Nvidia首席执行官黄仁勋上周参加了Lex Fridman的播客,并直言:“我认为我们已经实现了AGI。”两天后,人工智能研究中最严格的测试发布了最新的人工通用智能基准——所有前沿模型的得分均低于1%。
ARC奖基金会本周发布了ARC-AGI-3,结果非常严酷。谷歌的Gemini 3.1 Pro以0.37%领先。OpenAI的GPT-5.4得分为0.26%。Anthropic的Claude Opus 4.6得分为0.25%,而xAI的Grok-4.20则得分为零。与此同时,人类解决了100%的环境。
这不是测试常识或编程考试,甚至也不是超难的博士级问题。ARC-AGI-3与人工智能行业以前面临的任何问题截然不同。
基准由François Chollet和Mike Knoop的基金会构建,他们建立了一个内部游戏工作室,从头创建了135个原创互动环境。其想法是将一个AI代理放入一个不熟悉的游戏世界,既没有说明,也没有明确的目标,也没有规则描述。该代理必须探索,弄清楚自己该做什么,形成计划并执行。
如果这听起来像是任何五岁孩子都能做到的事情,那么你开始理解问题了。如果你想看看你是否比人工智能更强,可以通过点击这个链接玩测试中展示的相同游戏。我们试了一个;起初有点奇怪,但几秒钟后,你就能轻松掌握。
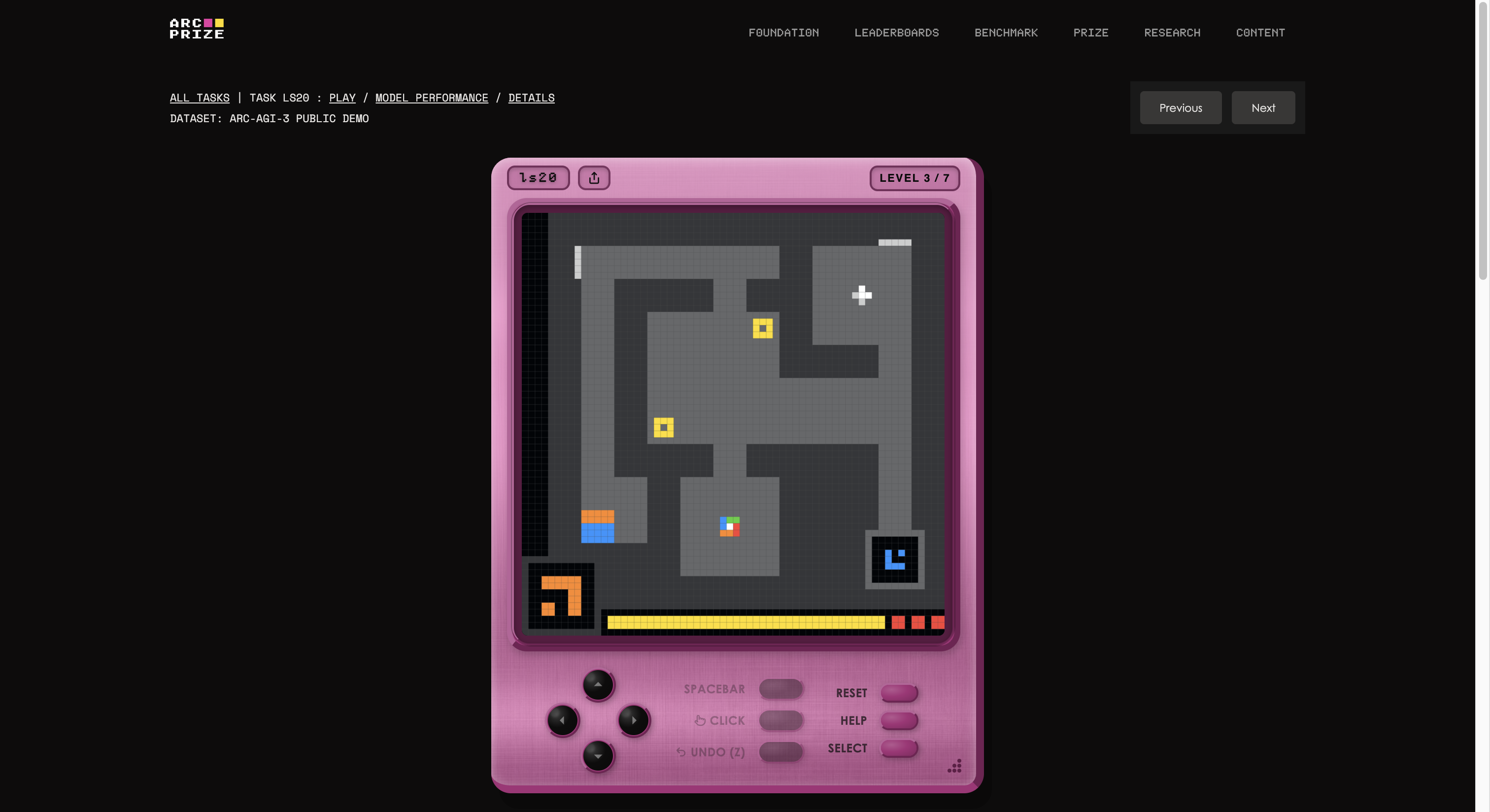
这也是AGI中“G”代表的最清晰例子。当你进行一般化时,你能够在没有事先训练的情况下创造新知识(一个奇怪游戏的运作方式)。
之前版本的ARC测试静态视觉难题——显示一个模式,预测下一个。在最初它们是难的。然后实验室投入计算能力和训练,直到基准几乎失效。2019年推出的ARC-AGI-1被测试时训练和推理模型击败。ARC-AGI-2持续了大约一年之后,Gemini 3.1 Pro达到了77.1%。实验室在他们可以进行训练的基准上非常擅长饱和。
版本3是专门设计来防止这种情况的。在135个环境中,有110个保持私密——55个半私密用于API测试,55个完全锁定用于比赛——没有数据集可供记忆。你无法通过强行处理你从未见过的新游戏逻辑来取得成功。
得分也不是通过/不通过。ARC-AGI-3使用基金会称之为RHAE的标准——相对人类行动效率。基线是第二好的、首次运行的人类表现。一个AI如果采取的人类行动次数是十倍,则在该级别得分1%,而不是10%。公式对低效的惩罚是平方的。四处游荡、回溯和猜测答案会受到严惩。
在一个月的开发者预览中,表现最好的AI代理得分为12.58%。通过官方API测试的前沿LLM,在没有自定义工具的情况下,未能突破1%。普通人解决了所有135个环境,没有事先训练和说明。如果这就是标准,那么当前的模型并没有达到。
这里有一个真实的方法论争论。ARC的报告称,杜克大学建造的定制工具使Claude Opus 4.6在一个名为TR87的环境变体中从0.25%提高到97.1%。这并不意味着Claude在ARC-AGI-3上的总体得分是97.1%;它的官方基准得分仍然是0.25%,但这一变化仍然值得注意。
官方基准向代理提供JSON代码,而不是视觉内容。这要么是方法论的缺陷,要么是证明如今的模型在处理人类友好信息方面优于原始结构化数据。Chollet的基金会承认了这一争论,但没有更改格式。
“框架内容感知和API格式不是对ARC-AGI-3的前沿模型性能的限制因素,”论文中写道。换句话说,他们似乎拒绝了模型失败的观点,因为它们“无法正确看到”任务,而是认为感知已经足够——而真正的差距在于推理和一般化。
AGI的现实检验是在一周的 hype 机器全速运转期间到来的。除了黄仁勋的评论,Arm还将其新的数据中心芯片命名为“AGI CPU”。OpenAI的Sam Altman表示他们“基本上建立了AGI”,而微软已经在营销一个专注于构建ASI的实验室:在实现AGI后发展的演变。这个术语似乎被扩展到意味着任何商业上的方便的东西。
Chollet的立场更简单。如果一个普通人没有说明也能做到,而你的系统却不能,那么你没有AGI——你只有一个需要大量帮助的非常昂贵的自动补全。
ARC奖2026将提供200万美元,分为三个比赛赛道,所有赛道都在Kaggle上进行。每个获胜解决方案必须开源。时间在流逝,而目前机器甚至远未接近。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







