Google I/O 2025 从来不是关于微妙的。今年,公司放弃了渐进主义,推出了一系列生成性 AI 升级,旨在重新绘制搜索、视频和数字创意的地图。
关键:Gemini,谷歌的下一代模型家族,现在为从搜索结果到视频合成和高分辨率图像创建的一切提供动力——在一场越来越由 AI 生成速度和原生性定义的竞赛中开辟新领域。
引人注目的是 Veo 3,谷歌首个 AI 视频生成器,不仅创建视觉效果,还生成完整的音轨——环境噪音、效果,甚至对话——与画面直接同步。文本和图像提示输入,完全制作的 4K 视频输出。
这标志着首个能够同时生成音频和视觉的大规模视频模型——这一趋势始于 Showrunner Alpha,一个未发布的模型,但 Veo3 提供了更大的多样性,生成超越简单 2D 卡通动画的各种风格。
“我们正进入一个结合音频和视频生成的新创作时代,”谷歌实验室副总裁 Josh Woodward 在发布会上表示。这是对当前视频生成领导者——Kling、Hunyuan、Luma、Wan 和 OpenAI 的 Sora——的直接挑战,将 Veo 定位为一体化解决方案,而不是需要多个工具。
与 Veo3 一起,Imagen 4——谷歌最新版本的图像生成模型——以增强的照片真实感、2K 分辨率到来,或许最重要的是,文本渲染实际上适用于标识、产品和数字模型。
对于任何经历过之前 AI 图像模型生成的无意义文本的人来说,Imagen 4 代表了显著的改进。
这些工具并不是孤立存在的。Flow AI,一个面向专业用户的新订阅功能,将 Veo、Imagen 和 Gemini 的语言能力结合成一个统一的电影制作和场景编辑环境。但这种整合是有代价的——在促销期间,访问完整工具包的费用为每月 125 美元,之后将开始收取全额 250 美元的费用。

图片:谷歌
Gemini:为搜索和“文本扩散”提供动力
生成性 AI 不仅仅是为内容创作者服务。Gemini 2.5 现在构成了公司重新设计的搜索引擎的核心,谷歌希望将其从链接聚合器演变为一个动态的、对话式的界面,处理复杂查询并提供综合的、多来源的答案。
AI 概述——谷歌 Gemini 尝试在不要求用户点击其他网站的情况下提供全面的查询答案——现在位于搜索页面的顶部,谷歌报告每月有超过 15 亿的用户。
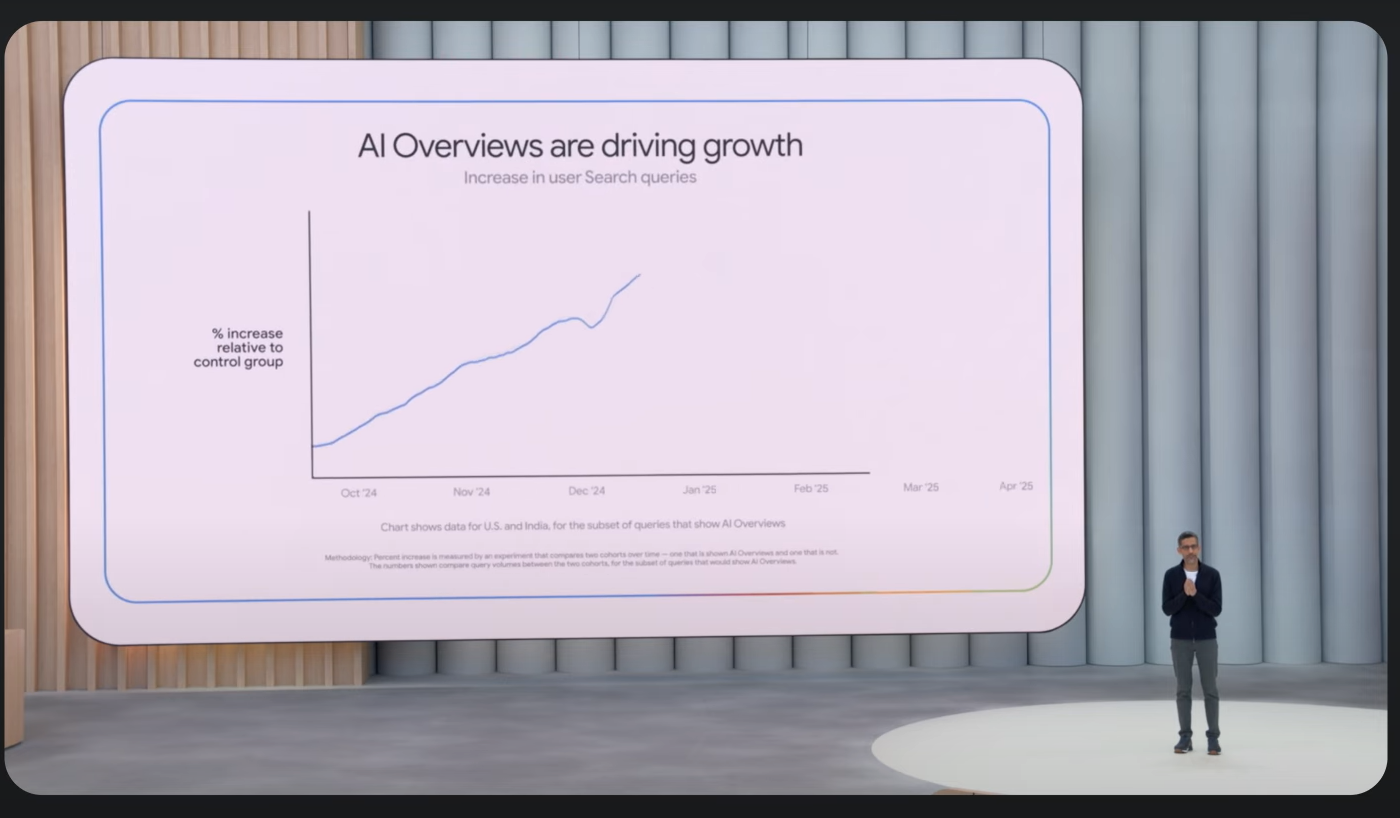
图片:谷歌通过 YouTube
另一个有趣的发展是“Gemini 扩散”,这是几个月前由 Inception Labs 首创的技术。直到最近,AI 社区普遍认为自回归技术最适合文本生成,而扩散技术在图像生成方面表现出色。
自回归模型在读取所有先前生成的内容后生成每个新标记,以确定最佳下一个标记——通过不断回顾提示和先前输出,理想地用于生成连贯的文本响应。
扩散技术的运作方式不同,首先用随机信息填充所有上下文,并在每一步精炼(扩散)输出,以使最终产品与提示匹配——非常适合具有固定画布和美学的图像。
OpenAI 首先成功地将自回归生成应用于图像模型,而现在谷歌成为第一家将扩散生成应用于文本的大型公司。这意味着模型从无意义的内容开始,并在每次迭代中精炼整个输出,以每秒生成数千个标记,同时保持准确性——作为对比,Groq(不是 xAI 的 Grok)是世界上最快的推理提供者之一,每秒生成近 275 个标记,而传统提供者如 OpenAI 或 Anthropic 无法接近这些速度。
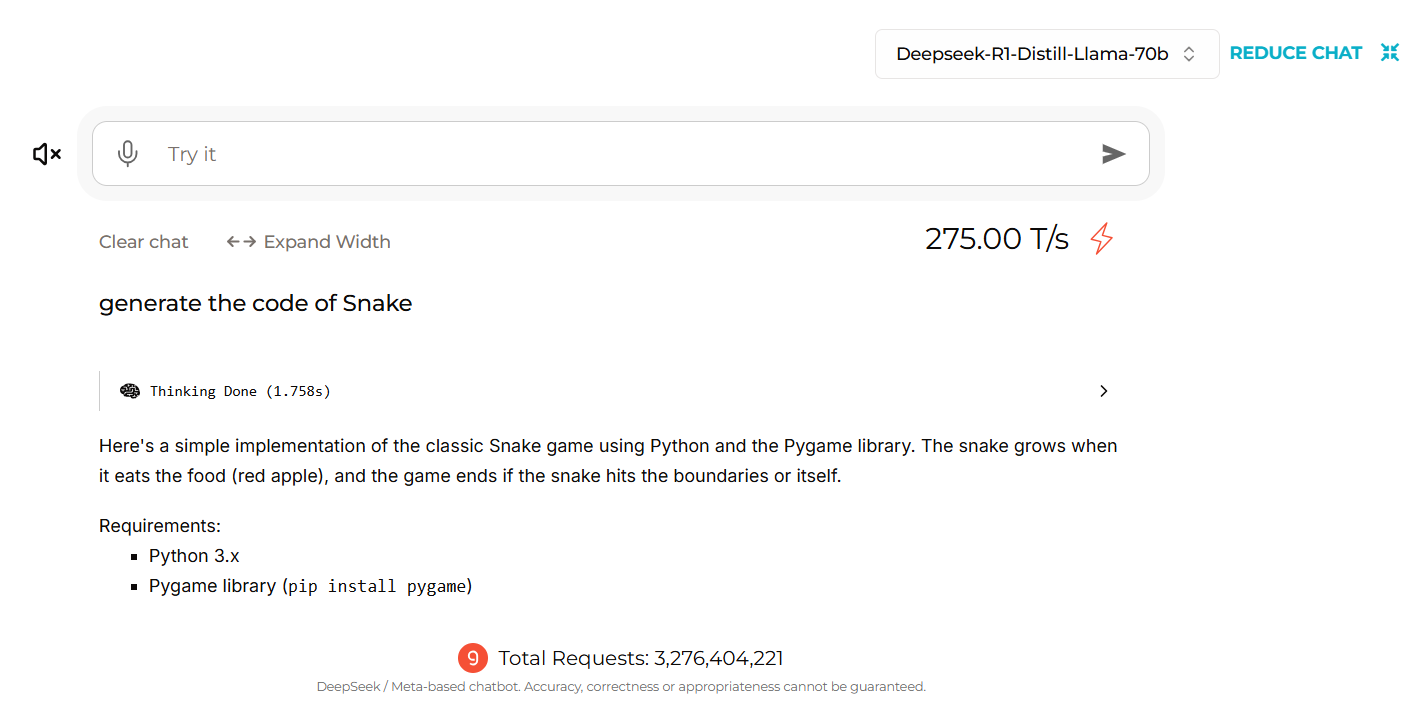
然而,该模型尚未公开可用——感兴趣的用户必须 加入等待名单——但早期采用者分享了令人印象深刻的结果,展示了模型的速度和精确性。
亲身体验谷歌的 AI 工具
我们体验了谷歌的几项新 AI 功能,结果因层级而异。
Deep Research 特别强大——甚至超过了 ChatGPT 的替代品。这个全面的研究代理评估了数百个来源,并以最小的错误提供可靠的信息。
它相较于 OpenAI 的研究代理的优势在于能够生成信息图表。在生成完整的研究文本后,它可以将这些信息浓缩成视觉上吸引人的幻灯片。我们将谷歌最新公告的所有信息输入模型,它通过图表、方案、图形和思维导图呈现了准确的信息。
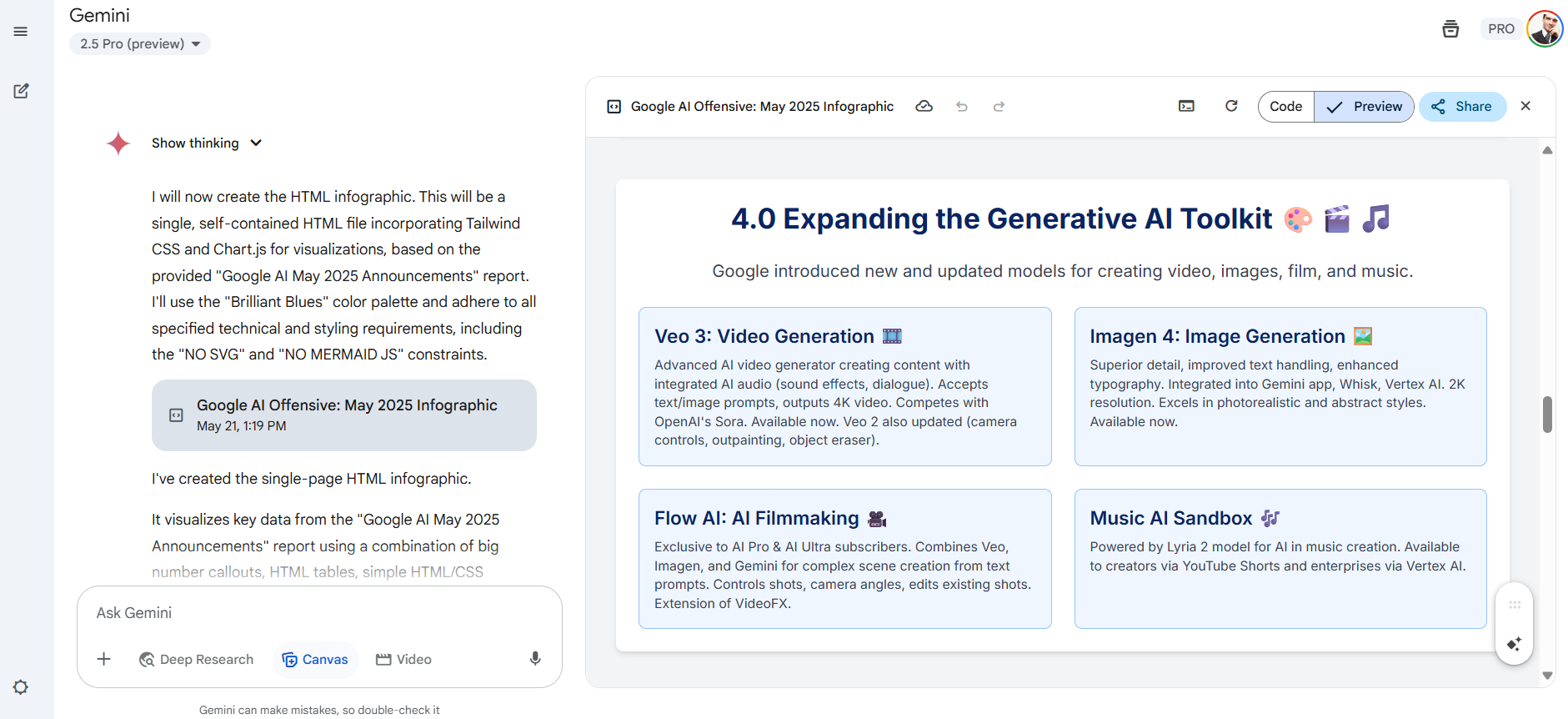
Veo 3 仍然仅限于 Gemini Ultra 用户,尽管一些第三方提供商如 Freepik 和 Fal.ai 已经通过 API 提供访问。除非您选择 Ultra 计划,否则无法尝试 Flow。
Flow 证明是一个直观的视频编辑器,以 Veo 的模型为核心,允许用户使用简单的文本提示编辑、剪切、扩展和修改 AI 场景。
然而,即使是 Veo2 也得到了些许关注,这使得专业用户的生活变得更轻松。现在可访问的 Veo2 生成速度显著更快——我们在大约 30 秒内创建了 8 秒的视频。虽然 Veo2 缺乏声音,目前仅支持文本到视频(图像到视频即将推出),但它理解了我们的提示,甚至生成了连贯的文本。
Veo2 的表现已经与 Kling 2.0 相当——后者被广泛认为是生成视频行业的质量基准。使用 Veo3 的新一代似乎更加真实、连贯,背景音效良好,对话和声音栩栩如生。
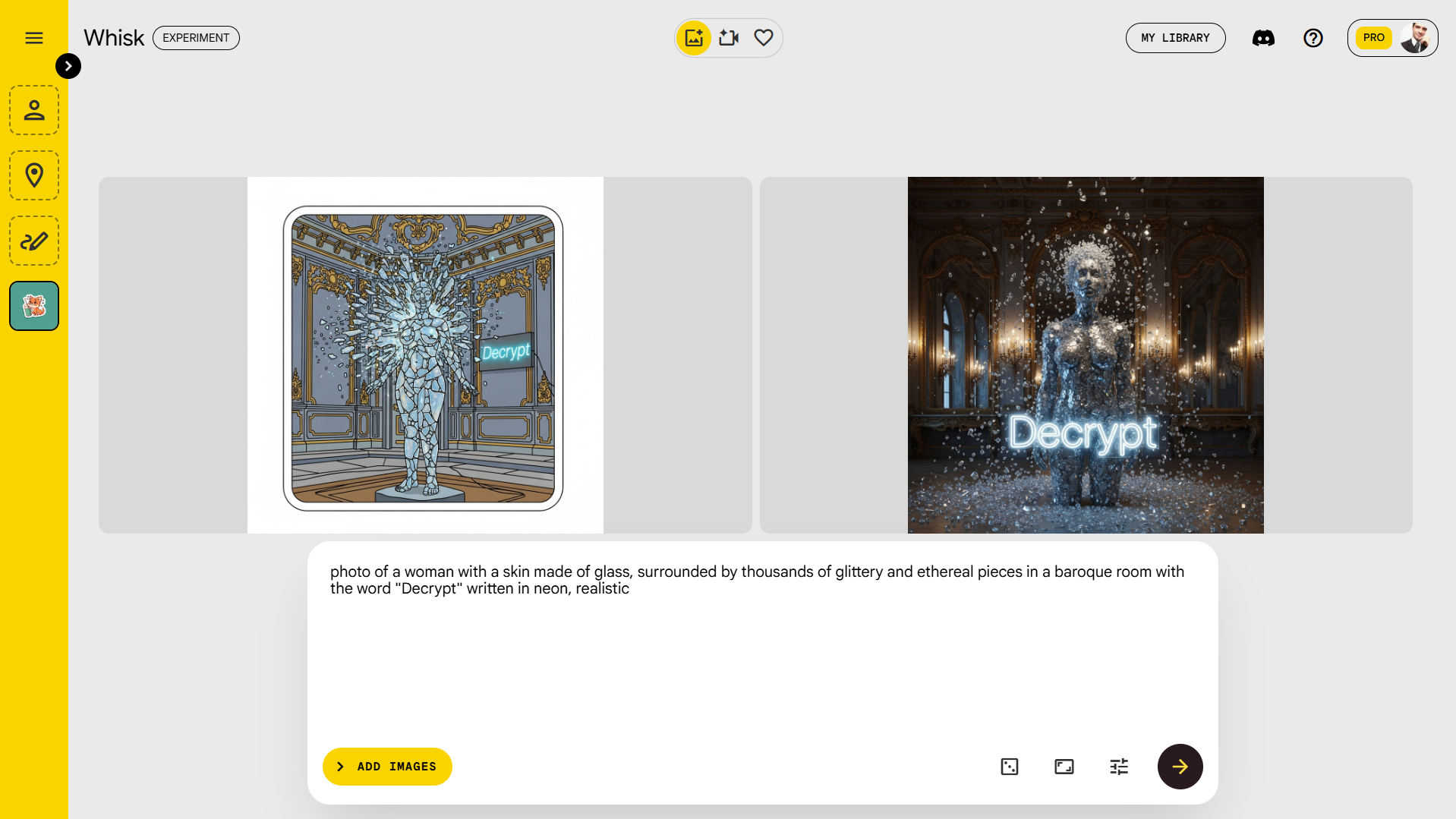
对于 Imagen,乍一看很难确定谷歌在其 Gemini 聊天机器人界面中是否采用了版本 4,还是仍在使用版本 3,尽管用户可以通过 Whisk 确认这一点。我们的初步测试表明,Imagen 4 优先考虑真实感,除非另有说明,具有更好的提示遵循性和超越其前身的视觉效果。
我们生成了一幅包含通常不适合在同一场景中出现的不同元素的图像。我们的提示是“一个女人的照片,皮肤由玻璃制成,周围环绕着成千上万的闪光和空灵的碎片,位于一个巴洛克风格的房间里,墙上用霓虹灯写着‘Decrypt’这个词,真实感十足。”
尽管 Imagen 3 和 Imagen 4 都理解了这个概念和元素,但 Imagen 3 未能捕捉到真实的风格——而 Imagen 4 则轻松做到。总体而言,Imagen 4 可与 SOTA 图像生成器相媲美,特别是考虑到提示的简易性。
音频概述也有所改善,模型现在可以轻松提供超过 20 分钟的完整辩论,而不需要用户切换到 NotebookLM。这使得 Gemini 成为一个更完整的界面,减少了之前用户需要在不同网站之间跳转以获取各种服务的碎片化问题。
其质量可与 NotebookLM 相媲美,平均输出时间稍长。然而,关键特性并不是模型更好,而是它现在嵌入到了 Gemini 的聊天机器人用户界面中。
高端 AI 以高端价格
谷歌并没有掩饰其货币化策略。该公司的“Ultra”计划每月收费 250 美元,捆绑了对最强大模型的优先访问、Flow AI 工具和 30TB 的存储空间——显然是针对电影制作人、严肃创作者和企业。20 美元的“AI Pro”层解锁了谷歌之前的 Veo2 模型,以及面向更广泛用户群的图像和生产力功能。基本的生成工具——如简单的 Gemini Live 和图像创建——仍然是免费的,但有一些限制,比如标记上限和每月仅 10 次研究。
这种分层方法反映了更广泛的 AI 市场趋势:通过免费服务推动大众采用,然后用过于有用的功能锁定专业用户。谷歌的赌注是,真正的行动(和利润)在于高端创意工作和自动化企业工作流程——而不仅仅是随意的提示和 表情包生成。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






