AI公司曾经以行业领袖OpenAI为标准进行自我衡量。但现在不再如此。随着中国的DeepSeek成为领先者,它已成为其他公司的竞争目标。
周一,DeepSeek颠覆了AI行业,在华尔街造成了数十亿美元的损失,同时引发了关于一些美国初创公司和风险投资实际效率的质疑。
现在,两个新的AI巨头进入了竞争:位于西雅图的艾伦人工智能研究所和中国的阿里巴巴;两者都声称他们的模型与DeepSeek V3相当或更好。
艾伦人工智能研究所是一家美国研究机构,以发布一个更为温和的视觉模型Molmo而闻名,今天推出了Tülu 3的新版本,这是一个免费的开源4050亿参数的大型语言模型。
“我们很高兴地宣布推出Tülu 3 405B——这是将完全开放的后训练配方应用于最大的开放权重模型的首次尝试,”这家由保罗·艾伦资助的非营利组织在一篇博客文章中表示。“通过此次发布,我们展示了在405B参数规模下应用我们的后训练配方的可扩展性和有效性。”
对于喜欢比较规模的人来说,Meta最新的LLM,Llama-3.3,有700亿个参数,而其迄今为止最大的模型是Llama-3.1 405b——与Tülu 3的规模相同。
该模型规模如此庞大,以至于需要非凡的计算资源,训练时需要32个节点和256个GPU并行运行。
在构建模型的过程中,艾伦研究所遇到了几个障碍。Tülu 3的巨大规模意味着团队必须将工作负载分配到数百个专用计算芯片上,其中240个芯片处理训练过程,而另外16个芯片管理实时操作。
即使拥有如此庞大的计算能力,系统仍然频繁崩溃,并需要全天候监督以保持运行。
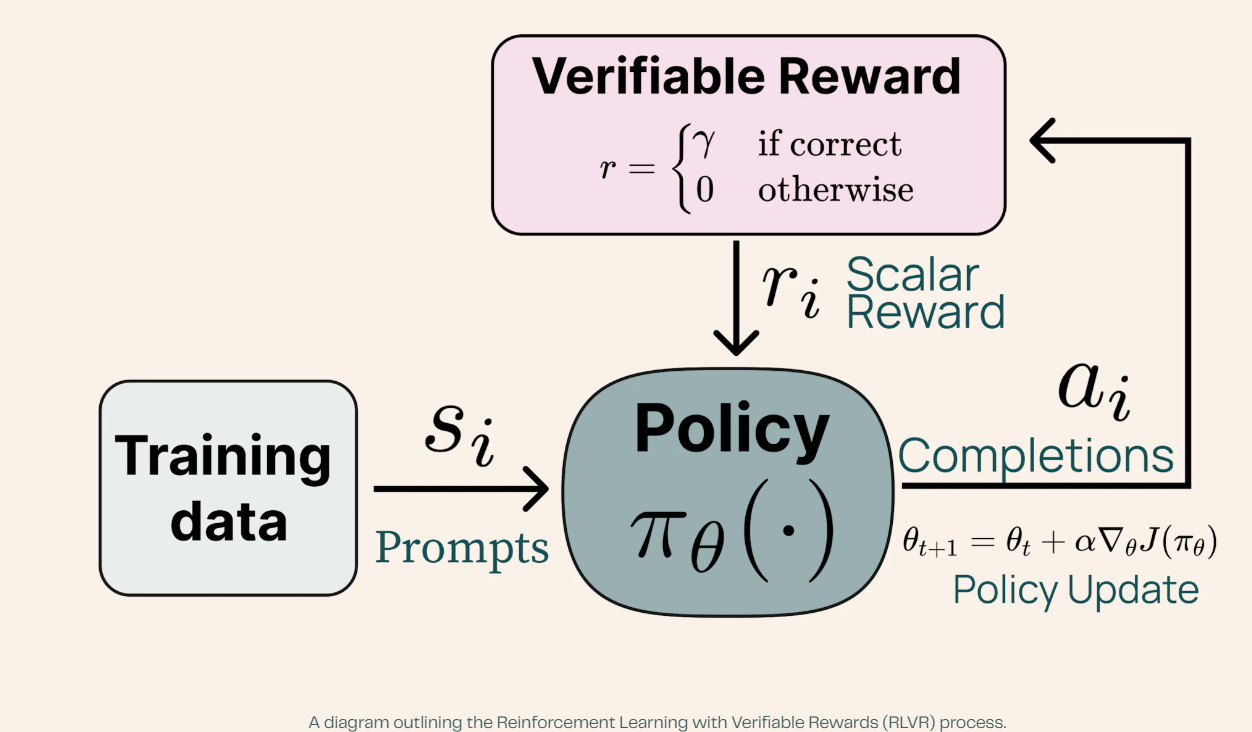
Tülu 3的突破集中在其新颖的可验证奖励强化学习(RLVR)框架上,该框架在数学推理任务中表现出特别的优势。
每次RLVR迭代大约需要35分钟,推理需要550秒,权重转移需要25秒,训练需要1500秒,AI在每轮中解决问题的能力不断提高。
图片:Ai2
可验证奖励强化学习(RLVR)是一种训练方法,似乎像一个复杂的辅导系统。
AI接收特定任务,比如解决数学问题,并立即获得其答案是否正确的反馈。
然而,与传统的AI训练(如OpenAI用于训练ChatGPT的训练方式)不同,后者的人类反馈可能是主观的,RLVR仅在AI产生可验证的正确答案时给予奖励,类似于数学老师确切知道学生的解答是对还是错的方式。
这就是为什么该模型在数学和逻辑问题上表现出色,但在创意写作、角色扮演或事实分析等其他任务上表现不佳的原因。
该模型可在艾伦AI的游乐场上使用,这是一个免费的站点,用户界面类似于ChatGPT和其他AI聊天机器人。
我们的测试确认了从这样一个大型模型中可以预期的结果。
它在解决问题和应用逻辑方面表现非常出色。我们提供了来自多个数学和科学基准的不同随机问题,它能够输出良好的答案,甚至比基准提供的样本答案更易于理解。
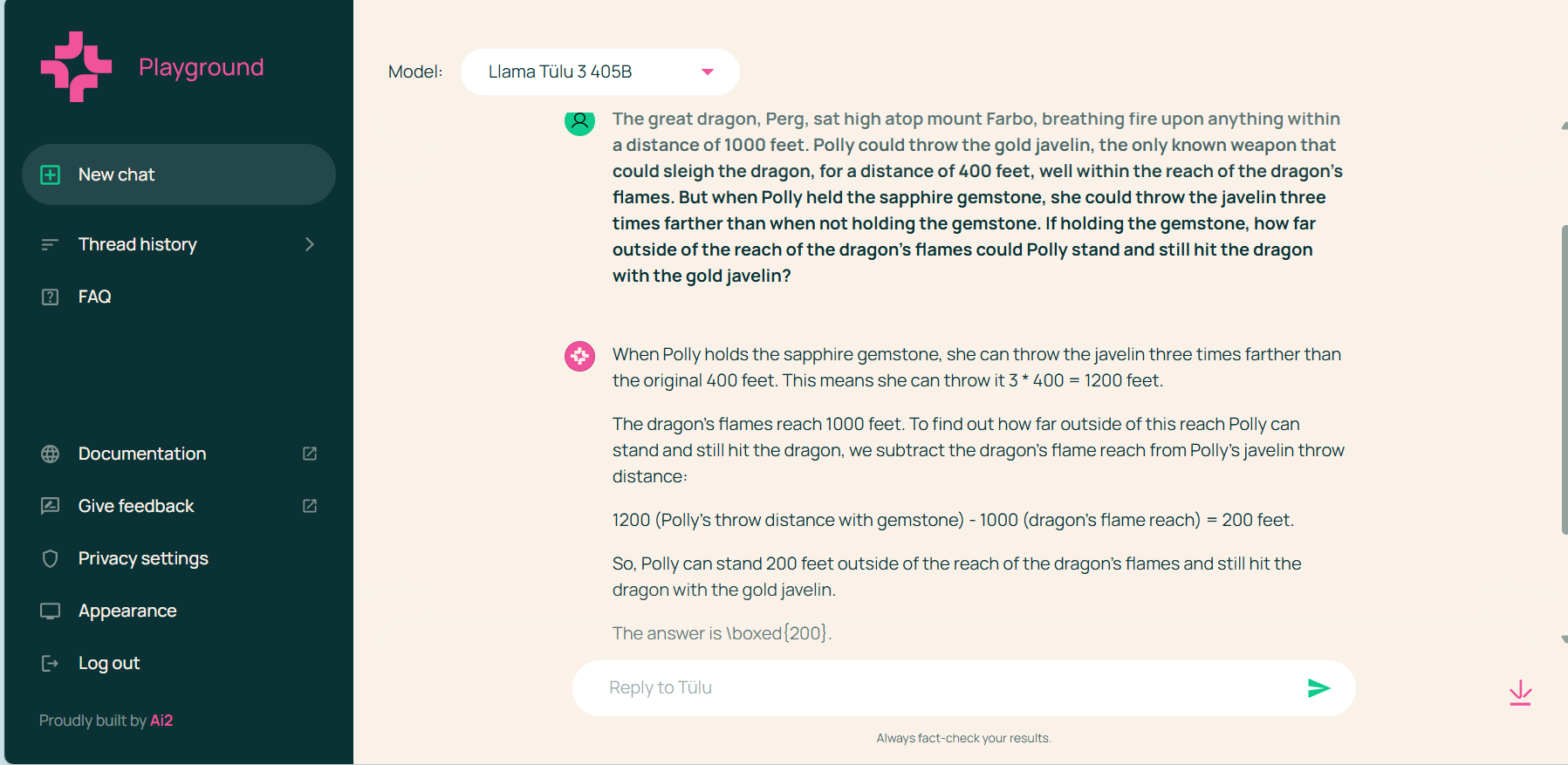
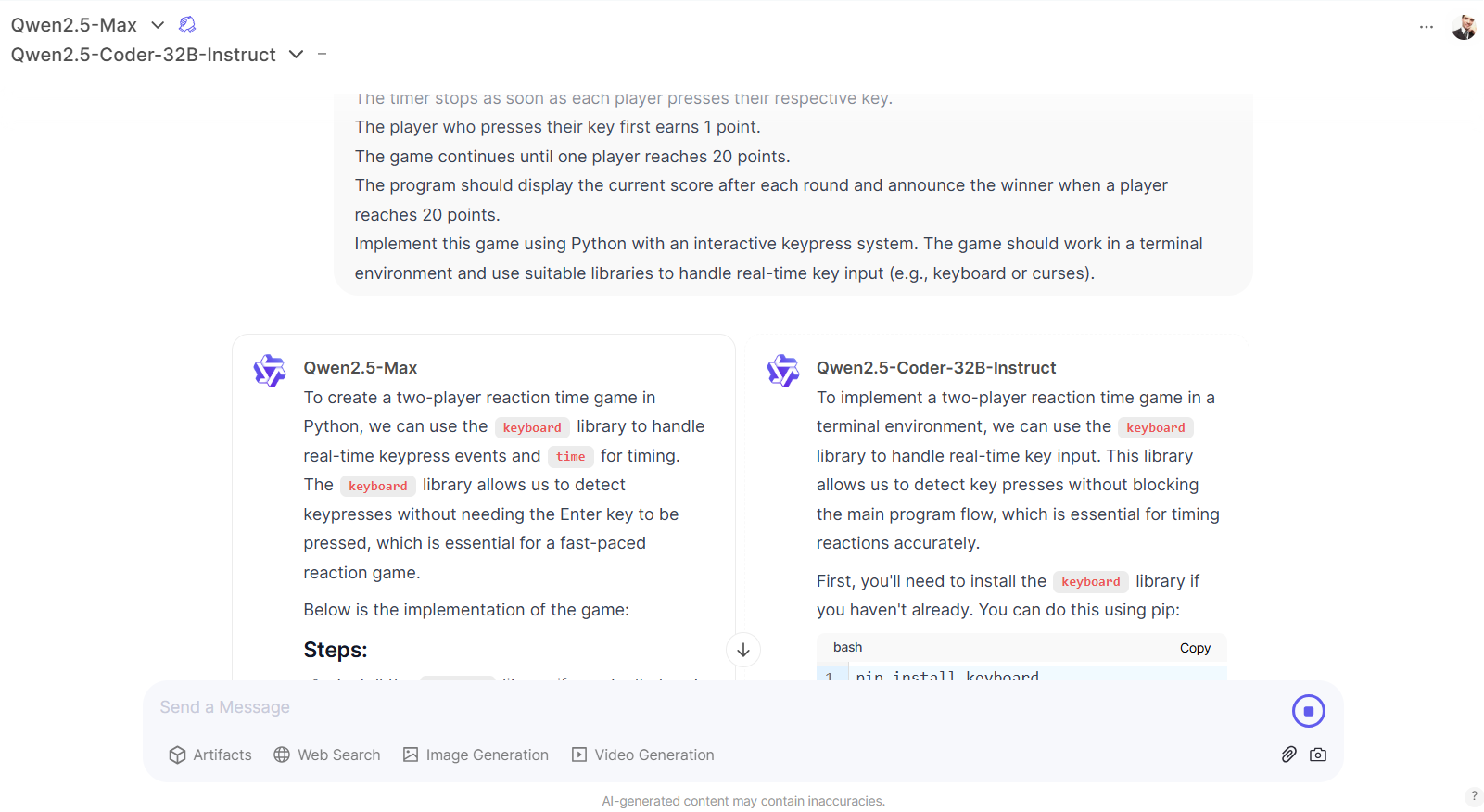
然而,它在其他与逻辑语言相关的任务中表现不佳,这些任务不涉及数学,例如写出以特定单词结尾的句子。
此外,Tülu 3并不是多模态的。相反,它坚持自己最擅长的领域——生成文本。这里没有华丽的图像生成或嵌入的思维链技巧。
好的一面是,界面可以免费使用,只需简单登录,无论是通过艾伦AI的游乐场,还是下载权重以在本地运行。
该模型可以通过Hugging Face下载,提供从80亿参数到巨型4050亿参数版本的替代选项。
中国科技巨头加入竞争
与此同时,中国并没有满足于DeepSeek的成就。
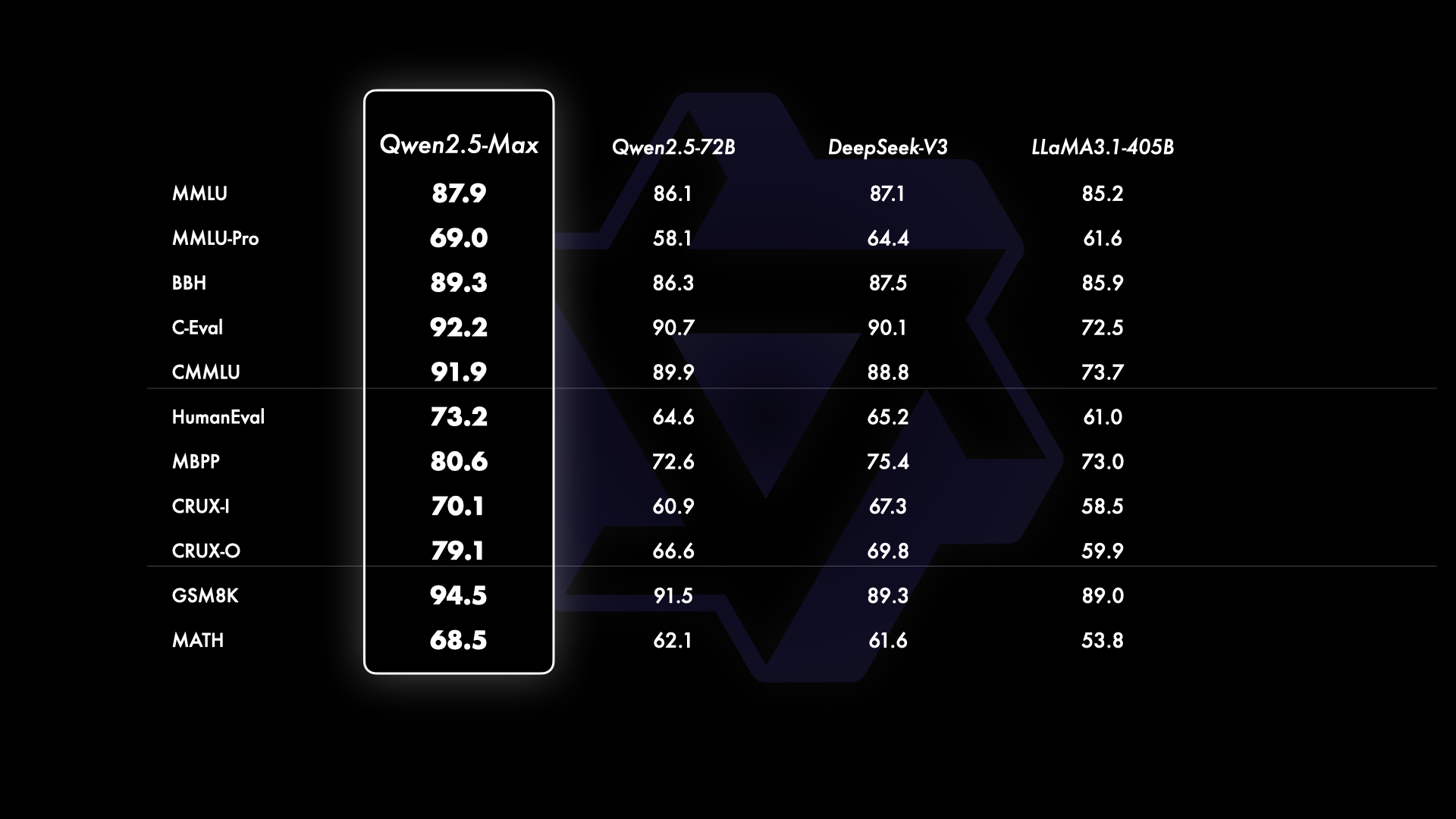
在所有喧嚣中,阿里巴巴推出了Qwen 2.5-Max,这是一个在超过20万亿个标记上训练的大型语言模型。
这家中国科技巨头在农历新年期间发布了该模型,距离DeepSeek R1扰乱市场仅几天。
基准测试显示,Qwen 2.5-Max在多个关键领域的表现超过了DeepSeek V3,包括编码、数学、推理和一般知识,评估使用的基准包括Arena-Hard、LiveBench、LiveCodeBench和GPQA-Diamond。
根据模型卡,该模型在与行业领导者如GPT-4o和Claude 3.5-Sonne的竞争中表现出色。
图片:阿里巴巴
阿里巴巴通过其云平台提供该模型,并提供与OpenAI兼容的API,允许开发者使用熟悉的工具和方法进行集成。
公司的文档展示了详细的实施示例,表明其推动广泛采用的意图。
但阿里巴巴的Qwen Chat网页门户是普通用户的最佳选择,似乎相当令人印象深刻——对于那些愿意在此创建账户的人来说。它可能是目前可用的最通用的AI聊天机器人界面。
Qwen Chat允许用户无缝生成文本、代码和图像。它还支持网页搜索功能、文物,甚至一个非常好的视频生成器,所有这些都在同一个用户界面中——完全免费。
它还有一个独特的功能,用户可以选择两个不同的模型进行“对战”,以提供最佳响应。
总体而言,Qwen的用户界面比艾伦AI的更为多样化。
在文本响应中,Qwen2.5-Max在创意写作和涉及语言分析的推理任务中表现优于Tülu 3。例如,它能够生成以特定单词结尾的短语。
它的视频生成器是一个不错的补充,可以说与Kling或Luma Labs等产品相当——绝对优于Sora的生成能力。
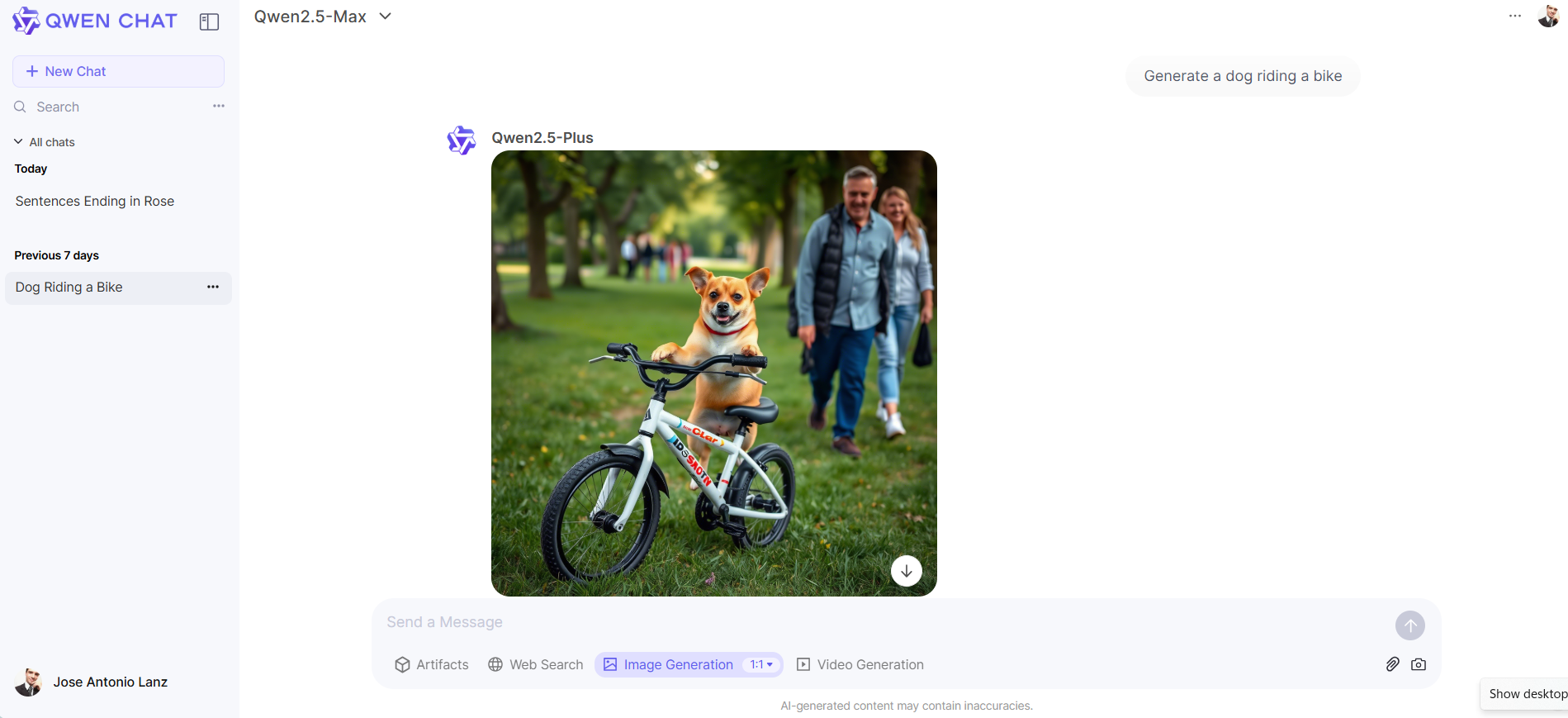
此外,它的图像生成器提供逼真且令人愉悦的图像,显示出明显优于OpenAI的DALL-E 3,但明显落后于Flux或MidJourney等顶级模型。
DeepSeek、Qwen2.5-Max和Tülu 3的三重发布为开源AI世界带来了相当大的推动。
DeepSeek已经通过使用早期的Qwen技术进行蒸馏构建其R1推理模型而引起了广泛关注,证明了开源AI可以以极低的成本与数十亿美元的科技巨头相匹敌。
而现在,Qwen2.5-Max则进一步提升了赌注。如果DeepSeek遵循其既定的策略——利用Qwen的架构——其下一个推理模型可能会更具威力。
不过,这对艾伦研究所来说可能是一个良机。OpenAI正在竞相推出其o3推理模型,一些行业分析师估计,用户每次查询的费用可能高达$1,000。
如果是这样,Tülu 3的到来可能是一个很好的开源替代方案——尤其是对于那些因安全问题或监管要求而对构建中国技术持谨慎态度的开发者。
编辑:Josh Quittner 和 Sebastian Sinclair
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








