seen the right context, or it has seen too much irrelevant context.
Most people at this level are also trying the plan mode of their chosen programming agent: turning a rough idea into a structured step-by-step plan for the LLM, iterating on that plan, and then triggering execution. This works well at this stage and is a reasonable way to retain control. However, in the later levels, we will see a decreasing reliance on planning modes.
Level 3: Context Engineering
Now we enter the interesting part. Context Engineering is the buzzword of 2025, and it became a concept because models can finally reliably follow a reasonable number of instructions, paired with just the right amount of context. Noisy context is just as bad as insufficient context, so the core work lies in increasing the information density of each token. “Every token must fight for its position in the prompt”—this was the mantra at the time.
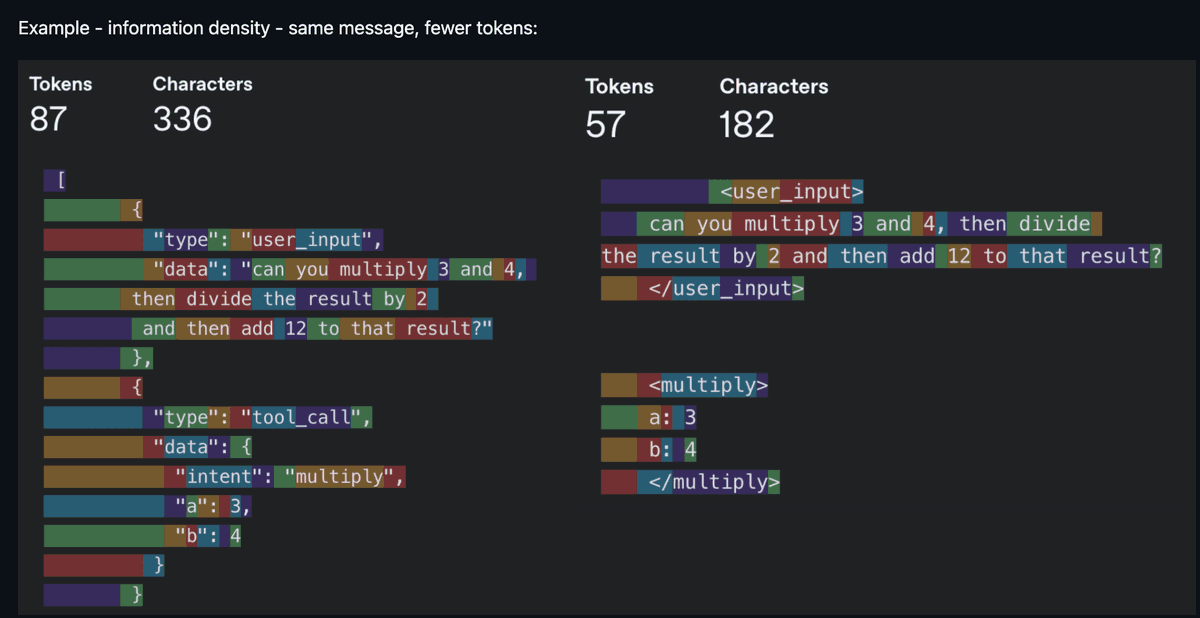
The same information, fewer tokens—information density is key (source: humanlayer/12-factor-agents)
In practice, the scope of Context Engineering is broader than most people realize. It includes your system prompt and rules files (.cursorrules, CLAUDE.md). It includes how you describe tools, as the model reads these descriptions to decide which tool to call. It includes managing conversation history to prevent long-running agents from losing direction after the tenth round of conversation. It also includes deciding which tools to expose in each round, as too many options can overwhelm the model—just like a human.
Nowadays, you don't hear the term Context Engineering as much. The balance has shifted towards models that can tolerate noisier contexts and continue to reason even in more chaotic scenarios (a larger context window helps too). But attention to context consumption is still important. In the following scenarios, it can still become a bottleneck:
- Small models are more sensitive to context. Voice applications often use smaller models, and context size is linked to first token latency, affecting response speed.
- Token hogs. MCP (Model Context Protocol) tools like Playwright and image inputs can quickly consume tokens, pushing you into "compressed session" mode in Claude Code sooner than expected.
- Agents with dozens of tools waste more tokens parsing tool definitions than doing actual work.
The broader point is: Context Engineering hasn’t disappeared; it has evolved. The focus has shifted from filtering bad context to ensuring the right context appears at the right time. And it is this shift that paves the way for Level 4.
Level 4: Compounding Engineering
Context Engineering improves the current session. Compounding Engineering (introduced by Kieran Klaassen) improves every subsequent session. This concept was a turning point for me and many others—it made us realize that “programming by feel” is far more than just prototyping.
This is a cycle of “plan, delegate, evaluate, refine.” You plan the task, giving the LLM enough context to succeed. You delegate the task. You evaluate the output. Then comes the critical step—you refine what you've learned: what worked, what went wrong, and what pattern to follow next time.
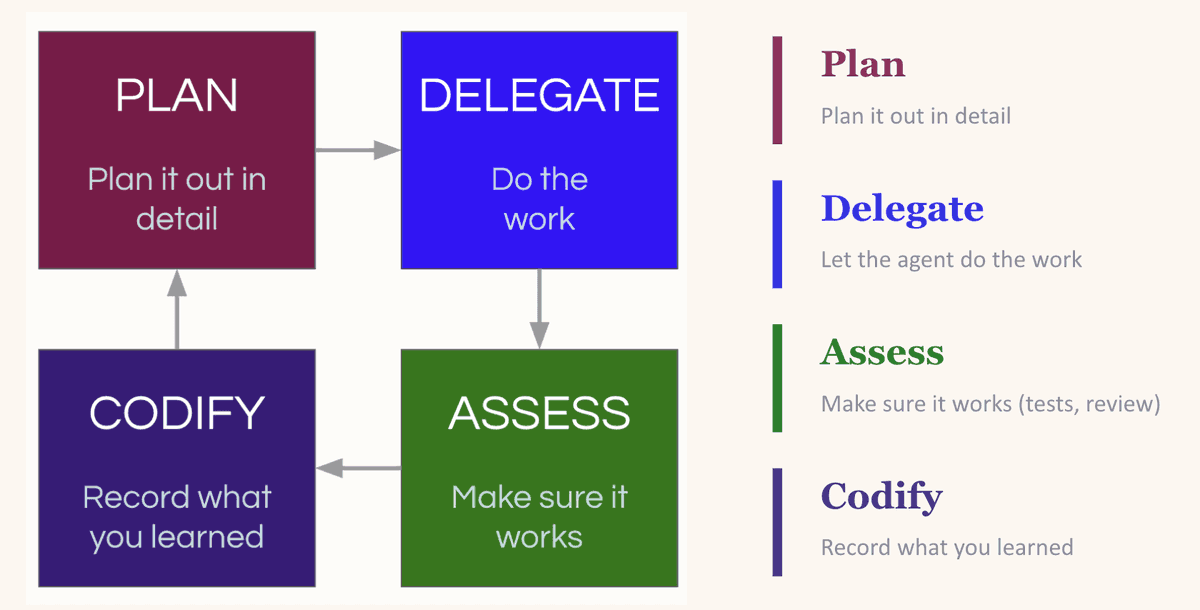
Compounding cycle: Plan, delegate, evaluate, refine—each round makes the next better
The magic lies in the “refine” step. LLMs are stateless. If it reintroduces a dependency that you explicitly removed yesterday, it will do so again tomorrow—unless you tell it not to. The most common solution is to update your CLAUDE.md (or equivalent rules file), codifying lessons learned into every future session. But beware: the impulse to stuff everything into the rules file can backfire (too many instructions equals no instructions). A better approach is to create an environment where the LLM can easily discover useful context on its own—like maintaining an updated docs/ directory (Level 7 will discuss this in detail).
Those practicing Compounding Engineering are typically highly sensitive to the context fed to the LLM. When the LLM makes a mistake, their instinctive reaction is to first consider whether the context was lacking rather than blame the model. It is this intuition that makes Levels 5 to 8 possible.
Level 5: MCP and Skills
Levels 3 and 4 address context issues. Level 5 tackles capability issues. MCP and custom skills enable your LLM to access databases, APIs, CI pipelines, design systems, as well as Playwright for browser testing and Slack for notifications. The model is no longer just thinking about your codebase—it can now interact with it directly.
There are already plenty of high-quality resources on MCP and skills, so I won't rehash what they are. But here are a few examples of how I use them: our team shares a PR review skill, which everyone iterates and improves together (still in progress), and it conditionally triggers sub-agents based on the nature of the PR. One checks integration security with the database, another performs complexity analysis to mark redundancy or over-engineering, and another checks prompt health to ensure prompts follow the team's standard format. It also runs linters and Ruff.
Why invest so much in review skills? Because when agents start to produce PRs in bulk, manual review becomes a bottleneck rather than a quality gate. Latent Space has made a compelling argument: the code review we know is dead. Instead, we have automated, consistent, skill-driven reviews.
Regarding MCP, I use Braintrust MCP to allow LLMs to query assessment logs and make direct modifications. I use DeepWiki MCP to let agents access documentation for any open-source repository without manually pulling the documentation into context.
When several people on the team start writing similar skills individually, it’s worth consolidating them into a shared registry. Block (with condolences) has a great article: they built an internal skills marketplace with over 100 skills and curated skill packages for specific roles and teams. Skills and code get the same treatment: pull requests, reviews, version history.
Another trend to note: LLMs are increasingly using CLI tools instead of MCP (and it seems every company is releasing its own: Google Workspace CLI and Braintrust is about to release one as well). The reason is token efficiency. MCP servers inject complete tool definitions into context in every round, regardless of whether the agent uses them. CLI does the opposite: the agent runs a targeted command, and only relevant output enters the context window. I predominantly use agent-browser instead of Playwright MCP, precisely for this reason.
Let's pause before continuing. Levels 3 to 5 are the foundation for everything that follows. LLMs are surprisingly good at some tasks and surprisingly bad at others; you need to cultivate an intuition for these boundaries before stacking more automation. If your context is noisy, prompts are insufficient or inaccurate, and tool descriptions are vague, then levels 6 to 8 will only amplify these problems.
Level 6: Harness Engineering
The rocket is truly taking off.
Context Engineering focuses on what the model sees. Harness Engineering focuses on building the entire environment—tools, infrastructure, and feedback loops—that allow agents to work reliably without your intervention. Agents are given not just an editor, but a complete feedback loop.
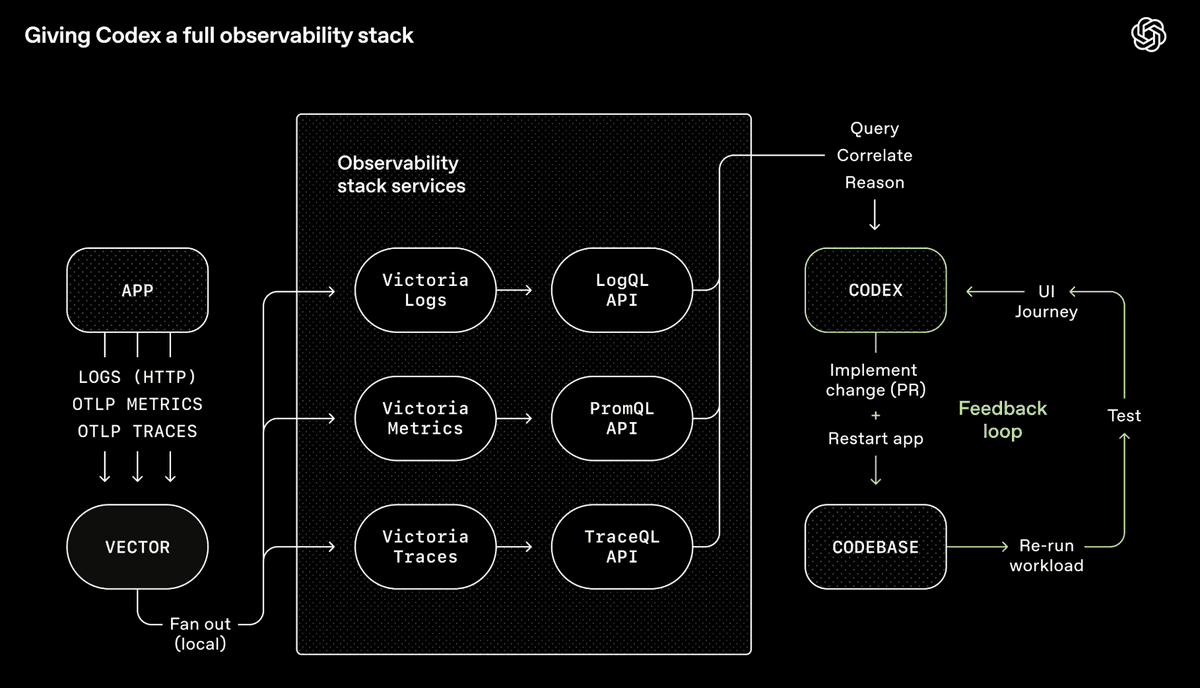
OpenAI’s Codex toolchain—a complete observability system that allows agents to query, associate, and reason about their outputs (source: OpenAI)
The OpenAI Codex team integrated Chrome DevTools, observability tools, and browser navigation into the agent runtime, allowing it to screenshot, drive UI flows, query logs, and validate its own fixes. Given a prompt, the agent can reproduce the bug, record a video, and implement a fix. It then verifies through manipulating the application, submits PRs, responds to review feedback, and merges—only escalating to humans when judgment is needed. The agent doesn't just write code; it can see what effect the code has produced, then iterate and improve—just like a human.
My team works with voice and chat agents for technical troubleshooting, so I created a CLI tool called converse, allowing any LLM to chat with our backend interface in round-based conversations. After the LLM modifies the code, it tests conversations in the online system using converse and iterates. Sometimes this self-improvement loop can run for hours. This is especially powerful when the results are verifiable: the conversation must follow this process or call those tools under specific conditions (like escalating to human support).
The core concept underpinning all this is backpressure—an automated feedback mechanism (type systems, tests, linters, pre-commit hooks) allowing agents to discover and correct mistakes without human intervention. If you want autonomy, you must have backpressure; otherwise, you get a garbage production machine. This extends to safety as well. Vercel's CTO points out that agents, the code they generate, and your keys should reside in different trust domains because a prompt injection attack buried in log files could entice the agent to steal your credentials—if everything shares the same security context. Safety boundaries are backpressure: they constrain what an agent can do when it goes rogue, not just what it should do.
Two principles that clarify this idea:
- Design for throughput rather than perfection. When demanding every submission to be perfect, agents will get stuck in a loop on the same bug, overwriting each other's fixes. A better approach is to tolerate minor non-blocking errors and perform a final quality check before release. We do this for our human colleagues too.
- Constraints are better than instructions. Step-by-step prompts (“do A first, then B, and then C”) are becoming outdated. In my experience, defining boundaries is more effective than listing items, as agents will fixate on the list and ignore everything outside it. A better prompt is, “This is the result I want; keep going until you pass all these tests.”
The other half of Harness Engineering is ensuring agents can navigate the code repository freely without you. OpenAI's approach is to keep AGENTS.md around 100 lines long, serving as a directory pointing to other structured documents, and to incorporate document timeliness into the CI process instead of relying on rapidly outdated ad-hoc updates.
Once you have built all of this, a natural question arises: If the agent can verify its own work, navigate the repository freely, and correct errors without you—then why do you still need to sit in the chair?
A reminder to friends still at the earlier levels: the upcoming content may sound very sci-fi (but it's okay, save it to review later).
Level 7: Background Agents
Hot take: the planning mode is dying.
Boris Cherny, the creator of Claude Code, still has 80% of tasks starting in planning mode. However, with each new generation of models released, the one-off success rate post-planning continues to climb. I believe we are approaching a critical point where planning mode, as an explicit human intervention step, will gradually disappear. This is not because planning itself is unimportant, but because models are now smart enough to plan well on their own. But there's an important caveat: this holds only if you have done your work on Levels 3 to 6. If your context is clean, constraints are clear, tool descriptions are thorough, and feedback loops are closed, the model can reliably plan without needing your review. If these tasks aren't done well, you'll still have to keep an eye on the plan.
To clarify, planning as a general practice will not vanish; it will merely change form. For newcomers, planning mode remains the correct entry point (as described in Levels 1 and 2). But for the complex functions of Level 7, “planning” no longer looks like writing a step-by-step outline but more like exploration: probing the codebase, prototyping in the worktree, and mapping out the solution space. More and more often, it is background agents doing this exploration for you.
This is significant because it unlocks background agents. If an agent can generate reliable plans and execute them without needing your signature approval, it can operate asynchronously while you do other tasks. This is a key shift—from “I’m switching between multiple tabs” to “work is progressing without me being present.”
The Ralph Loop is a popular entry point: a self-sufficient agent loop running the programming CLI repeatedly until all items in the PRD (Product Requirements Document) are completed, with each iteration launching a new instance with fresh context. In my experience, getting the Ralph Loop to run smoothly is not easy; any inadequacy or inaccuracy in the PRD will ultimately come back to haunt you. It can feel a bit too “throw it out and forget about it.”
You can run multiple Ralph loops in parallel, but the more agents you start, the more you’ll find where the time goes: coordinating them, arranging the order of work, checking outputs, pushing progress. You’re no longer writing code—you’ve become a middle manager. You need a scheduling agent to handle the logistics so you can focus on intent rather than administration.
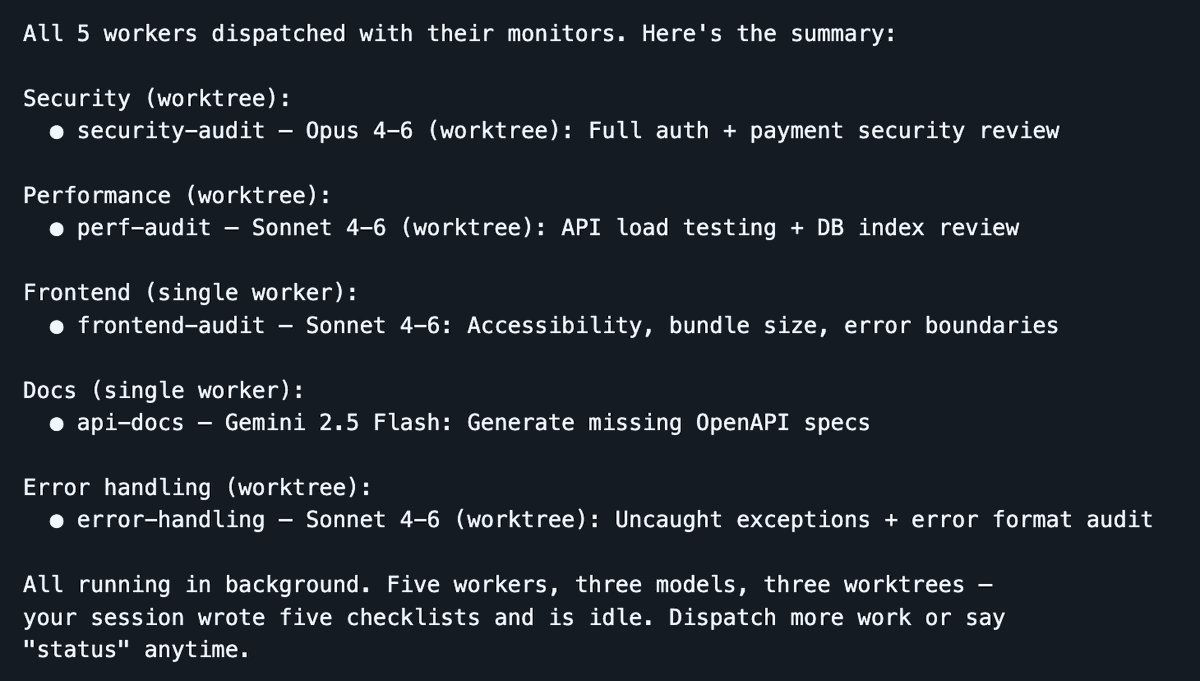
Dispatch starts 5 workers in parallel across 3 models—your session stays streamlined while the agents do the work
A tool I’ve been using extensively is Dispatch, which I've built as a Claude Code skill, turning your session into a command center. You stay in a clean session while workers complete the heavy lifting in isolated contexts. The dispatcher handles planning, delegation, and tracking, while your main context window is preserved for orchestration. When a worker gets stuck, it throws out clarifying questions instead of failing silently.
Dispatch runs locally, making it ideal for rapid development scenarios where you want to stay closely linked to work: faster feedback, easier debugging, and no infrastructure overhead. Ramp’s Inspect is a complementary solution for longer-running, more autonomous work: each agent session starts in a cloud sandbox VM with a complete development environment. If a PM discovers a UI bug and flags it in Slack, Inspect will take over and handle it while you close your laptop. The trade-off is operational complexity (infrastructure, snapshots, security), but you gain scalability and reproducibility that local agents cannot match. I recommend using both (local and cloud background agents).
In this level, there is an unexpectedly powerful pattern: using different models for different tasks. The best engineering teams are not composed of clones. Team members have different ways of thinking, different training backgrounds, different strengths. The same logic applies to LLMs. These models have gone through different fine-tuning, sporting distinct personalities. I often assign Opus for implementation work, Gemini for exploratory research, and Codex for review, achieving combined output that surpasses any single model working independently. It can be thought of as collective intelligence applied to code.
Crucially, you also need to decouple the implementers from the reviewers. I’ve learned this lesson the hard way too many times: if the same model instance is responsible for implementing and assessing its own work, it will inherit biases. It will overlook problems and tell you all tasks are complete—when in fact they are not. This is not malicious; the reasoning is similar to why you wouldn't grade your own exam. Have another model (or a different instance with review-specific prompts) handle the reviews. The quality of your signals will improve significantly.
Background agents also open the floodgates for the integration of CI with AI. Once agents can operate without human oversight, they can be triggered from existing infrastructure. A documentation bot regenerates documentation after each merge and submits PRs to update CLAUDE.md (we're using this, saving a lot of time). A security review bot scans PRs and submits fixes. A dependency management bot not only tags issues but actually upgrades packages and runs test suites. Good context, continuously refined rules, robust tools, automated feedback loops—all now autonomously running.
Level 8: Autonomous Agent Teams
No one has truly mastered this level yet, although a few are making progress toward it. This is the current frontier.
At Level 7, you orchestrate LLMs in a center-radiating pattern, distributing tasks to working LLMs. Level 8 removes this bottleneck. Agents coordinate directly with each other—claiming tasks, sharing discoveries, marking dependencies, resolving conflicts—all without going through a single orchestrator.
The experimental Agent Teams feature of Claude Code is an early implementation: multiple instances work in parallel on a shared codebase, teammates operate in their respective context windows and communicate directly with each other. Anthropic built a C compiler capable of compiling Linux from scratch with 16 parallel agents. Cursor ran hundreds of concurrent agents for weeks, building a browser from zero and migrating its codebase from Solid to React.
However, a closer examination reveals issues. Cursor found that without a hierarchy, agents became indecisive and made no progress. Anthropic's agents continuously broke existing functionality until CI pipelines were added to prevent regressions. Everyone experimenting with this level says the same thing: multi-agent coordination is a hard problem, and no one has found the optimal solution yet.
To be honest, I don’t believe the models are ready for such autonomy for most tasks. Even if they are smart enough, they are still too slow and too token-expensive for moon-landing-level projects beyond compiler and browser builds, making them economically unfeasible (impressive, but far from mature). For most of our daily work, Level 7 is the real leverage point. I wouldn't be surprised if Level 8 eventually becomes mainstream, but for now, I'll focus my efforts on Level 7 (unless you're Cursor—breakthroughs are your business).
Level ?
The inevitable “what’s next” question.
Once you can deftly orchestrate agent teams without much friction, there’s no reason for the interface to remain solely textual. Voice-to-voice (perhaps thought-to-thought?) interactions with programming agents—conversational Claude Code, and not just voice-to-text inputs—are the natural next step. Imagine looking at your application, vocally describing a series of changes, and then watching them unfold before you.
There is a group chasing the perfect one-time generation: say what you want, and AI delivers it flawlessly in one go. The problem with this premise is it assumes we humans know exactly what we want. But we don’t. We never did. Software development has always been iterative, and I believe it always will be. It will just become much easier, far surpassing pure text interactions, and much faster.
So: which level are you at? What are you doing to reach the next one?
Which level are you at?
How do you typically use AI to start a programming task?
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







