
At the end of April 2026, an anonymous model named “Owl Alpha” quietly appeared on OpenRouter, the largest global model aggregation and distribution platform. There were no official announcements, no media press conferences, and even information about the development team was non-existent. However, over the next two months, this mysterious model rapidly climbed to the top ranks in platform usage due to its astonishing throughput. According to VentureBeat, the model reached a monthly Token throughput of approximately 10.1 trillion during its anonymous testing phase, handling an average of 559 billion Tokens per day, with a month-over-month growth of 242%. It wasn't until June 30, when Meituan officially released LongCat-2.0, that this large model, trained with 50,000 domestic GPUs and boasting 16 trillion parameters, revealed its true identity. Meituan's official announcement confirmed that Owl Alpha is its preview version and stated that the current monthly usage ranks among the top three globally on OpenRouter.
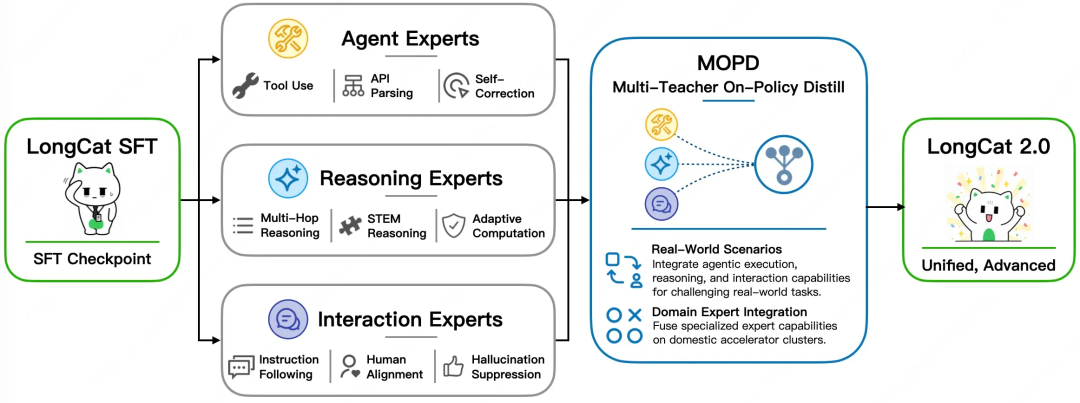
Overview of LongCat-2.0's MOPD multi-expert fusion architecture (source: longcatai.org)
The ability of a preview model to achieve such high usage on an overseas developer platform is not solely due to one factor but rather the result of the interplay between its technical architecture and distribution strategy. Before it, domestic large models from Zhipu to Xiaomi seemed eager to engage in “invisible training” via OpenRouter before their official release.
The Two Months of Owl Alpha: How an Anonymous Model Surged into the Top Three on OpenRouter?
To understand the high usage of LongCat-2.0, one must first comprehend OpenRouter's role in the current ecosystem of large models. For developers, OpenRouter provides a unified API interface that connects hundreds of models from dozens of manufacturers globally. When selecting a model, developers often compare the speed, quality, and price of different models under the same Prompt. When a new model is launched, if it demonstrates performance that surpasses other models at the same price point, or offers an extremely disruptive price, the word-of-mouth spread within the developer community can be rapid.
The surge of Owl Alpha on OpenRouter follows this logic. According to Meituan's official announcement, Owl Alpha ranked first, second, and third in three major monthly usage scenarios: Hermes (Agent workspace), Claude Code, and OpenClaw. The common feature of these three scenarios is a heavy reliance on Agent capabilities, meaning the model needs to repeatedly read the codebase, perform multiple tool calls, and engage in long-context reasoning.
High usage is not coincidental; it involves not just the model’s parameter scale but also its adaptability to specific scenarios and its extremely aggressive pricing strategy. During the anonymous testing period, Owl Alpha did not expose its domestic computational background, purely conquering developers with its technical performance and price. The reported 10.1 trillion monthly Token throughput, although an estimate from the media and not officially disclosed by OpenRouter, is sufficient to indicate that the model has achieved a very high adoption rate within the developer community. This adoption rate is not bought with marketing budgets; it is built up through genuine API calls.
Caching the Codebase: How LongCat-2.0 Rewrites the Billing Logic for Agents
LongCat-2.0’s ability to support such enormous calling volumes lies at the core in the deep integration of its technical architecture and business strategy. According to Meituan's official announcement, LongCat-2.0 has a total parameter count of 16 trillion, with an average activation of about 48 billion parameters and a dynamic range between 33 billion to 56 billion, natively supporting an ultra-long context of 1 million Tokens. This MoE (Mixture of Experts) architecture with 16 trillion total parameters and 48 billion active parameters is currently the mainstream choice for balancing performance and cost in large models.
In terms of technical architecture, LongCat-2.0 integrates four key innovations, each directly addressing specific pain points in Agent development.
The first is LSA (LongCat Sparse Attention), which tackles the memory wall issue. Processing an ultra-long context of 1 million Tokens results in square-level growth in computational demand using traditional attention mechanisms, leading to significant memory bandwidth bottlenecks. LSA converts fragmented memory access into continuous block reading through Streaming-aware Indexing, achieves cross-layer attention index reuse via Cross-Layer Indexing, and performs coarse-to-fine two-stage filtering through Hierarchical Indexing, reducing the computational demand for processing long texts from square-level to linear. This addresses the memory wall faced by Agents when accessing large codebases.
After resolving the memory wall, the next step is the refinement of computational allocation. In the MoE architecture, not all Tokens require complex calculations. Simple Tokens like punctuation marks and function words routed to complex expert networks result in wasted computational resources. LongCat-2.0 introduces a "zero-calculation expert" within the expert pool, allowing Tokens routed to that expert to simply return the input without consuming computational resources. The system dynamically adjusts expert biases via a PID controller to maintain average active parameters within the target range. This setup is like having a fast lane on a highway that allows simple tasks to pass through quickly, leaving computational power for complex recursive deductions.
After optimizing computational allocation, communication latency became the next bottleneck to tackle. ScMoE (Shortcut-connected MoE) employs cross-layer shortcuts, executing the dense FFN computation of the previous block in parallel with the dispatch/combine communication of the current MoE layer. This pipeline design reduces theoretical TPOT (Time-Per-Output-Token) by nearly 50%, directly enhancing the model's response speed, which is crucial for frequently interactive Agent scenarios.
Lastly, the task scheduling aspect involves MOPD (Multi-Teacher Optimization via Mixture of Specialized Experts). In the post-training phase, LongCat-2.0 splits optimization into three specialized expert clusters: Agent, Reasoning, and Interaction. Agent Experts handle tool calls and multi-round API parameter parsing, Reasoning Experts focus on multi-hop logic and mathematical reasoning, and Interaction Experts are responsible for instruction following and safety barriers. During inference, gated networks dynamically schedule based on task type. This means that when developers call the model for code review, the Agent experts are activated; when performing mathematical deductions, the Reasoning experts are activated. This division of labor enhances the model's expertise in specific tasks.
However, while the technical architecture lays the foundation for cost reduction, the true change in the developer's assessment logic arises from its pricing strategy. According to the LongCat API pricing page, the standard pricing is ¥5 per million Tokens for input and ¥20 per million Tokens for output. However, during a limited-time discount period, the price drops to $0.30 per million Tokens for input and $1.20 per million Tokens for output. Even more disruptive is its "free on cache hit" mechanism.
In Agent development, models need to repeatedly access the same codebase or system prompts. Under traditional billing models, these repeated input Tokens incur fees each time, causing the operational costs of the Agent to grow linearly with the number of interactions. LongCat-2.0's cache hit-free mechanism means that as long as the prefix part of the input hits the cache, there are no deductions in fees. This design hits at the cost pain points in Agent scenarios and is seen by many developers as a “revolutionary change in Agent cost economics.”
To better understand the cost-performance ratio of LongCat-2.0, we can refer to the following comparison table based on public ecosystem signals.
| Model | Manufacturer | SWE-bench Pro Score | Standard Output Price ($/M tokens) | Time-Limited Output Price ($/M tokens) | Open Source License | Data Source Description |
|---|---|---|---|---|---|---|
| Claude Opus 4.8 | Anthropic | 69.2 | $25.00 | None | Closed Source | Vendor self-reported/third-party aggregation |
| GLM-5.2 | Zhipu | 62.1 | $4.40 | None | MIT | Vendor self-reported/third-party aggregation |
| Qwen3.7 Max | Alibaba | 60.6 | $3.75 | None | Partially Open Source | Vendor self-reported/third-party aggregation |
| LongCat-2.0 | Meituan | 59.5 | $2.95 | $1.20 | MIT | Vendor self-reported, not yet on the Scale AI standardized public list |
| MiniMax M3 | MiniMax | 59.0 | $2.40 | None | Open Source | Vendor self-reported/third-party aggregation |
| GPT-5.5 | OpenAI | 58.6 | $30.00 | None | Closed Source | Vendor self-reported/third-party aggregation |
| DeepSeek V4 Pro Max | DeepSeek | 55.4 | $0.87 | None | MIT | Vendor self-reported/third-party aggregation |
It should be noted that the SWE-bench Pro scores in the table are based on vendor self-reported or third-party aggregated data. Different models may have been tested under different batches or evaluation conditions, so the horizontal comparison is for reference only. Additionally, the 59.5 score for LongCat-2.0 is self-reported by Meituan, and as of publication, it has not entered the Scale AI standardized public leaderboard. On the Scale standardized public list, GPT-5.4 (xHigh) leads with a standardized score of 59.1%, and standardized scores are generally 10 to 30 points lower than vendor self-reports. Nevertheless, under the limited-time discount price of $1.20 per million Tokens and supplemented by the free caching mechanism, its price destruction power among open-source models remains significant.
Top Three Performance Scores and “Programming Below Expectations”: The Actual Capability Boundaries of LongCat-2.0
Data released by manufacturers often paints a perfect picture, but the actual experience of developers is far more complex. LongCat-2.0 achieved a score of 59.5 on SWE-bench Pro, 77.3 on SWE-bench Multilingual, and 70.8 on Terminal-Bench 2.1. These numbers indicate that the model is in the top tier of open-source models in software engineering benchmark testing.
However, feedback from developers in the Reddit r/LocalLLaMA community reveals a different perspective. Some users have expressed after testing: “It's not good in coding, very good in reviews though. Instruction following is also pretty good. A little bit of a waste with that parameter...” This reflects that the model may not perform as well in general code generation tasks as in code reviewing and instruction following tasks. In the r/SillyTavernAI community, some users also reported that the model tends to take over the dialogue in role-playing scenarios, resulting in flaws in the interaction experience.
This discrepancy between scores and actual experience is not uncommon in the large model industry. Vendor-reported scores are typically obtained under specific testing environments and prompt conditions, while the actual usage scenarios of developers are often more diverse and complicated. LongCat-2.0 has specifically set up three dedicated expert groups in its MOPD architecture: Agent, Reasoning, and Interaction, which may enable the model to excel in specific tasks, but it still has limitations in general programming generation.
Moreover, the open-source commitment of LongCat-2.0 still requires time for validation. As of June 30th, the release date, its HuggingFace page showed the model weight as “coming soon,” with no download available. Although it was officially announced to adopt the MIT open-source license, making it friendly for enterprise users and embeddable in closed-source commercial products, developers remain cautiously observing until the weights are actually made available. At the same time, the claimed information retention rate of 1 million Tokens' ultra-long context also lacks independent third-party verification, such as public data from tests like Needle-in-a-Haystack. These limitations mean that the actual capability boundaries of LongCat-2.0 still need to be defined through broader developer practices.
From Pony to Owl: Why Domestic Large Models Are Eager to "Sneak Run" Overseas?
The anonymous testing of Owl Alpha on OpenRouter is not an isolated incident. Reviewing industry dynamics since 2026 reveals a clear trend: domestic large models are increasingly engaged in anonymous previews on OpenRouter before their official releases.
In February 2026, OpenRouter launched the anonymous model “Pony Alpha,” which was later confirmed by media like Securities Times to be the true identity of Zhipu AI's GLM-5. This model excelled in programming and Agent optimization, and offered free access. Following this, the anonymous model “Hunter Alpha” appeared in March and was later confirmed to be Xiaomi's MiMo-V2-Pro, featuring 1 trillion parameters and 1 million context. By the end of April, Owl Alpha was launched, which is Meituan's LongCat-2.0. These cases form a clear timeline of domestic large models' "invisible training."
Why do domestic large models choose this method of anonymously “sneak running” on overseas platforms?
First, it is an efficient strategy for cold starts and obtaining real feedback. In the domestic market, the release of large models typically comes with very high levels of public scrutiny and competitive pressure. Once a manufacturer makes an official announcement, they are immediately subjected to microscale comparisons against all competing products. However, launching anonymously on OpenRouter allows for the elimination of brand halo and public burden, allowing the model to present itself purely in terms of technology and price to global developers. The feedback from the developer community is genuine and harsh, focusing only on whether usage is smooth, prices are cheap, and outputs are of high quality. This "blind testing" environment provides manufacturers with the most accurate feedback on maximum throughput and opportunities to discover bugs.
Secondly, it is a real-world test of infrastructure stability. LongCat-2.0 was fully trained and inferred based on 50,000 domestic AI ASIC cards. Whether such a large-scale domestic computational cluster can sustain daily throughputs of over 1 trillion tokens/day under real-world pressure will only be validated under actual global traffic shocks. OpenRouter offers a readily available, high-concurrency traffic entry point, helping Meituan to test the extreme carrying capacity of its domestic computational cluster.
Finally, the objective existence of a market window has also driven this strategy. U.S. export controls limit the external supply of some closed-source models (like Claude Fable 5/Mythos 5 and GPT-5.6), which objectively opens up a window for domestic models in overseas markets. Through anonymous testing on OpenRouter, domestic models can quickly fill some developers' demands for high-performance, low-cost models, accumulate user bases and reputations, and pave the way for subsequent official releases and commercialization.
From Pony to Hunter to Owl, the "invisible training" of domestic large models on OpenRouter has evolved from an occasional attempt into a common cold start strategy in the industry. For developers, this means they can access models that have been tested against real traffic earlier and conduct development and testing at more competitive prices; for the industry, this cold start mode based on real API call volumes is gradually replacing single authoritative leaderboards and becoming a new standard for assessing the stability of large model infrastructures and actual capabilities.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








