Qwen3 is more aligned with human preferences, excelling in creative writing, role-playing, multi-turn dialogue, and instruction following, thus providing a more natural, engaging, and authentic conversational experience.
Author: New Intelligence Source

【New Intelligence Source Guide】Alibaba's Qwen3 was open-sourced early this morning, officially claiming the throne of the world's largest open-source model! Its performance comprehensively surpasses DeepSeek-R1 and OpenAI o1, utilizing a MoE architecture with a total of 235B parameters, sweeping across major benchmarks. This time, the open-sourced Qwen3 family includes 8 hybrid reasoning models, all open-sourced for free commercial use.
Just this morning, the highly anticipated new generation of Alibaba's universal Qwen model, Qwen3, was open-sourced!
Upon its release, it immediately topped the global strongest open-source model throne.
Its parameter count is only 1/3 of DeepSeek-R1, but the cost has significantly decreased, and its performance comprehensively surpasses R1, OpenAI-o1, and other top global models.
Qwen3 is the first "hybrid reasoning model" in the country, integrating "fast thinking" and "slow thinking" into the same model, allowing for low-computation "instant answers" to simple needs and multi-step "deep thinking" for complex problems, greatly saving computational power consumption.
It employs a mixture of experts (MoE) architecture, with a total parameter count of 235B, activating only 22B.
Its pre-training data volume reaches 36T, and in the post-training phase, multi-turn reinforcement learning seamlessly integrates non-thinking modes into the thinking model.
Upon its birth, Qwen3 immediately swept across major benchmarks.
Moreover, while its performance has significantly improved, its deployment cost has also drastically decreased, requiring only 4 H20s to deploy the full version of Qwen3, with memory usage only 1/3 of similar performance models!
Highlights Summary:
· Various sizes of dense models and mixture of experts (MoE) models, including 0.6B, 1.7B, 4B, 8B, 14B, 32B, as well as 30B-A3B and 235B-A22B.
· Capable of seamlessly switching between thinking mode (for complex logical reasoning, mathematics, and coding) and non-thinking mode (for efficient general chatting), ensuring optimal performance in various scenarios.
· Significantly enhanced reasoning ability, surpassing previous models in thinking mode like QwQ and in non-thinking mode like Qwen2.5 instruct in mathematics, code generation, and common-sense logical reasoning.
· More aligned with human preferences, excelling in creative writing, role-playing, multi-turn dialogue, and instruction following, thus providing a more natural, engaging, and authentic conversational experience.
· Proficient in AI agent capabilities, supporting precise integration with external tools in both thinking and non-thinking modes, achieving leading performance in complex agent-based tasks among open-source models.
· First to support 119 languages and dialects, with strong multilingual instruction following and translation capabilities.
Currently, Qwen 3 has been simultaneously launched on the Modao community, Hugging Face, and GitHub, and can be experienced online.
Global developers, research institutions, and enterprises can download the model for free and for commercial use, and can also call Qwen3's API service through Alibaba Cloud's Bailian. Individual users can immediately experience Qwen3 directly through the Tongyi APP, and Quark will soon fully integrate Qwen3.
Online Experience:
Modao Community:
https://modelscope.cn/collections/Qwen3-9743180bdc6b48
Hugging Face:
https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
GitHub:
https://github.com/QwenLM/Qwen3
As of now, Alibaba Tongyi has open-sourced over 200 models, with global downloads exceeding 300 million times, and the number of Qwen derivative models surpassing 100,000, completely surpassing the American Llama, becoming the world's first open-source model!
Qwen 3 Family Debuts
8 "Hybrid Reasoning" Models Fully Open-Sourced
This time, Alibaba has open-sourced 8 hybrid reasoning models at once, including 2 MoE models of 30B and 235B, as well as 6 dense models of 0.6B, 1.7B, 4B, 8B, 14B, and 32B, all under the Apache 2.0 license.
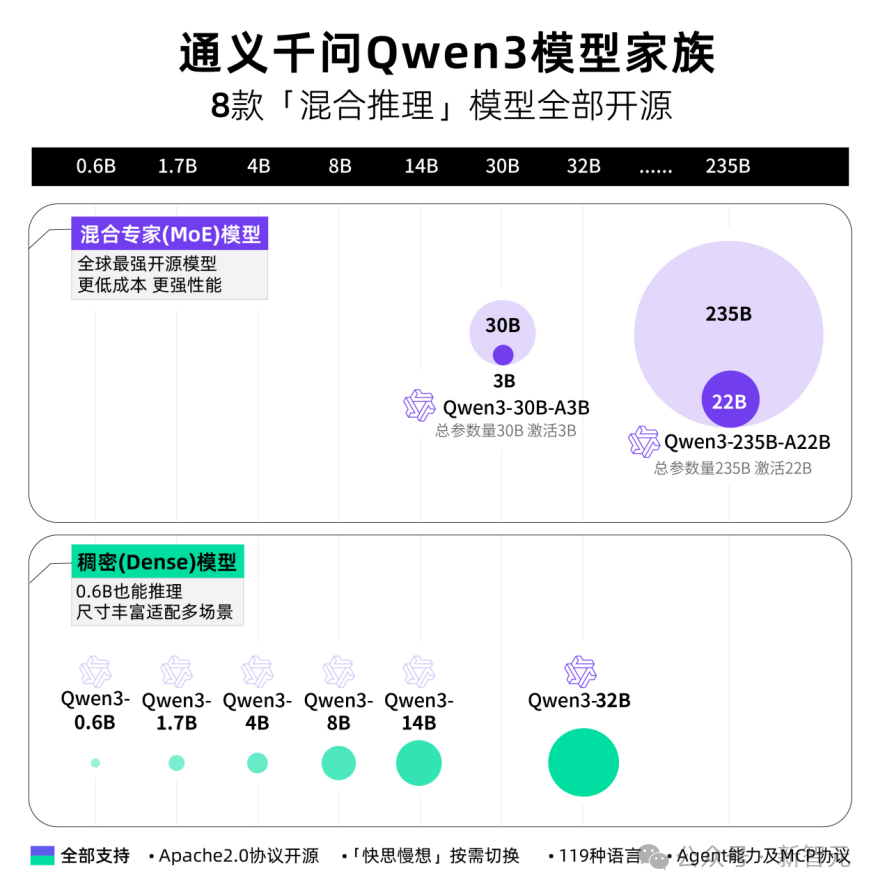
Among them, each model has achieved SOTA in open-source models of the same size.
The 30B parameter MoE model of Qwen3 has achieved over 10 times the model performance leverage, with only 3B activated, comparable to the performance of the previous Qwen2.5-32B model.
The performance of Qwen3's dense models continues to break through, achieving the same high performance with half the parameter count, such as the 32B version of the Qwen3 model, which can surpass the performance of Qwen2.5-72B.
At the same time, all Qwen3 models are hybrid reasoning models, and the API can set the "thinking budget" (i.e., the expected maximum number of tokens for deep thinking) as needed, allowing for varying degrees of thinking to flexibly meet the diverse needs for performance and cost in AI applications and different scenarios.
For example, the 4B model is an excellent size for mobile devices; the 8B can be smoothly deployed in applications on computers and cars; the 32B is the most popular for large-scale enterprise deployment, and developers with conditions can easily get started.
New King of Open-Source Models, Breaking Records
Qwen3 has significantly enhanced reasoning, instruction following, tool calling, and multilingual capabilities, setting a new performance high for all domestic models and global open-source models—
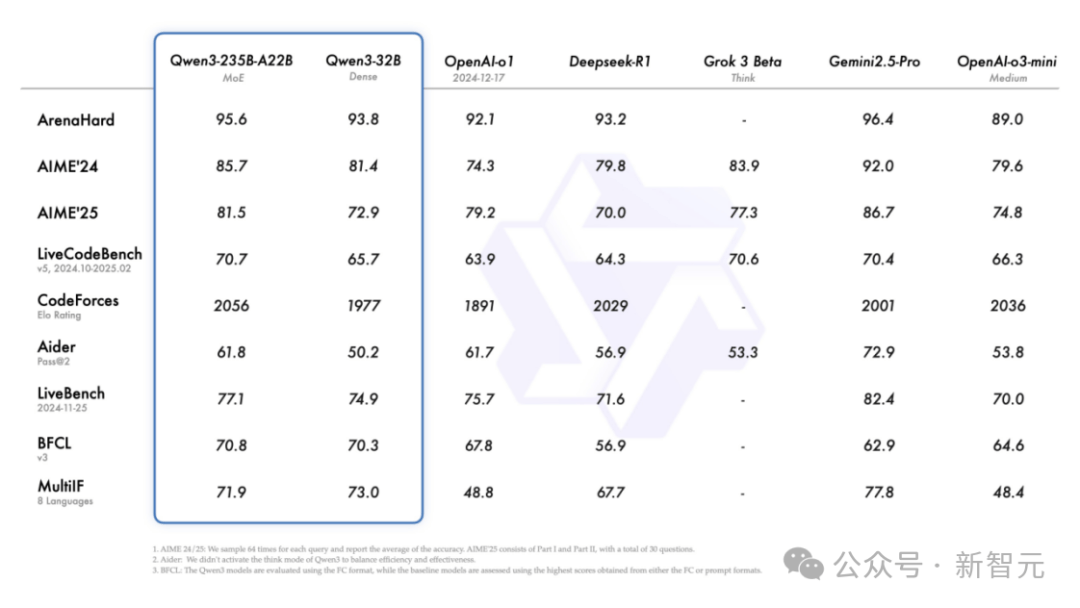
In the AIME25 evaluation at the level of Olympiad mathematics, Qwen3 scored 81.5, breaking the open-source record.
In the LiveCodeBench evaluation assessing coding ability, Qwen3 broke the 70-point barrier, even outperforming Grok3.
In the ArenaHard evaluation assessing model alignment with human preferences, Qwen3 scored 95.6, surpassing OpenAI-o1 and DeepSeek-R1.

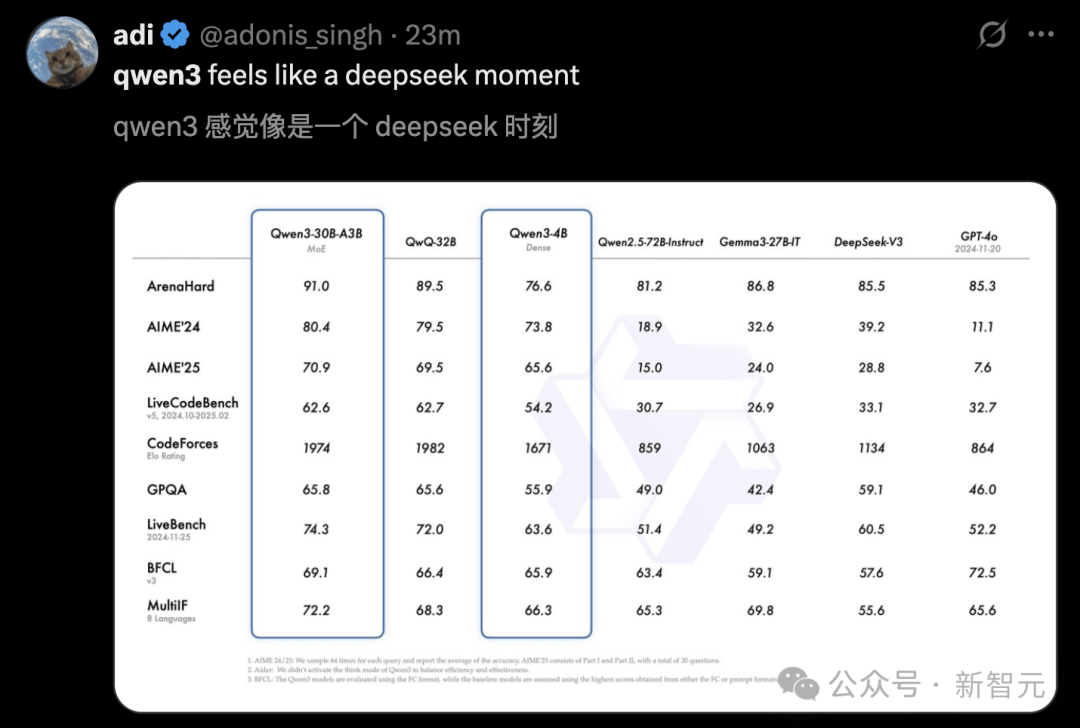
Specifically, the flagship model Qwen3-235B-A22B has shown impressive results in coding, mathematics, and general capabilities across various benchmark tests compared to other top models (such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro).
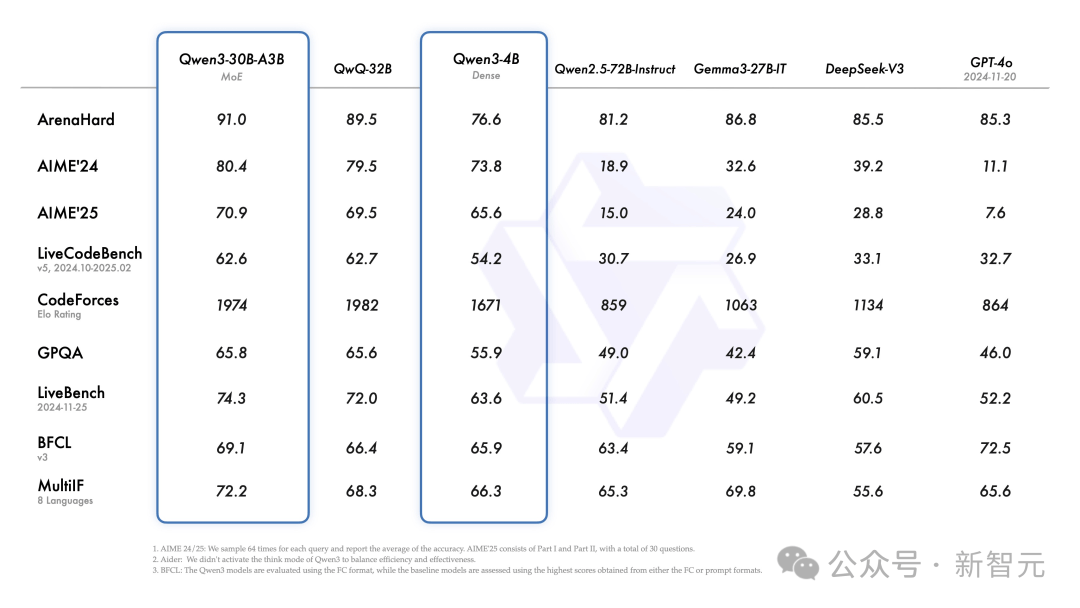
Additionally, the small hybrid expert model Qwen3-30B-A3B, despite having only one-tenth the activated parameters of QwQ-32B, performs even better.
Even a small model like Qwen3-4B can match the performance of Qwen2.5-72B-Instruct.
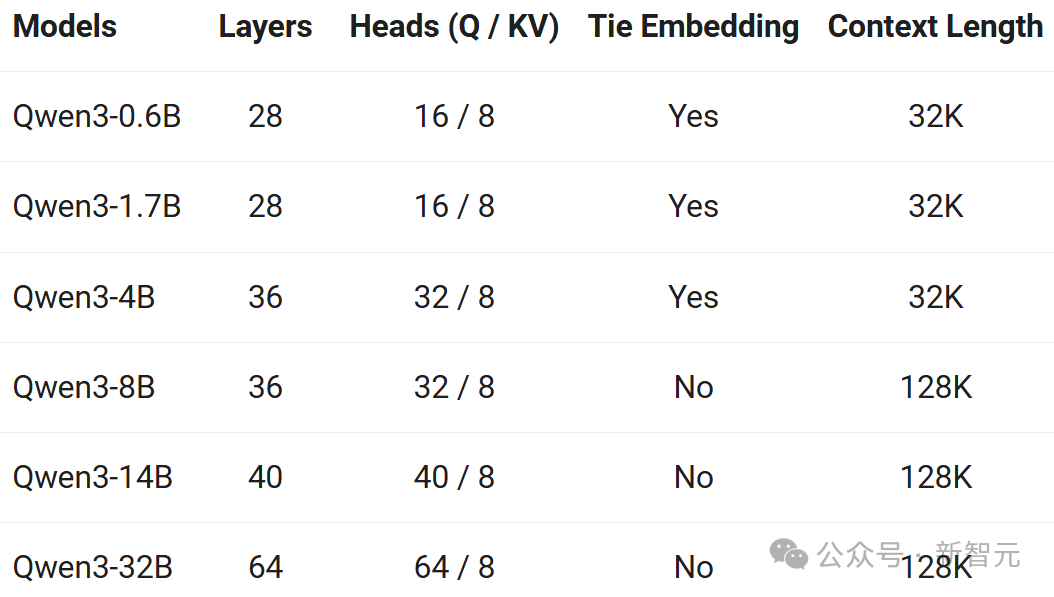
Fine-tuned models, such as Qwen3-30B-A3B, and their pre-trained versions (like Qwen3-30B-A3B-Base), can now be found on platforms like Hugging Face, ModelScope, and Kaggle.
For deployment, Alibaba recommends using frameworks like SGLang and vLLM. For local use, tools like Ollama, LMStudio, MLX, llama.cpp, and KTransformers are strongly recommended.
Whether for research, development, or production environments, Qwen3 can be easily integrated into various workflows.
Favorable for Agent and Large Model Application Explosion
It can be said that Qwen3 provides better support for the upcoming explosion of agent and large model applications.
In the BFCL evaluation assessing model agent capabilities, Qwen3 set a new high of 70.8, surpassing top models like Gemini2.5-Pro and OpenAI-o1, which will significantly lower the threshold for agent tool calling.
At the same time, Qwen3 natively supports the MCP protocol and possesses strong tool calling capabilities, combined with the Qwen-Agent framework that encapsulates tool calling templates and tool calling parsers.
This will greatly reduce coding complexity, enabling efficient tasks such as mobile and computer agent operations.
Main Features
Hybrid Reasoning Mode
The Qwen3 model introduces a hybrid problem-solving approach. It supports two modes:
Thinking Mode: In this mode, the model will reason step by step and then provide an answer. This is suitable for complex problems that require in-depth thinking.
Non-Thinking Mode: In this mode, the model will quickly provide an answer, suitable for simple problems that require speed.
This flexibility allows users to control the model's reasoning process based on the complexity of the task.
For example, difficult problems can be solved through extended reasoning, while simple questions can be answered directly without delay.
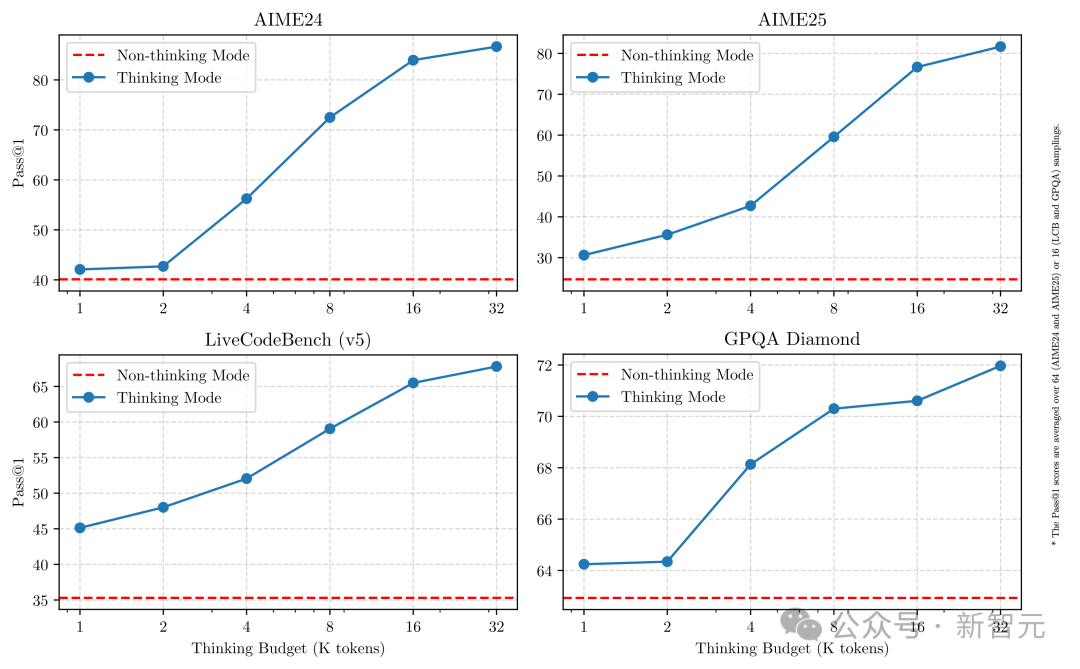
Crucially, the combination of these two modes greatly enhances the model's ability to stably and efficiently control reasoning resources.
As shown above, Qwen3 demonstrates scalable and smooth performance improvements, directly related to the allocated computational reasoning budget.
This design allows users to more easily configure task-specific budgets, achieving a more optimized balance between cost efficiency and reasoning quality.
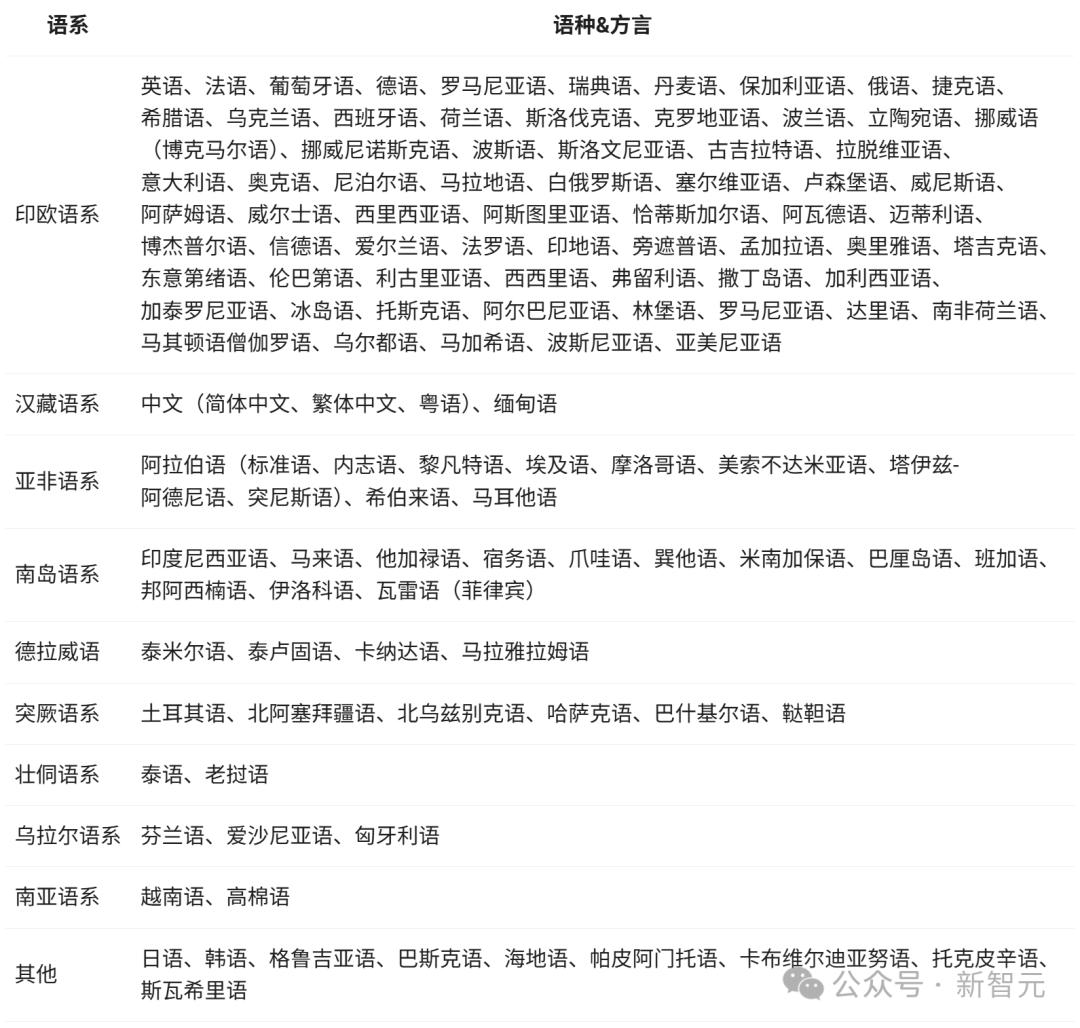
Multilingual Support
The Qwen3 model supports 119 languages and dialects.
Such extensive multilingual capabilities also mean that Qwen 3 has great potential to create internationally popular applications.
More Powerful Agent Capabilities
Alibaba has optimized the Qwen3 model to enhance coding and agent capabilities, and has also strengthened support for MCP.
The following example demonstrates how Qwen3 thinks and interacts with the environment.
36 Trillion Tokens, Multi-Stage Training
As the strongest model in the Qwen series, how did Qwen3 achieve such impressive performance?
Next, let's delve into the technical details behind Qwen3.
Pre-training
Compared to Qwen2.5, the pre-training dataset of Qwen3 is nearly double that of the previous generation, expanding from 18 trillion tokens to 36 trillion tokens.
It covers 119 languages and dialects, sourced not only from the web but also from extracted text content from documents like PDFs.
To ensure data quality, the team utilized Qwen2.5-VL to extract document text and optimized the accuracy of the extracted content through Qwen2.5.
Additionally, to enhance the model's performance in mathematics and coding, Qwen3 generated a large amount of synthetic data through Qwen2.5-Math and Qwen2.5-Coder, including textbooks, Q&A pairs, and code snippets.
The pre-training process of Qwen3 is divided into three stages, gradually enhancing the model's capabilities:
Stage 1 (S1): Basic Language Capability Building
Using over 30 trillion tokens with a context length of 4k for pre-training. This stage lays a solid foundation for the model's language capabilities and general knowledge.
Stage 2 (S2): Knowledge-Dense Optimization
By increasing the proportion of knowledge-dense data such as STEM, coding, and reasoning tasks, the model continues training on an additional 5 trillion tokens, further enhancing its performance in specialized capabilities.
Stage 3 (S3): Contextual Capability Expansion
Utilizing high-quality contextual data, the model's context length is expanded to 32k, ensuring it can handle complex, ultra-long inputs.
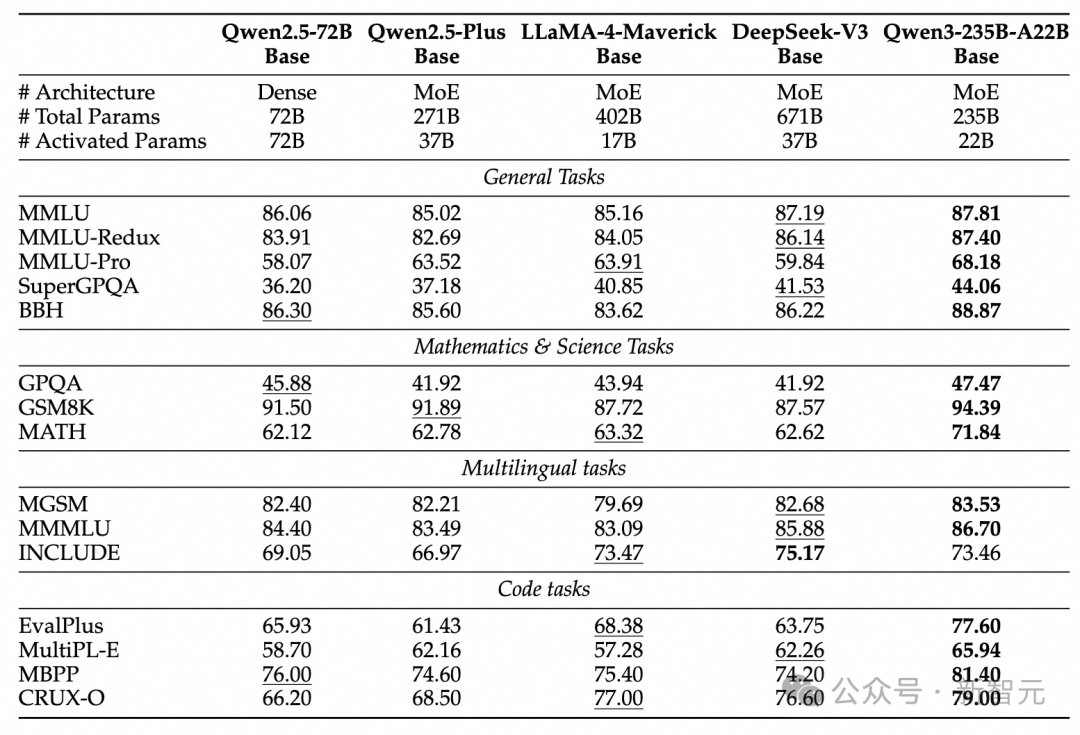
Thanks to model architecture optimization, data scale expansion, and more efficient training methods, the Qwen3 Dense base model demonstrates impressive performance.
As shown in the table below, Qwen3-1.7B/4B/8B/14B/32B-Base can match the performance of Qwen2.5-3B/7B/14B/32B/72B-Base, achieving the level of larger models with fewer parameters.
Notably, in areas such as STEM, coding, and reasoning, the Qwen3 Dense base model even outperforms larger Qwen2.5 models.
Even more remarkable is that the Qwen3 MoE model can achieve performance similar to the Qwen2.5 Dense base model with only 10% of the activated parameters.
This not only significantly reduces training and inference costs but also provides greater flexibility for the model's actual deployment.
Post-training
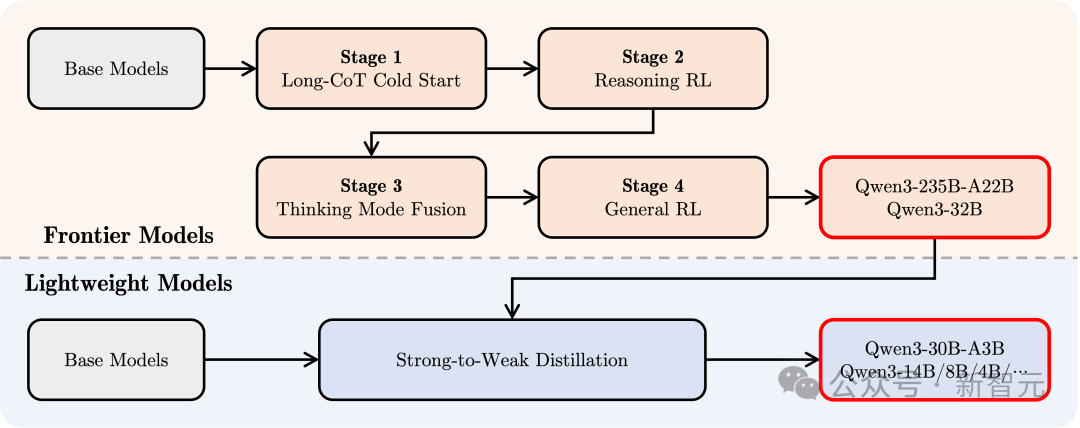
To create a hybrid model capable of both complex reasoning and quick responses, Qwen3 has designed a four-stage post-training process.
1. Long Thinking Chain Cold Start
Using diverse long thinking chain data covering mathematics, coding, logical reasoning, and STEM problems, the model is trained to master basic reasoning abilities.
2. Long Thinking Chain Reinforcement Learning
By expanding the computational resources for RL and combining it with a rule-based reward mechanism, the model's ability to explore and utilize reasoning paths is enhanced.
3. Thinking Mode Fusion
Using long thinking chain data and instruction fine-tuning data for fine-tuning, the model integrates quick response capabilities into the reasoning model, ensuring precision and efficiency in complex tasks.
This data is generated by the enhanced thinking model from the second stage, ensuring a seamless integration of reasoning and quick response capabilities.
4. General Reinforcement Learning
Applying RL in over 20 general domain tasks, such as instruction following, format adherence, and agent capabilities, further enhances the model's generality and robustness while correcting undesirable behaviors.
Widespread Praise Online
Within less than 3 hours of its open-source release, Qwen3 garnered 17k stars on GitHub, igniting enthusiasm in the open-source community. Developers rushed to download and began rapid testing.
Project Address:
https://github.com/QwenLM/Qwen3
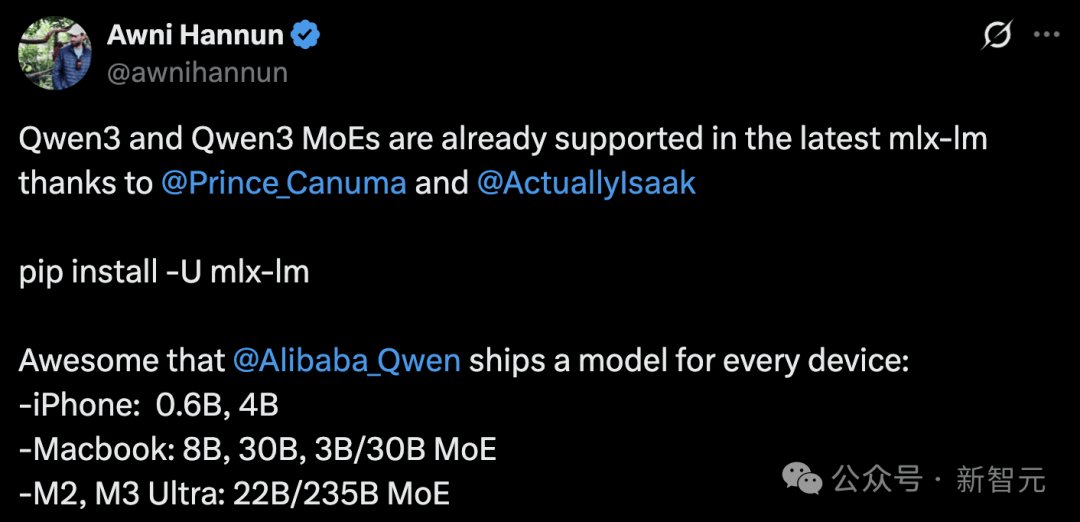
Apple engineer Awni Hannun announced that Qwen3 has received support from the MLX framework.
Moreover, whether on iPhone (0.6B, 4B) or MacBook (8B, 30B, 3B/30B MoE), or consumer devices like M2/M3 Ultra (22B/235B MoE), it can run locally.
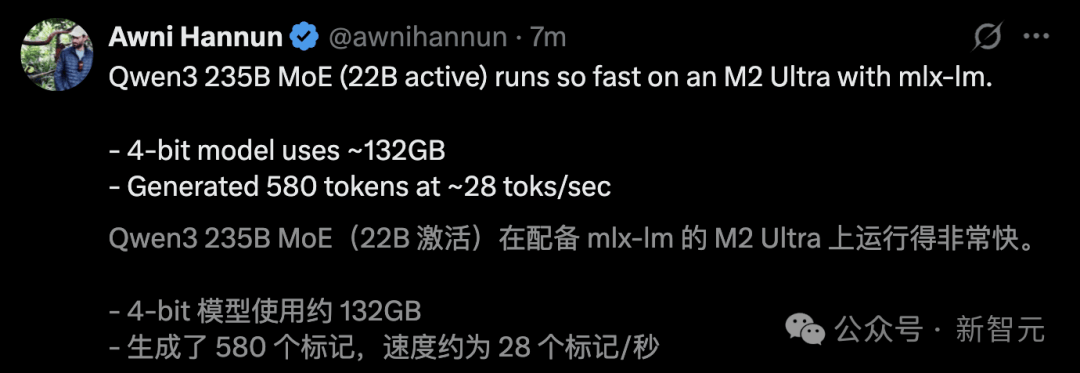
He ran Qwen3 235B MoE on M2 Ultra, achieving a generation speed of up to 28 tokens/s.
Some users found that the Llama model, which is the same size as Qwen3, is simply not on the same level. The former has deeper reasoning, maintains longer context, and can solve more difficult problems.

Others remarked that Qwen3 feels like a DeepSeek moment.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







