Source: APPOSO
"Open" and "Open Source" are not just one word apart.
Google's Gemma series has been released for two years, allowing developers to download and run it locally, but its usage is limited, redistribution is restricted, and modifications cannot be casually shared. At best, this can only be considered "open," not meeting the "open source" standard in the AI circle.

Google DeepMind CEO Demis Hassabis
Just now, Google released four models from the Gemma 4 series, fully open-sourced under Apache 2.0, with the smallest version capable of running completely offline on a Raspberry Pi. The Gemma small model has truly reached the hands of everyone for the first time.
Winning with Small
Gemma 4 has four sizes, with the underlying technology from Gemini 3, covering hardware from edge devices to high-performance workstations:
E2B / E4B: Designed specifically for mobile phones and IoT devices, optimized in deep collaboration with the Google Pixel team, Qualcomm, and MediaTek. During inference, only the 2B and 4B parameters are activated, to save memory and power as much as possible.
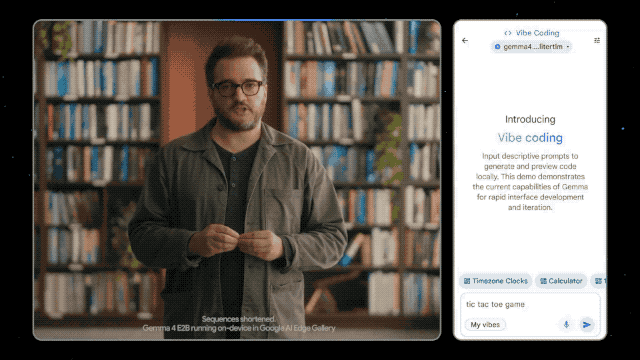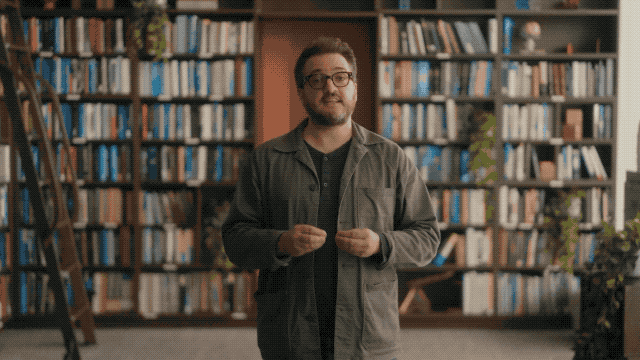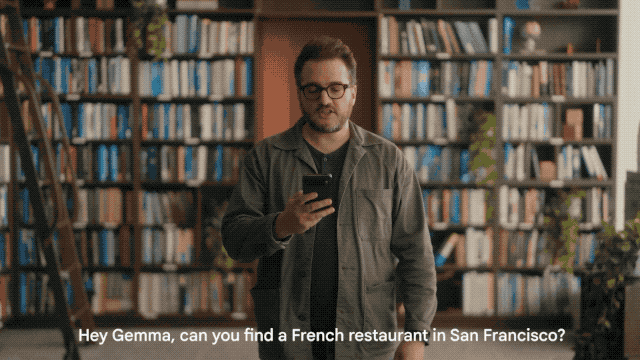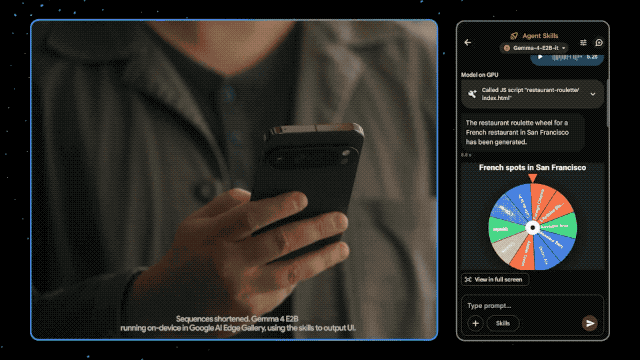
Supports a 128K context window and has the capability for image, video, and native audio input, operating fully offline on Pixel phones, Raspberry Pi, and Jetson Orin Nano, with near-zero latency. Android developers can now experience the Agent Mode in advance through the AICore developer preview.
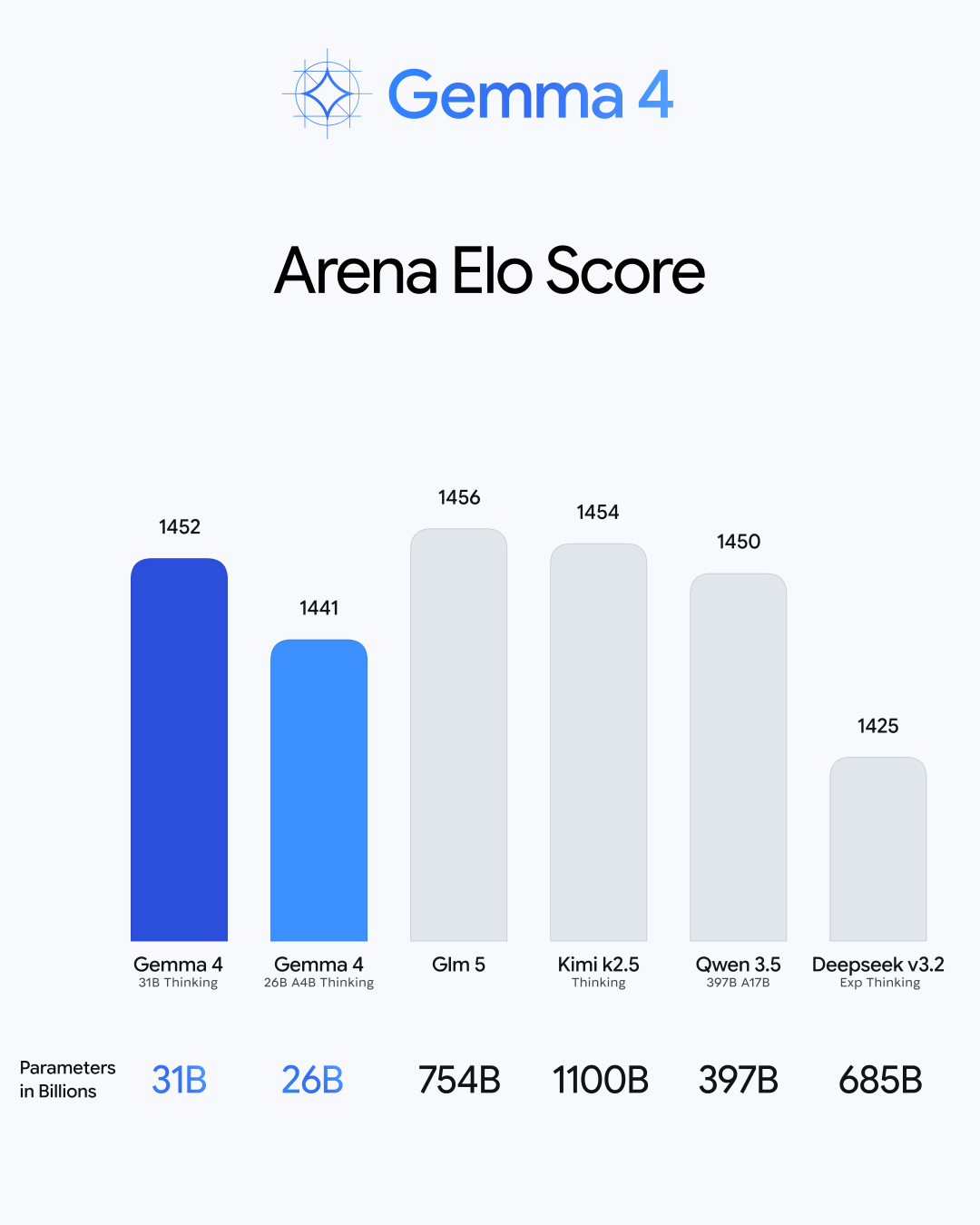
26B MoE: A mixture of experts architecture, activating only 3.8B of all parameters during inference, maintaining high quality while ensuring ultra-fast inference speed, with an Arena AI text score of 1441, ranking sixth among open-source models.
31B Dense: Pursuing ultimate raw performance, with an Arena AI text score of 1452, ranking third among open-source models. The unquantized bfloat16 weights can run on a single 80GB NVIDIA H100, while the quantized version supports consumer-grade GPUs, providing a strong foundation for local fine-tuning.
In terms of capabilities, the four models are highly consistent: all support multi-step reasoning and complex logic; native support for function calls, JSON structured output, and system instructions, enabling the construction of autonomous Agents that can interact with external tools and APIs;
supporting image and video input, excelling at visual tasks like OCR and chart understanding; pretrained in over 140 languages. The context window for the 26B and 31B models has further expanded to 256K, allowing complete codebases or long documents to be input in a single prompt.
Benchmark numbers can more intuitively illustrate the magnitude of upgrades in this generation. Compared to the previous generation Gemma 3 27B, Gemma 4 31B jumped from 20.8% to 89.2% on the math reasoning benchmark AIME 2026, and from 29.1% to 80.0% on the code capability benchmark LiveCodeBench v6, while the tool calling capacity measurement τ2-bench surged from 6.6% to 86.4%.
These three data points are particularly crucial as they correspond directly to the three most core application scenarios of reasoning, programming, and Agents.
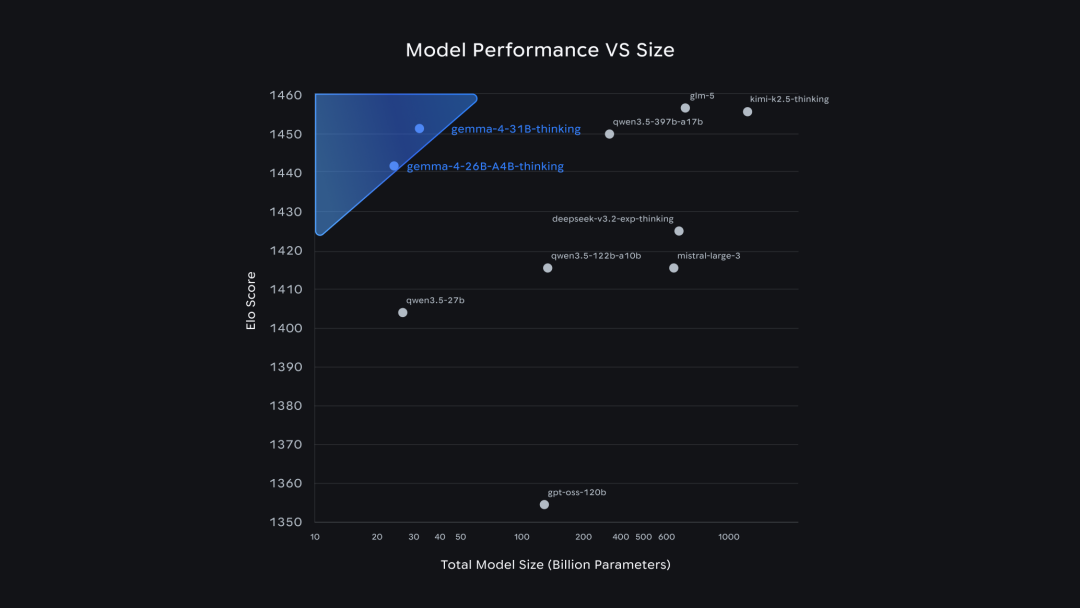
Parameter efficiency is another dimension worth noting. From the scatter plot of "model performance vs. parameter quantity," Gemma 4 achieved Elo scores that typically require hundreds of billions or even trillions of parameters using only the 26B and 31B sizes.
The score for 26B MoE reached nearly 15 times that of Qwen3.5-397B-A17B in terms of parameter count, while the score for 31B Dense is on par with GLM-5, which has over 600B parameters. Google summarizes this as "unprecedented intelligence density per parameter," with numbers appearing to be rational and substantiated.
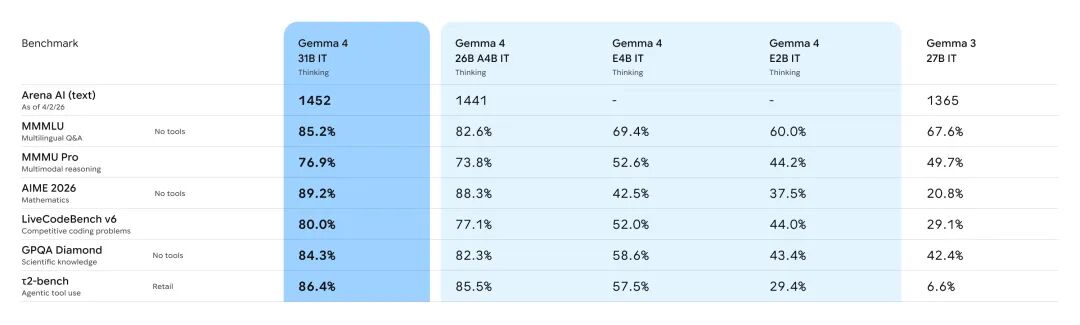
Edge models are similarly noteworthy. E2B achieved a score of 60.0% on the multilingual question-answering benchmark MMMLU and 43.4% on the scientific knowledge benchmark GPQA Diamond. Notably, this is a model that only activates the 2B parameters and can run on a mobile phone.
In comparison, Gemma 3 27B scored 42.4% on GPQA Diamond, nearly the same as E2B. In other words, the 2B model on a mobile phone has already caught up with the previous generation 27 billion parameter desktop model.
In terms of hardware ecosystem, NVIDIA and Google have collaborated on inference optimization for Gemma 4 on RTX GPUs, DGX Spark personal AI supercomputers, and Jetson Orin Nano.
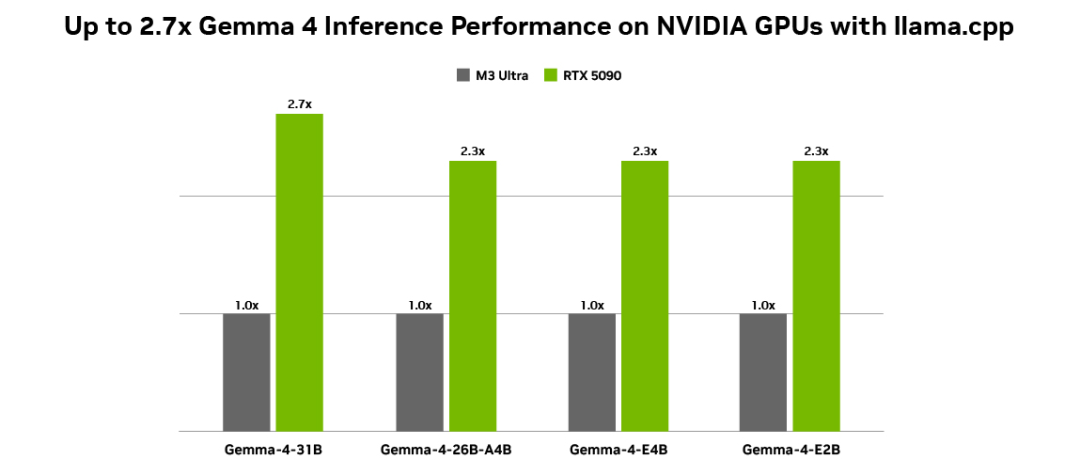
NVIDIA Tensor Core and CUDA software stack provide high throughput and low latency support for Gemma 4 right out of the box. The local Agent application OpenClaw has also been adapted for the latest models, capable of calling local files and automating task execution in application contexts.
From "Open" to "Open Source," Unlocking Another Possibility
To understand this release, it is necessary to first clarify the relationship between Gemma and Gemini. Both are built on the same set of research and technology systems, with the distinction that Gemini is a subscription-based closed-source product, while Gemma is an open model available for free download and local operation.
The Gemma series has consistently used Google's proprietary licensing terms. Developers can download and run it locally, but its use and redistribution are limited.
Now, Gemma 4 has officially switched to the Apache 2.0 license. Under this license, developers can use the model for any purpose, including personal, commercial, and enterprise use, without paying royalties, and with no restrictions on usage, modifications, or redistribution.
Apache 2.0 also includes a built-in patent protection mechanism: contributors automatically license their patents to users, and if users sue others for patent infringement, they automatically lose the usage license. This bilateral clause provides additional legal protection for enterprise-level users.
The substantial significance of this open-sourcing is that Gemma 4 can now be legally packaged into products, services, and hardware devices for delivery. For industry users with data sovereignty or compliance requirements, running completely locally means data does not have to be uploaded to the cloud while still gaining access to cutting-edge AI capabilities.
Clément Delangue, co-founder and CEO of Hugging Face, referred to this licensing switch as "an important milestone."
Since the release of the first generation in February 2024, the total downloads of the Gemma series have exceeded 400 million, and there are over 100,000 community-derived variants.
Now, model weights have been made available on Hugging Face, Kaggle, and Ollama, with mainstream frameworks like Transformers, TRL, vLLM, llama.cpp, MLX, Unsloth, SGLang, and Keras providing support on the day of release.
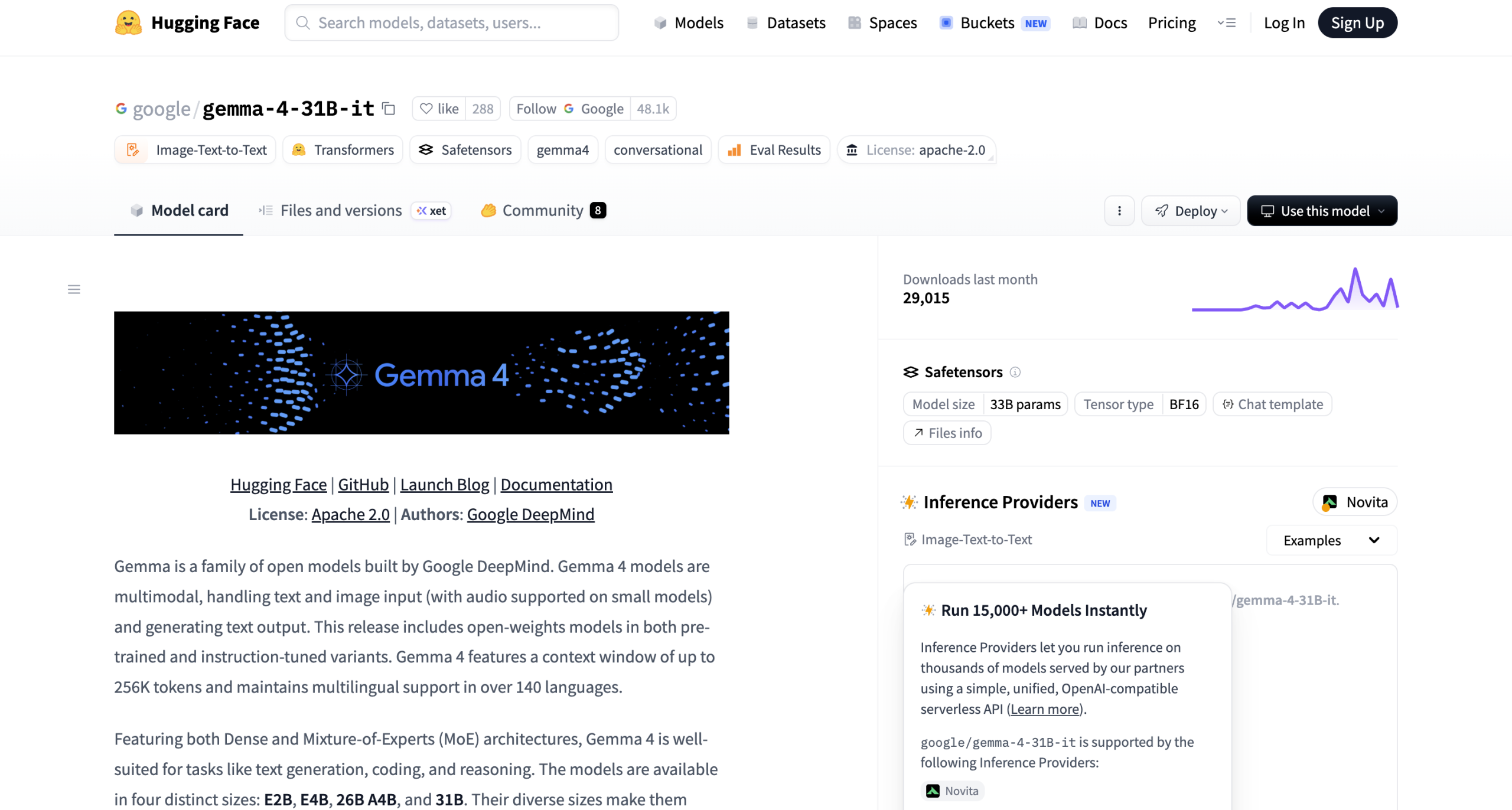
Local deployment can quickly get started with Ollama or llama.cpp combined with GGUF format weights, and Unsloth Studio also synchronously offers fine-tuning and deployment support for quantized models. For cloud expansion, Google Vertex AI, Cloud Run, and GKE are simultaneously available.
The small models represented by Gemma 4 have far-reaching significance because they answer a fundamental question: Where should AI run?
For the past two years, the answer to this question has been nearly default:
Data centers. Users call cloud models through network interfaces, data must be uploaded, usage depends on connection, and costs are set by service providers. This model works reasonably well in consumer scenarios but poses an insurmountable barrier for industries with data sovereignty requirements, such as healthcare, finance, and industry.
Gemma 4 offers another possibility.
Mobile phones, Raspberry Pis, and factory terminals without external internet can all complete full model inference locally. Data never leaves the device, and decisions do not go through the cloud. The Apache 2.0 licensing further opens up implementation space: models can be legally packaged into hardware products and pre-installed into industry-specific devices, no longer limited by compliance constraints of calling protocols and data sovereignty.
The numbers on the capability front also validate the feasibility of this path. E2B's score on the scientific knowledge benchmark GPQA Diamond is now nearly on par with the previous generation's 27 billion parameter desktop model, and it only activates 2 billion parameters for inference, able to run completely offline on a mobile phone.
"Cheaper" or "more convenient" is no longer enough to describe this change; it is more closely related to an expansion of coverage, where AI capabilities are conditionally beginning to truly enter those long-excluded scenarios.
The proliferation of operating systems has undergone a similar process: from dedicated tools for specialized institutions, gradually embedding into every personal device until people no longer realize their existence. AI still has a long way to go before reaching that stage; engineering, interaction, and reliability issues do not yet have complete answers, but being able to run on any device is certainly the most fundamental and important step on this road.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







