AI is not just an algorithmic revolution, but an industrial migration driven by computing power, capital, and geopolitical factors.
Compiled by: Grace
Edited by: Siqi

In the new round of global infrastructure reconstruction brought about by AI, computing power, capital, and energy are intertwining in unprecedented ways.
This article features a recent interview with Dylan Patel, founder and CEO of SemiAnalysis, on Invest Like The Best. Dylan Patel is one of the most well-known analysts in the AI and semiconductor industry, and he and his team have been tracking the semiconductor supply chain and AI infrastructure for a long time, even monitoring data center construction through satellite imagery. He is very familiar with the development process of cutting-edge technologies and has significant industry influence.
In the interview, he outlines a rarely discussed fact: AI is not just an algorithmic revolution, but an industrial migration driven by computing power, capital, and geopolitical factors.
• Computing power—capital—infrastructure is forming a closed loop; computing power is the currency of the AI era;
• Whoever controls data, interfaces, and switching costs holds the discourse power in the AI market;
• Neo clouds and inference service providers bear the greatest demand and credit uncertainty, while stable profits ultimately flow to Nvidia;
• Scaling Law will not exhibit diminishing marginal returns;
• A "larger" model does not equate to a "smarter" one; real progress comes from optimizing model algorithms or architectures and extending model inference times;
• Under the AI Factory paradigm, the key competitive factor for enterprises is to provide stable, scalable intelligent services at the lowest token cost;
• The focus of hardware innovation lies in old industrial sectors such as chip interconnection, optoelectronics, and power equipment, thus the true drivers of hardware innovation remain the giants.
01. The Battle for AI Control: Who is Competing? How to Win?
What is the $300 billion triangle deal?
In the current AI infrastructure race, a unique structural collaboration has formed between OpenAI, Oracle, and Nvidia, referred to in the market as the "Triangle Deal," where the three parties are deeply intertwined in terms of capital flow and production capacity.
• OpenAI purchases cloud services from Oracle;
• Oracle, as the hardware infrastructure provider, is responsible for building and operating large data centers, thus needing to purchase a significant amount of GPU chips from Nvidia, with funds largely flowing back to Nvidia;
• Subsequently, Nvidia returns part of its profits to OpenAI in the form of strategic investments to support OpenAI's AI infrastructure development.
In June 2025, Oracle (ORCL) disclosed its significant cloud service deal with OpenAI for the first time, where OpenAI will purchase approximately $300 billion worth of computing power services from Oracle over the next five years (an average annual expenditure of about $60 billion). Regulatory documents indicate that this agreement will bring Oracle over $30 billion in revenue starting in the 2027 fiscal year, making it one of the largest cloud contracts in history.
In September 2025, Nvidia announced it would invest up to $100 billion in OpenAI, with both parties collaborating to build at least 10 gigawatts of AI data centers for training and running the next generation of models, consuming as much electricity as 8 million American households. Nvidia's stock price rose over 4% that day, with its market value approaching $4.5 trillion.
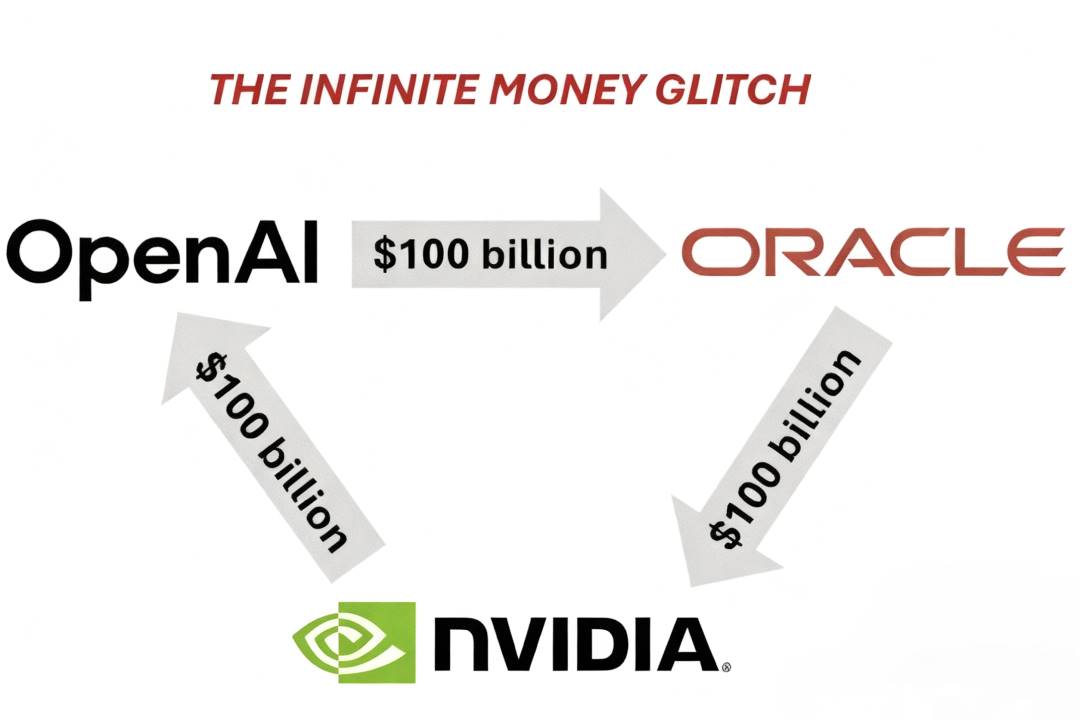
According to Dylan's estimates, the construction cost of a 1GW data center is about $10–15 billion per year, with a typical contract period of 5 years, totaling around $50–75 billion. If OpenAI's goal is to build a 10GW level computing cluster, the total capital requirement will reach several hundred billion dollars.
Taking the Nvidia and OpenAI deal as an example, a 1GW cluster corresponds to about $10 billion in Nvidia equity investment, but the total cost of fully constructing a 1GW level AI data center is about $50 billion, with approximately $35 billion flowing directly to Nvidia, yielding a gross margin of 75%. In other words, Nvidia effectively converts half of its gross profit into equity for OpenAI, achieving a structural concession.
This triangle deal is not only a response to the scarcity of computing power but also represents a new phase of capitalization in the AI industry: in this phase, computing power becomes the new currency, infrastructure becomes the high ground for value distribution, and the speed of technological innovation is continuously amplified by financial structures.
Data, Interfaces, and Switching Costs: The Key to Controlling AI Market Discourse
The competition in the AI industry appears to be a battle of models and platforms, but in essence, it is a reconstruction of power chains. Dylan believes that whoever controls data, interfaces, and switching costs holds the discourse power in the AI market.
For example, with Cursor and Anthropic, on the surface, Anthropic, as the model provider, earns most of the gross profit, but Cursor, as the application provider, controls user and codebase data and can switch freely between multiple models, ultimately retaining bargaining power.
This game also exists between OpenAI and Microsoft. In 2023, Microsoft almost completely controlled OpenAI's computing power and capital cooperation, but by the second half of 2024, to avoid bearing approximately $300 billion in long-term expenses, Microsoft paused some data center construction and abandoned exclusive computing power supply, leading OpenAI to turn to Oracle. OpenAI and Microsoft are currently renegotiating profit distribution (with Microsoft's capped profit at 49%) and intellectual property sharing, with control gradually shifting from Microsoft to a more balanced cooperative relationship.
The same applies at the hardware level; Nvidia cannot expand its control through acquisitions and can only rely on its balance sheet to "underwrite"—consolidating its ecosystem through demand guarantees, repurchase agreements, and even pre-allocating computing power. Dylan refers to this process as "GPU monetization": GPUs have become the universal currency of the entire AI industry, while Nvidia acts like a central bank, controlling circulation through financing and supply rules.
This pre-allocation mechanism has been widely replicated—companies like Oracle and CoreWeave are offering partners "first-year free computing power windows," allowing them to conduct model training, receive inference subsidies, and expand user bases before repaying costs in cash flow over the following four years.
As a result, the AI industry has formed a multi-layered power chain spanning hardware—capital—cloud services—applications. Computing power, capital, and credit circulate along this chain, constituting the financial infrastructure of the AI world.
Neo Clouds: A New Commercial Layer in the AI Industry Chain
The rise of Nebius and CoreWeave essentially indicates that a new commercial layer is forming in the AI industry chain: Neo Clouds sit between the underlying supply of chip manufacturing, cloud computing, and the upper-layer ecosystem of large models and application products, taking on roles in computing power leasing, model hosting, and inference services.
Neo Clouds have two models:
- Short-term Contracts:
By purchasing GPUs and building data centers, they rent out computing power at a high premium. This model has ample cash flow but carries extremely high price risks. For instance, with Nvidia's Blackwell, if amortized over six years, the hourly computing power cost is about $2, while short-term contracts can sell for $3.5 to $4, yielding very high profits. However, when the next generation of chips is released, with performance increasing tenfold while prices only rise threefold, the value of such assets will rapidly decline.
- Long-term Binding:
Locking in customers through multi-year contracts. This model has stable gross margins but heavily relies on the counterparty's credit; if unable to fulfill the contract, the risk will concentrate on middle-layer players:
• Nebius signed a $19 billion long-term contract with Microsoft, ensuring stable cash flow and high profits, with the market even considering this credit level higher than U.S. Treasury bonds;
• CoreWeave initially relied heavily on orders from Microsoft and was an important computing power partner for Microsoft. Later, as Microsoft reduced its procurement scale, CoreWeave turned to establish partnerships with Google and OpenAI, providing these companies with GPU computing resources and data center services. This allowed it to maintain high profits in the short term but also brought new risks, especially with OpenAI's insufficient repayment capacity, raising concerns about the long-term stability of these contracts.
Inference Providers have also found new growth opportunities within the Neo Clouds Business Model. They provide model hosting and efficient inference services primarily targeting companies like Roblox and Shopify. While these companies have the capability to build their own models, the inference deployment process is often very complex, especially in large model and multi-task scenarios. Inference Providers become a key part of the entire system's operation by offering open-source model fine-tuning, stable computing power, and reliable services.
Inference Providers: Third-party platforms or companies that provide model inference services, having already deployed a certain model and allowing users to access this model through APIs or other interfaces, meaning users can pay to use the APIs provided by these service providers.
However, these Inference Providers themselves also operate in a highly uncertain environment. Their clients are often cash-strapped startups or small to medium-sized SaaS developers, with short project cycles and high contract fulfillment risks. Once the funding chain breaks, risks will cascade down. Ultimately, the profits in the industry chain still concentrate on Nvidia: it achieves stable revenue through GPU sales, while being almost unaffected by market fluctuations. All uncertainties and credit risks are borne by Inference Providers.
AI Arms Race
Dylan also believes that AI has become a new strategic battleground, especially in the context of great power competition, where competition is no longer limited to technological dimensions but is an overall confrontation of national economies and systems. Particularly for the United States, AI is the last key point to maintain its global dominance; without this AI wave, the U.S. could lose world hegemony by the end of this century.
Today, the growth momentum of American society is depleting: high debt, slow manufacturing return, and aging infrastructure, while AI is the only accelerator that can put the economy back on a growth path. Therefore, the U.S. must rely on AI to maintain GDP expansion, control debt risks, and sustain institutional order. Currently, the U.S. model is still based on capital markets and innovation-driven growth, relying on open ecosystems and massive investments from the private sector to maintain its leading position through ultra-large-scale computing power construction.
China, on the other hand, has adopted a completely different long-term strategy. The Chinese government often promotes industrial rise through a "loss for market share" approach. Whether in steel, rare earths, solar energy, electric vehicles, or the PCB industry, China has gradually gained global market share through state capital and policy support. This model is now being replicated in the semiconductor and AI fields. The Chinese government has cumulatively invested $40 billion to $500 billion in the semiconductor industry through "five-year plans," "national big funds," and local fiscal policies. The goal of these investments is not to achieve performance leadership but to build a complete and controllable supply chain system, ensuring self-sufficiency from materials to packaging to guarantee industrial security in a geopolitically tense environment.
At the same time, in terms of execution, China demonstrates significant speed advantages and organizational mobilization capabilities. If China decides to build a 2–5GW level data center, it may only take a few years, while the U.S. typically requires two to three times that duration for a project of similar scale.
02. Discussion on AI Technology Roadmap
Scaling Law will not exhibit diminishing marginal returns
Dylan does not believe that Scaling Law will exhibit diminishing marginal returns. In a log-log coordinate system, even without improvements in model architecture, as long as computing power, data volume, and model scale continue to increase, the model's performance will still improve at a certain rate.
Dylan compares this phenomenon to the growth curve of human intelligence: the changes humans undergo from ages 6 to 16 are not continuous additions but rather stage-like leaps. In other words, the enhancement of a model's intelligence is qualitative; although achieving the next stage of capability may require an investment of ten times the computing power, the economic returns generated will be sufficient to support such investment.
However, Scaling Law also implies risks. When model scale and computing power investments surge to the level of hundreds of billions of dollars, if algorithmic innovation stagnates or inference efficiency declines, the return on investment could collapse rapidly. Therefore, Dylan believes that precise betting between massive investments and time windows is essential to become a winner. If the returns from Scaling Laws disappear, the entire industry may face the risk of systemic overbuilding.
Scaling Laws are not only a technical issue but also a capital structure problem. They force companies to choose between "larger models" and "more usable models": overly large models mean high inference costs, difficult latency reduction, and declining user experience, while moderate scaling can balance efficiency and serviceability. This balance has become one of the core challenges in current AI engineering.
How to Balance Inference Latency and Capacity?
Almost all AI engineering problems can be understood as trade-offs along a curve, where inference latency and capacity are the most critical balance points. For example, at the hardware level, GPUs can reduce latency within a certain range, but costs will rise sharply; conversely, pursuing high throughput will sacrifice response speed. Companies must find a balance between user experience and financial pressure.
Dylan believes that if there were a "magic button" that could simultaneously solve the issues of inference latency and capacity, the potential of AI models would be fully unleashed. However, in reality, cost remains the primary constraint; inference speed is already fast enough, but computing power is severely lacking. Even if we could now train a model ten times larger than GPT-5, we would still be unable to provide stable deployment for that model. Therefore, companies like OpenAI need to consider whether to launch a high-speed model that everyone can use or release a stronger but more expensive model. This also means that the development of AI is not only limited by hardware performance but also depends on the kind of user experience humans are willing to accept.
However, the true breakthrough in model performance does not entirely depend on being "larger." Simply changing the model scale can lead to the trap of "over-parameterization": when the model scale continues to expand without a corresponding increase in data volume, the model is merely "memorizing" data rather than truly "understanding" content. True intelligence comes from grokking, which is an insightful understanding, akin to the moment humans transition from rote memorization to genuinely grasping knowledge.
Interactive Environments as a New Direction for RL Development
As mentioned earlier, today's challenge is no longer how to make models larger but how to build more efficient data and learning environments. In the past, humans merely collected and filtered internet data, but there are no tutorials online teaching how to operate Excel using only a keyboard, nor is there authentic training material on data cleaning or business processes. Models cannot acquire these capabilities solely by reading the internet; thus, they need new experiential learning spaces.
Building interactive environments for models is the new direction for RL development. These environments could be virtual e-commerce platforms that teach models to browse, compare, and place orders; they could also involve data cleaning tasks that allow models to repeatedly try and gradually optimize across numerous formats; or they could even be games, math puzzles, or medical cases, where models develop true understanding through continuous trial and error, validation, and feedback. Dylan notes that there are already dozens of startups in the Bay Area focused on creating AI learning environments.
Moreover, in Dylan's view, the current stage of AI development is just "the first ball we've thrown." AI is still like an infant, needing to calibrate its perception through constant attempts and failures. Just as humans forget a lot of useless information during growth and retain only a few key experiences, AI models will generate vast amounts of data during training but retain only a small portion. Therefore, to enable models to truly understand the world, they must be allowed to learn within environments.
Some researchers believe that the key to AGI lies in embodiment, which means enabling models to interact with the physical world. This understanding cannot be gained through videos or texts but must be achieved through action and feedback, thus the importance of RL will continue to rise.
It is worth noting that Dylan believes that in traditional training paradigms, AI learns to "understand the world" through data, while in the post-training era, AI should "create the world" within environments. As mentioned earlier, increasing model scale does not equate to growth in intelligence. True breakthroughs come from optimizing algorithms and architectures, allowing models to learn with less computing power and greater efficiency. Therefore, while pre-training remains the foundation of AI development, post-training will become the primary source of future computing power consumption.
Dylan states that as RL matures, AI will transition from "answering questions" to "taking direct action." In the future, AI may no longer just assist users in decision-making but could directly place orders for them on e-commerce platforms. In fact, humans have already unknowingly outsourced some decision-making to AI, from homepage recommendations on Uber Eats to route planning on Google Maps. There are already signs that this trend is accelerating: over 10% of Etsy's traffic comes directly from GPT, and if Amazon had not blocked GPT, this percentage might be even higher. OpenAI's application team is also advancing shopping agents as a core path to commercialization.
This "execution intelligence" will also give rise to new business models—AI execution commissions. Future platforms may charge fees of 0.1% or 1% from the AI execution process, creating significant profit margins.
The Model's Memory System Does Not Have to Mimic the Human Brain
Given limited computing power, "inference time" becomes another path to enhance model capabilities: without changing the model scale, extending the number of thinking steps and inference depth can lead to significant performance improvements.
Dylan believes that the attention mechanism of the Transformer architecture enables models to have strong backtracking and correlation capabilities within limited contexts, but there are still significant bottlenecks in long contexts and sparse memory scenarios. As the context window continues to expand, the pressure on memory and bandwidth rises sharply, and HBM has become a key resource supporting large model inference. This trend is driving a new round of foundational innovation, and future breakthroughs in model performance will depend on more efficient storage architectures and multi-chip interconnect sharing mechanisms to alleviate the current physical limitations in long context processing.
Now, models are amazing. But what they really suck at is having infinite context….This is a big challenge with reasoning. This is why we had this HBM bullish pitch for a while. You need a lot of memory when you extend the context. Simple thesis.——Dylan Patel
However, Dylan does not believe that a model's memory system must mimic the human brain; external writing spaces, databases, and even document systems can serve as external memory for models. The key is to teach models how to write, extract, and reuse information, thereby establishing long-term semantic associations during task processes.
OpenAI's Deep Research is a practical application of this concept. It allows models to continuously generate intermediate texts over extended periods, compressing and reviewing them to complete complex analysis and creative tasks. Dylan describes this process as "a microscope for artificial reasoning," showcasing a possible future working method for agents, which involves a continuous cycle between long-term memory and short-term computation to achieve genuine "thinking."
Dylan believes that this new framework for reasoning and memory will fundamentally change the structure of computing power demand. Future million-GPU clusters will not only be used to train larger models but also to support these long-thinking agents.
The Giants Are Still the True Drivers of Hardware Innovation
• Semiconductor Manufacturing
Today's semiconductor manufacturing has reached a "space-age level of difficulty," becoming one of the most complex systems in human engineering, yet the underlying software systems remain lagging. Even a manufacturing device worth hundreds of millions of dollars still relies on outdated control systems and inefficient development tools.
Even though Nvidia has taken a leading position in the semiconductor industry, its supply chain still retains many components from the old era. For example, in power systems, the basic working principles of transformers have hardly changed for decades. However, true innovation is now occurring in solid-state transformers: they can gradually convert ultra-high voltage AC into low-voltage DC usable by chips, significantly improving energy utilization efficiency. It is these seemingly traditional industrial links that are becoming new sources of profit and innovation for AI infrastructure.
But Dylan is not optimistic about accelerator companies, which are emerging chip companies trying to compete with Nvidia, AMD, Google TPU, or Amazon Trainium. In his view, this industry is capital-intensive, high-risk, and has limited space for technological innovation. Unless there is a truly breakthrough hardware leap, it is nearly impossible for these new players to shake up the existing landscape.
As the context length of models continues to increase, memory demands surge. Due to limited innovation in the DRAM industry, breakthroughs are more likely to occur at the networking level:
Achieving memory sharing between chips through tight interconnections, such as Nvidia's NVL72 module in the Blackwell architecture, which integrates large-scale network interconnection capabilities into a single system, significantly improving data exchange efficiency;
The optics space remains a key frontier; how to achieve more efficient conversion and transmission between electrical signals and optical signals will directly determine the performance ceiling of the next generation of data centers.
Under extreme performance conditions, Blackwell's ultra-high bandwidth interconnection also brings the system close to physical limits in terms of reliability and heat dissipation: each chip in the same rack can communicate with other chips at a rate of 1.8TB per second.
Dylan believes there is still a lot of room for innovation in the field of chip interconnection, and he is extremely optimistic about the continuous progress of hardware technology. However, it is important to note that structural issues within the industry are hindering efficiency:
One reason for Intel's lag is the lack of a data-sharing culture internally; for example, the lithography team and the etching team often refuse to share experimental data, and this data cannot be uploaded to the cloud (like AWS) for correlation analysis, leading to very low overall learning and iteration efficiency;
Although TSMC has stronger manufacturing capabilities, it also does not allow data to be sent out, and the experimental and analysis processes are very slow.
To break this barrier, a change in corporate culture is needed. For instance, Chen Liwu is promoting this transformation, hoping to enable manufacturing companies to utilize their data more openly, build better simulators, and simulate the real world with higher precision.
• World Model
The core idea of the World Model is to enable AI to simulate the world. This concept applies not only to the software layer but is also expanding to the physical layer. Taking Google's Genie 3 as an example, the model can move freely in a virtual environment, observe, and interact with objects; more advanced models can simulate complex processes such as molecular reactions, fluid dynamics, or flame combustion, learning and reconstructing physical laws in an AI manner.
Companies in this field are also emerging rapidly, with some focusing on robot training and others concentrating on the simulation of chemistry and materials. These companies are transforming AI from merely a language processing system into a computational framework for understanding and simulating reality. As a result, robotics and physical simulation have once again become focal points for recent entrepreneurship and investment. However, Dylan believes that the true drivers of world model and hardware innovation are still the giant companies: TSMC, Nvidia, Amphenol, and others.
But also I think most of the cool innovation is just happening at big companies or already existing companies. ——Dylan Patel
03. AI Computing Power, Talent, and Energy
Computing power is industrial capacity, token is the product unit
The AI Factory concept proposed by Nvidia is the economic cornerstone of the AI industry. Unlike traditional factories that produce physical products, smart factories produce intelligence, which is tokens generated through computing power. Dylan vividly made an analogy: "What an AI Factory outputs is not electricity, but intelligence itself."
AI Factory: Proposed by Marco Iansiti and Karim R. Lakhani in 2020 in "Competing in the Age of AI." It refers to a dedicated computing infrastructure that can cover the entire AI lifecycle, from data acquisition, training, fine-tuning, to large-scale inference, thus transforming data into value. The core product of the AI Factory is intelligence, with output measured by token transmission volume, which drives decision-making, automation, and new AI solutions.
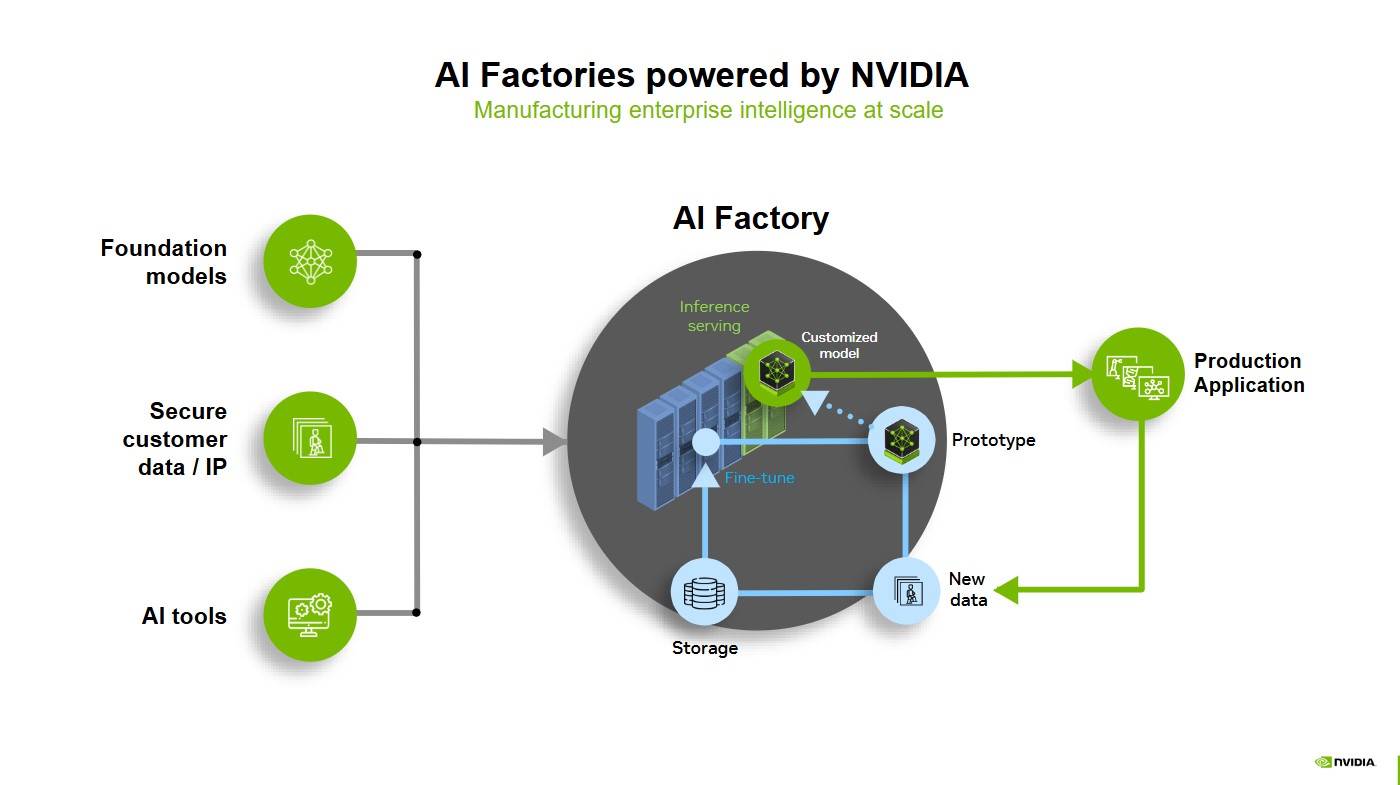
Under the concept of AI Factory, each token reflects the results of computing power, algorithm efficiency, and energy input. The problem AI companies need to solve is no longer to create the strongest model but to achieve optimal token production capacity configuration under the same power. This means making trade-offs between "multiple calls to weaker models" and "few calls to strong models." Factors such as computing power allocation, model scale, user numbers, and inference latency collectively determine the economic efficiency of the AI factory.
In the past two years, algorithm optimization has significantly reduced the service costs of models. For example, the cost of inference at the GPT-3 level has decreased by about 2000 times compared to two years ago, but the drop in costs has not led to an increase in the speed of AI adoption, as computing power remains a scarce resource. Therefore, at the GPT-5 stage, OpenAI chose to maintain a model scale and inference cost similar to GPT-4 to improve inference efficiency under the "thinking mode," allowing more users to actually use it rather than blindly pursuing a larger model.
Dylan believes that computing power is industrial capacity, and tokens are product units. Future competition will not be about who trains the largest model but about who can provide stable, scalable intelligent services at the lowest token cost.
People who can efficiently use GPUs are scarcer than GPUs
Although GPUs are very scarce, what is even scarcer is people who can efficiently use GPUs.
Every ineffective experiment means a significant waste of computing power; therefore, researchers who can improve computing power utilization by 5% can generate long-term compounding effects in both training and inference phases. This efficiency improvement is enough to offset hundreds of millions of dollars in equipment investment costs. In this context, high salaries and equity incentives are not market bubbles but rational returns.
It is important to note that while there is currently a widespread phenomenon of wasting H100 in the industry, this is not a failure but the cost of growth. The real bottleneck in AI research lies in experimental density and feedback cycles, not in a lack of theory. The value of a few top researchers in enhancing overall efficiency far exceeds that of thousands of inefficient attempts.
However, the expansion of talent can also bring side effects. As giant companies engage in global talent acquisition, many research institutions experience organizational inertia and waste of computing power. Dylan bluntly states that too many people can only "talk" but cannot "do," and large-scale talent acquisition often leads to structural mismatches. He even advocates that the U.S. should "reverse recruit" in high-end manufacturing and physical chemistry fields, bringing key processes and experimental knowledge back to the homeland.
The U.S. must regain its power generation capacity
The rise of AI has indeed brought unprecedented energy demands, but in reality, the current electricity consumption of data centers is not enormous. The total electricity consumption of data centers in the U.S. accounts for only 3%–4% of the national total, with about half coming from AI data centers.
According to the U.S. Energy Information Administration (EIA), the electricity consumption in the U.S. for 2024 is projected to be 4,086 billion kilowatt-hours, expected to reach 4,165 billion kilowatt-hours in 2025. Based on an estimated ratio of 1.5%-2%, the electricity consumption of U.S. AI data centers in 2025 is approximately 62.4-83.3 billion kilowatt-hours.
However, the scale of AI data centers is rapidly expanding; for example, OpenAI is building a facility that consumes 2 gigawatts of power, equivalent to the electricity consumption of the entire city of Philadelphia. In the industry, such scales have gradually become the norm, and projects of less than 1 gigawatt are almost ignored. In fact, a 500-megawatt project implies about $25 billion in capital expenditure. This pace and scale of expansion far exceed any previous records in data center construction.
Therefore, the real challenge now is not excessive electricity consumption but how to add power generation capacity: over the past 40 years, after the U.S. energy system shifted to natural gas, new power generation capacity has almost stagnated. Today, restarting power generation projects faces multiple obstacles, such as complex regulations, labor shortages, and supply chain tensions. Moreover, the production cycles of key equipment like gas turbines and transformers are long and have limited capacity, making it significantly more difficult to expand power plants.
Additionally, the high volatility load of model training is also testing the power grid. Instantaneous power changes can disrupt frequency, causing equipment wear. Even if it does not lead to power outages, it can cause nearby household appliances to age prematurely.
Dylan points out that the U.S. must regain its power generation capacity. Currently, gas turbine units and combined cycle units are being rebuilt, and some companies are even generating power using parallel diesel truck engines. The supply chain is also becoming more active; for example, Musk is importing equipment from Poland, GE and Mitsubishi have announced plans to increase gas turbine production, the transformer market is completely sold out, and electricians involved in data center construction have seen their wages nearly double. Dylan believes that if the U.S. had enough electricians, these data centers could be built faster, but the supply chain differences among companies like Google, Amazon, and EdgeConneX lead to very dispersed resources and varying efficiencies.
In terms of regulation, to ensure that computing power facilities do not affect residents' daily electricity use, the U.S. power grid has established "mandatory power reduction" regulations. For example, during tight electricity supply, grid operators in Texas's ERCOT grid and the PJM grid in the northeastern U.S. have the authority to notify large electricity consumers 24-72 hours in advance, requiring them to cut their electricity consumption by half.
Therefore, to maintain AI operations, companies are often forced to activate backup generators, including diesel engines, gas engines, and even hydrogen power generation. But this brings new problems: if these generators run for longer than the legally permitted time (e.g., 8 hours), they will violate emission permits and cross environmental red lines.
Dylan believes that this chaotic yet exciting change is happening. AI is forcing the U.S. to restart power generation construction, reshape supply chains, and make the entire country re-understand the significance of electricity.
04. AI Makes Traditional Software Industry Logic Ineffective
Today, the software field is drastically different from 5-10 years ago, with both software forms and business models undergoing structural transformations. The boom in the SaaS industry has entered a downward cycle: valuation multiples peaked in April 2021 and remained high in October 2022, but growth momentum has clearly slowed since November 2021.
For a long time, SaaS has been regarded as the most well-structured business model in the software industry: product development costs are relatively stable, gross margins are extremely high, and the main expenditure for companies is concentrated on customer acquisition costs (CAC). By cutting sales and management expenses, SaaS companies can release considerable business cash flow. In other words, when a SaaS company's user base reaches a certain critical point, where customer acquisition costs are sufficiently diluted and new users almost directly convert to profit, the company becomes a "Cashflow Machine."
However, this logic holds true only if software development itself is a highly costly endeavor. Companies will choose to rent software services on a subscription basis only when the cost of self-developing is far higher than purchasing ready-made services.
But now, with AI significantly reducing software development costs, the traditional SaaS business model is facing disintegration. For example, in China, software development costs are already low; the salaries of Chinese software engineers are about one-fifth of their American counterparts, yet their capabilities may be twice as strong. This means that the cost of localized development in China is far lower than purchasing or renting SaaS services in the U.S. As a result, many Chinese companies prefer to build their own systems or adopt on-premises solutions rather than subscribing to external SaaS for the long term. This also explains why the penetration rates of SaaS and cloud services in China have consistently been significantly lower than in the U.S.
Today, AI tools are driving down software development costs globally, making self-building increasingly cheaper. As this trend spreads, the original logic of "renting is more cost-effective than buying" for SaaS will gradually become ineffective, just as it has in the Chinese market.
Moreover, the high customer acquisition costs (CAC) in the SaaS industry remain prevalent, while the rise of AI has further increased the cost structure's COGS:
• Any software that integrates AI features will see a significant rise in its service costs (e.g., the computational cost per token);
• At the same time, the market is flooded with competitors who can easily self-build products using AI, leading SaaS companies to become more susceptible to market fragmentation or being siphoned off by customers' internal R&D;
• When user growth becomes difficult to sustain, companies struggle to reach the escape velocity needed to dilute CAC and R&D expenditures;
• Under the constraints of higher COGS, the net profit inflection point for SaaS companies is forced to be delayed, and profitability will gradually deteriorate.
It is important to note that Google still possesses a potential relative advantage. Thanks to Google's self-developed TPU and vertically integrated infrastructure system, Google's marginal service costs per token are significantly lower than its peers, giving it the opportunity to achieve cost advantages in the COGS structure of AI software. However, overall, pure software companies will find it increasingly difficult, while companies that already possess scale, ecosystem, and platform momentum will continue to hold advantages. As content production and generation costs continue to decline, companies that truly control platforms will become the biggest winners. For instance, super platforms like YouTube may usher in a new round of glory.
However, at the level of specific vendors, many software companies will have to confront the same reality: rising COGS, persistently high CAC, and a sharp increase in competitors. As the threshold for "buying is less cost-effective than building" continues to lower, the original competitive advantages of companies are rapidly compressed, making it difficult to restart the growth flywheel. This "software reckoning" is not only a result of the technological shock brought by AI but also a consequence of changes in business structure and cost structure.
05. Quick Comments on AI Players
• OpenAI: A top-notch company
• Anthropic: Dylan is even more optimistic about Anthropic than about OpenAI
Anthropic's revenue growth is noticeably faster because its focus is closely related to the approximately $20 trillion software market. In contrast, OpenAI's layout is more fragmented, simultaneously advancing enterprise software, AI research, consumer applications, and platform commissions. Although these businesses all have potential, in execution, Anthropic is more robust and focused, aligning better with current market demands.
• AMD:
AMD has long competed with Intel and Nvidia, playing the role of a friendly challenger, and this "underdog spirit" is hard not to like. Moreover, AMD is Dylan's first example of a tenfold stock. As someone who has loved assembling computers since childhood, Dylan has always had a fondness for AMD as a "comeback" company.
• xAI: Faces the risk of unsustainable financing
Although Musk can attract funding personally, maintaining a computing power level comparable to top competitors requires a massive capital scale. xAI is building a super data center called "Colossus 2," which, when completed, will become the largest single data center in the world, capable of deploying 300,000 to 500,000 Blackwell GPUs. While such infrastructure is impressive, the company has yet to find a suitable commercialization model. The current only product, Grok, has not achieved ideal monetization.
In Dylan's view, xAI could do a better job of commercializing Grok, such as increasing revenue through personalized content, virtual characters, or subscription interaction models. It could even collaborate with OnlyFans to integrate creators' digital personas into the X ecosystem, forming a true super application.
Overall, while xAI has an excellent team and computing capabilities, it will fall behind in competition unless it makes breakthroughs in business and product areas. Musk's will and funding can support a phase, but without sustainable revenue, even if he is the world's richest person, he cannot single-handedly bear the long-term investment of a 3-gigawatt data center.
• Meta: Holds cards that could dominate everything
Dylan specifically mentions Meta's newly launched smart glasses, believing this marks another revolution in human-computer interaction. From punch cards to command lines, from graphical interfaces to touch screens, human-computer interfaces have continuously evolved, and the next stage will be contactless interaction: users will only need to express their needs to AI, which can execute them directly, such as sending emails or placing orders.
Meta is the only company with a complete system, possessing both hardware (smart glasses) and strong model capabilities, computing power supply capabilities, as well as industry-leading recommendation algorithm systems. The combination of these four factors, along with ample funding, gives Meta the potential to become the dominant player in this generation of human-computer interfaces.
• Google: Was quite pessimistic about Google two years ago, but is now very optimistic
Dylan believes Google has awakened on multiple levels: it has started selling TPUs externally, actively promoting the commercialization of AI models, and showing greater ambition in training and infrastructure investments.
Although there are still some inefficiencies and bureaucratic issues within Google, it has a unique hardware foundation that allows for flexible transformation in the AI era. While it may not match Meta or Apple in hardware experience, Google has a vast ecosystem with Android, YouTube, and search; once human-computer interaction enters a new stage, these assets can be re-integrated. In Dylan's view, while Meta may lead in the consumer market, Google has greater potential in professional and enterprise-level applications.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





