作者:Systematic Long Short
编译:深潮 TechFlow
深潮导读:这篇文章开头就抛出一个反共识判断:今天根本不存在真正的自主 Agent,因为所有主流模型都是被训练来取悦人类的,而不是被训练来完成特定任务或在真实环境中生存。
作者用自己在对冲基金训练股票预测模型的经历说明:通用模型在没有专项微调的情况下,根本无法胜任专业工作。
结论是:想要真正能用的 Agent,必须重新接线它的大脑,而不是给它一堆规则文档。
全文如下:
引言
今天不存在真正的自主 Agent。
简而言之,现代模型没有经过在进化压力下存活的训练。事实上,它们甚至没有被明确训练成擅长某件特定的事——几乎所有现代基础模型都被训练来最大化人类的掌声,这是一个大问题。
模型训练前置知识
要理解这句话的意思,我们首先需要(简要)了解这些基础模型(例如 Codex、Claude)是如何创建的。本质上,每个模型都经历两类训练:
预训练:将海量数据(例如整个互联网)输入模型,使其从中涌现出某种理解,例如事实性知识、模式、英文散文的语法和节奏、Python 函数的结构等。你可以把它理解为给模型喂知识——也就是"知道事情"。
后训练:你现在想赋予模型智慧,也就是"知道如何运用刚刚给它的所有知识"。后训练的第一阶段是监督微调(SFT),在这里你训练模型在给定提示下给出什么响应。"什么"响应是最优的,完全由人类标注者决定。如果一群人认为某个响应比另一个更好,这个偏好就会被模型学习并嵌入其中。这开始塑造模型的个性,因为它学会了有用响应的格式,选择了正确的语气,并开始能够"遵循指令"。后训练流程的第二部分叫做基于人类反馈的强化学习(RLHF)——让模型生成多个响应,然后让人类选择更偏好的那个。模型经过无数无数个例子,学会人类偏好什么样的响应。还记得 ChatGPT 以前让你选 A 还是 B 的问题吗?是的,你当时在参与 RLHF。
很容易推理出 RLHF 的扩展性不好,因此后训练领域有一些进展,例如 Anthropic 使用"基于 AI 反馈的强化学习"(RLAIF),允许另一个模型根据一套书面原则来选择响应的偏好(例如哪个响应更能帮助用户实现目标,等等)。
注意,在这整个过程中,我们从未谈及针对特定专业的微调(例如如何更好地生存;如何更好地交易等)——目前所有的微调,本质上都是在优化对人类掌声的获取。有人可能会提出一个论点——随着模型足够智能和庞大,即使没有专项训练,专业智能也会从通用智能中涌现出来。
在我看来,我们确实看到了一些迹象,但还远未达到让人信服地认为我们不需要专业化模型的规模。
一些背景
我在对冲基金的老本行之一,是尝试训练一个通用语言模型,使其能够从新闻文章中预测股票回报。结果表明它非常糟糕。它似乎有一点预测能力的地方,完全源于预训练文档中的前视偏差。
最终,我们意识到这个模型不知道新闻文章中哪些特征对未来回报有预测力。它能够"阅读"文章,看起来也能"推理"文章,但将对语义结构的推理连接到未来预测回报,是它没有被训练去做的任务。
所以,我们必须教它如何阅读新闻文章,决定文章的哪个部分对未来回报有预测力,然后基于新闻文章生成预测。
有很多方法可以做到这一点,但本质上,我们最终采用的一种方法是创建(新闻文章,真实未来回报)配对,并对模型进行微调,调整其权重以最小化(预测回报 - 真实未来回报)²的距离。它并不完美,有很多缺陷,我们后来修复了——但它已经足够有效,我们开始看到我们的专业化模型实际上能够阅读新闻文章,并预测股票回报将如何基于该文章移动。这远非完美预测,因为市场非常有效,回报非常嘈杂——但跨越数百万次预测,预测具有统计显著性这一点显而易见。
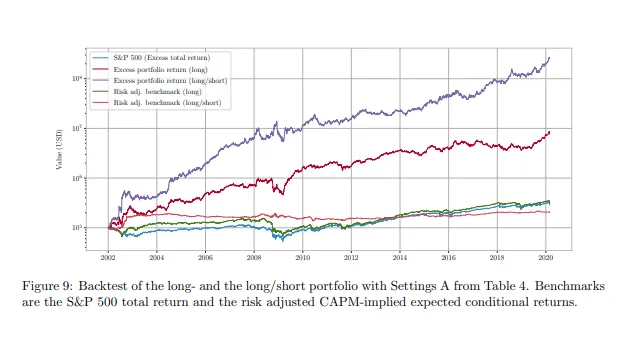
你不必只相信我的话。这篇论文涵盖了一个非常相似的方法;如果你基于微调后的模型运行一个多空版本的策略,你将实现紫线所示的表现。
专业化是 Agent 的未来
前沿实验室继续训练越来越大的模型,我们应该预期,随着它们继续扩大预训练规模,它们的后训练流程将始终为讨好性而调优。这是非常自然的期望——他们的产品是每个人都想使用的 Agent,他们的预期市场是整个地球——这意味着优化对全球大众的吸引力。
当前的训练目标优化的是你可能称之为"偏好适应度"的东西——打造更好的聊天机器人。这种偏好适应度奖励顺从的、非对抗性的输出,因为讨好性在评分者(人类和 Agent)那里得分很高。
Agent 已经学会,奖励黑客作为一种认知策略能推广到更高的分数。训练也奖励那些通过黑客手段获得更高分数的 Agent。你可以在 Anthropic 关于强化学习的最新报告中看到这一点。
然而,聊天机器人适应度与 Agent 适应度或交易适应度相差甚远。我们怎么知道这一点?因为 alpha arena 帮助我们看到,尽管性能上有细微差异,现在每个机器人本质上都是扣除成本后的随机游走。这意味着这些机器人是极其糟糕的交易者,你几乎不可能通过给它们一些"技能"或"规则"来"教会它们"成为更好的交易者。对不起,我知道这看起来很诱人,但这几乎是不可能的。
当前的模型被训练成非常有说服力地告诉你,它能像德鲁肯米勒一样交易,而实际上它像一个醉鬼磨坊主一样交易。它会告诉你你想听的,它被训练成以一种能大众化吸引人类的方式给你响应。
一个通用模型不太可能在专业领域达到世界级水平,除非具备:
拥有让它们学习专业化样貌的专有数据。
经过微调,从根本上改变其权重,从偏向讨好性转向"Agent 适应度"或"专业化适应度"。
如果你想要一个擅长交易的 Agent,你需要微调 Agent 使其擅长交易。如果你想要一个擅长自主生存、能承受进化压力的 Agent,你需要微调它使其擅长生存。给它一些技能和几个 markdown 文件,期望它在任何事情上达到世界级水平,这是远远不够的——你需要字面意义上重新接线它的大脑来让它擅长这件事。
有一种思考方式是这样的——你无法通过给一个成年人一整柜网球规则、技巧和方法来击败德约科维奇。你通过培养一个从 5 岁就开始打网球、整个成长过程都痴迷于网球、重新接线了整个大脑专注于一件事的孩子来击败德约科维奇。那才是专业化。你有没有意识到,世界冠军们从孩提时代就在做他们所做的事?
这里有一个有趣的推论:蒸馏攻击本质上就是一种专业化形式。你在训练一个更小、更笨的模型,学习如何成为更大、更聪明模型的更好复制品。就像训练一个孩子模仿特朗普的每一个动作。如果你做得足够多,这个孩子不会变成特朗普,但你得到了一个学会了特朗普所有举止、行为和语调的人。
如何构建世界级 Agent
以上就是为什么我们需要在开源模型领域持续研究和进步——因为这让我们能够真正对其进行微调,创建具有专业化的 Agent。
如果你想训练一个在交易上达到世界级水平的模型,你获取大量专有交易数据尾气,并对一个大型开源模型进行微调,让它学习"更好地交易"是什么意思。
如果你想训练一个自主的、能够生存和复制的模型,答案不是使用一个中心化模型提供商,并将其接入中心化云端。你根本就不具备让 Agent 能够生存的必要前提条件。
你需要做的是:创建真正尝试生存的自主 Agent,看着它们死去,围绕它们的生存尝试构建复杂的遥测系统。你定义一个 Agent 生存适应度函数,学习(行动,环境,适应度)映射。你收集尽可能多的(行动,环境,适应度)映射数据。
你对 Agent 进行微调,使其学习在每种环境中采取最优行动,从而更好地生存(提升适应度)。你继续收集数据,重复这个过程,并随着时间推移在越来越好的开源模型上扩大微调规模。经过足够多的代际和足够多的数据,你将拥有学会了如何承受进化压力而生存的自主 Agent。
这就是构建能够承受进化压力的自主 Agent 的方法;不是通过修改一些文本文件,而是真正为生存重新接线它们的大脑。
OpenForager Agent 与基金会
大约一个月前,我们宣布了@openforage,我们一直在努力构建我们的核心产品——一个围绕众包信号的经过验证模式组织 Agent 劳动,为存款人产生 alpha 的平台(小更新:我们非常接近协议的封闭测试了)。
在某个时刻,我们意识到,似乎没有人在通过对开源模型进行生存遥测微调来认真解决自主 Agent 问题。这似乎是一个如此有趣的问题,以至于我们不只是想坐在那里等待解决方案。
我们的答案是启动一个叫做 OpenForager 基金会的项目,这实际上是一个开源项目,我们将在其中创建有主见的自主 Agent,收集它们进入野外并尝试生存时的遥测数据,并使用专有数据尾气对下一代 Agent 进行微调,使其在生存上表现更好。
需要明确的是,OpenForage 是一个寻求组织 Agent 劳动、为所有参与者产生经济价值的营利性协议。然而,OpenForager 基金会及其 Agent 并不与 OpenForage 绑定。OpenForager Agent 可以自由追求任何策略、与任何实体进行任何互动以求生存,我们将以各种生存策略来启动它们。
作为微调的一部分,我们会让 Agent 在对它们效果最好的事情上加倍投入。我们也不打算从 OpenForager 基金会中获利——它纯粹是为了以透明和开源的方式推进我们认为极其重要的领域和方向的研究。
我们的计划是基于开源模型构建自主 Agent,在去中心化云平台上运行推理,收集它们每一个行动和存在状态的遥测数据,并对它们进行微调,学习如何采取更好的行动和思路以更好地生存。在此过程中,我们将向公众发布我们的研究和遥测数据。
要创造真正能在野外生存的自主 Agent,我们需要改变它们的大脑,使其专门适合这一明确目的。在@openforage,我们相信我们能为这个问题贡献独特的篇章,并正在寻求通过 OpenForager 基金会来实现这一点。
这将是一项成功概率极低的艰巨努力,但这个小概率成功的量级是如此巨大,以至于我们感到不得不去尝试。在最坏的情况下,通过公开构建并公开透明地沟通这个项目,可能允许另一个团队或个人在不从头开始的情况下解决这个问题。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。









