Let me report to everyone that I recently fine-tuned my own model specifically for identifying cryptocurrencies from Twitter posts. The results are quite good.
- The accuracy has surpassed that of the current strongest large models, such as Sonnet 4.5 and GPT-5.
- The analysis speed is 250 times faster than theirs.
- The cost is only 1/100.
So, I would like to introduce this model and summarize some experiences and pitfalls I encountered.
- Model Introduction
Twitter is the most important way for people in the crypto space to obtain the latest news and find potential projects. To perform well in tweet analysis, the most basic first step is to identify the cryptocurrencies mentioned in the tweets.
However, tweet analysis is relatively complex and difficult because:
1) Everyone expresses themselves in various ways, unlike news articles or academic papers which have a more fixed format. 2) The error rate of text and grammar in tweets is significantly higher than in such articles. 3) A large amount of new content is not included in the AI training database.
In this regard, I have done a lot of work. My initial approach was to use existing large models for analysis and I tested almost all models (including different parameters).
Then I found that the accuracy of the existing large models could basically meet my needs, but their high costs ultimately led me to decide to fine-tune my own model. Here are the specific data.
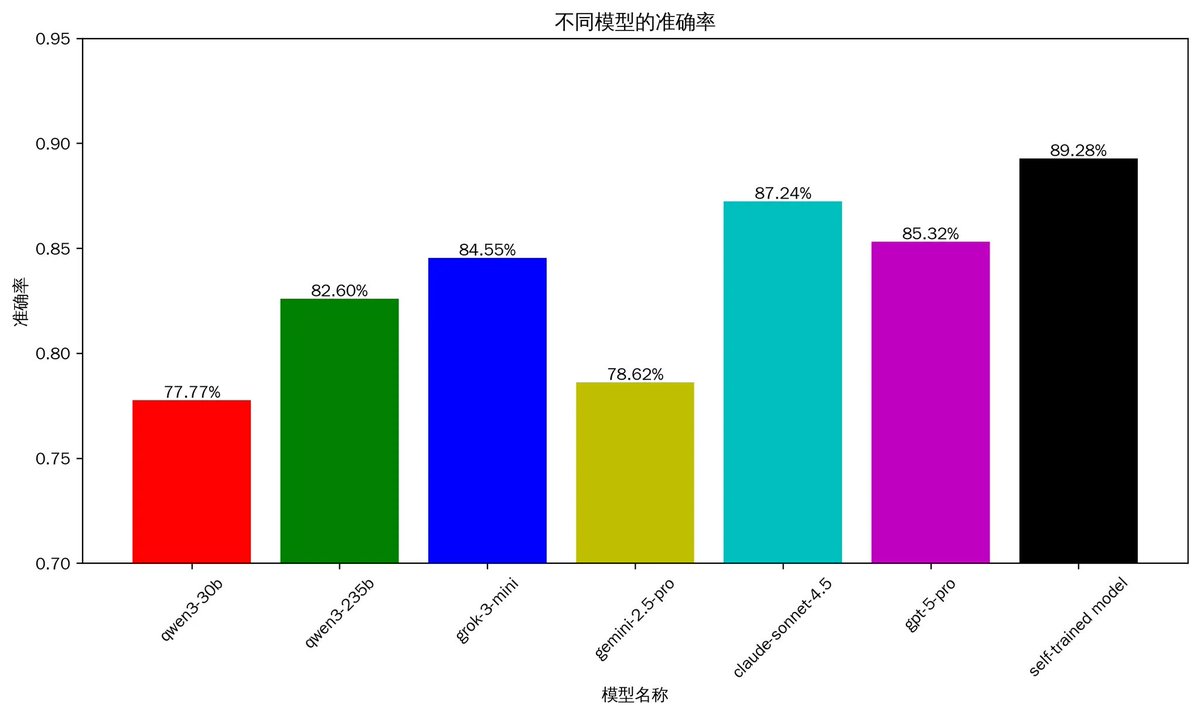
1.1 Accuracy of Tweet Analysis
The above chart shows the accuracy, and you can see that my trained model has reached 89%, surpassing Claude-Sonnet 4.5's 87% and GPT-5's 85%. Surprisingly, Gemini 2.5 Pro, which is also in the top tier, performed poorly in this regard, with only 78%. The domestic open-source Qwen3 235B performed better than Gemini 2.5 Pro.
To clarify, the accuracy mentioned above was executed on the same batch of 1,057 carefully selected tweets, fully encompassing different scenarios, tweets in both Chinese and English, varying article lengths, and discussions of 0 to 6 tokens. Moreover, these tweets were not included in the training data.
Some may think this accuracy is not high. In fact, the real accuracy will definitely be higher than the current data. This is because the current test data consists entirely of crypto-related content, while real tweets contain a lot of non-crypto content. Specifically, the current 1,000+ test tweets are all crypto-related, with an accuracy of around 90%. However, the reality is that out of 3,000 tweets, 1,000 may discuss cryptocurrencies, while 2,000 discuss other topics. Therefore, the real accuracy could reach over 96%.
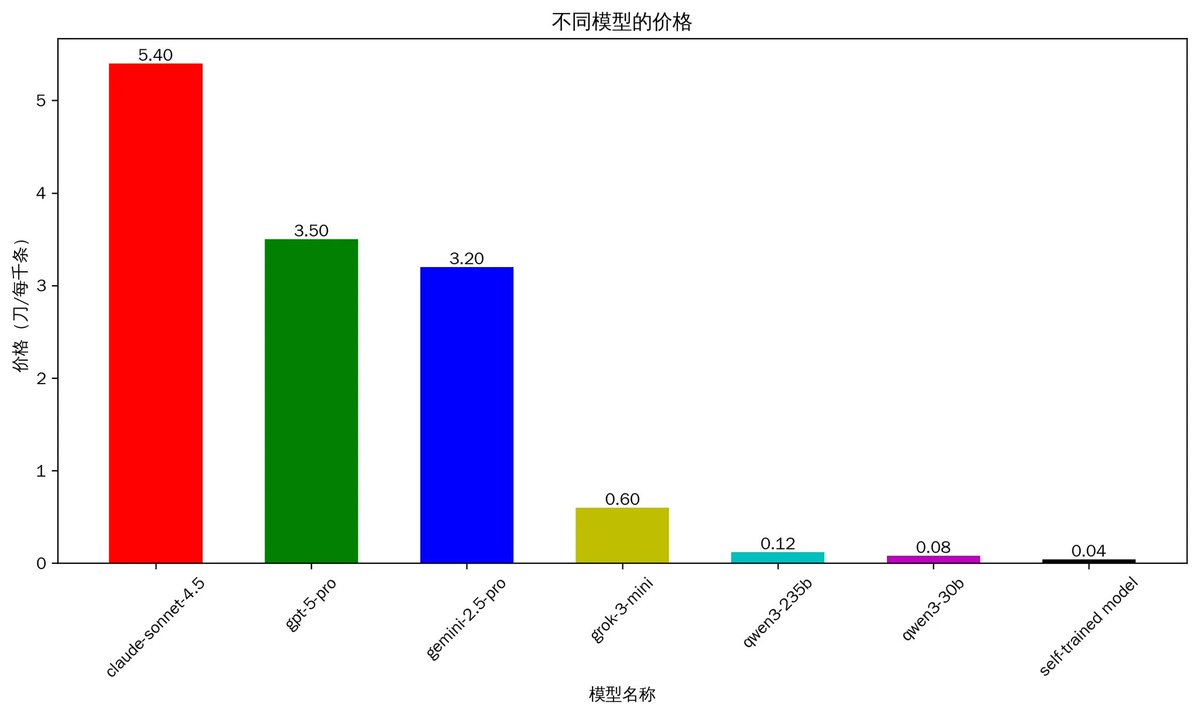
1.2 Cost of Analysis
Cost is another factor to consider. To be honest, the reason that prompted me to fine-tune my own model is that the current large models are too expensive.
From the chart above, you can see that the most expensive, Claude 4.5, costs about $5.4 to analyze 1,000 tweets, which is quite expensive. The other top-tier models, GPT-5 and Gemini 2.5, cost over $3. Qwen3 is relatively cheaper but still costs $0.12. We can do a simple calculation: if an account follows 1,000 people, based on experience, these people tweet about 1,500 times a day. Even using Qwen 235B, it would still cost about $0.18 per day. This is completely acceptable for personal daily use.
However, if a product needs to be developed with 10,000 users, the monthly cost would reach $54,000, which would be a significant expense. In contrast, the model I trained myself has reduced costs by 100 times compared to Sonnet 4.5, while still exceeding their accuracy.
(Note: Due to the significant variation in tweet length, the cost of a single AI analysis also varies greatly, and the prices above are averages.)
- Summary of Experiences and Pitfalls
Next, let’s talk about some insights and feelings I’ve gained during this time, mainly focusing on the pitfalls I encountered.
Experience 1: Compared to large and comprehensive models, using smaller parameters to solve a single task is the right choice.
Currently, the trend in society is towards larger parameters and stronger performance. I initially had the same idea. So my first plan was to call existing large model APIs, and I tested multiple AI models in an attempt to find a cost-effective model that could meet my needs. However, I ultimately found that this was not the optimal solution.
Later, I discovered that some models with very low parameters, although they initially seemed a bit weak when answering simple questions, performed better than the current strongest models after careful fine-tuning for the task of analyzing tweets. The advantages are low cost and fast speed.
Experience 2: High-quality data is crucial.
The core of fine-tuning is high-quality data, which accounted for almost 90% of my time.
In terms of data, the biggest pitfall I encountered came from the standard data processing workflow. Simply put, before fine-tuning, a series of transformations need to be performed on the data. These tasks are standardized, and Hugging Face has a labeled code library that can be used directly. Therefore, when I used the carefully prepared data for the first fine-tuning, the resulting accuracy was only 62%. This result made me question whether the path of training was feasible. After several checks, I found that there were many issues with the data processed using the labeling library.
Another major pitfall was the special handling of token names that are common words. For example, words like "near," "in," and "ip" are common in daily life and need to be distinguished. Otherwise, the fine-tuned model does not just make simple errors with these words, as it learns language.
To be honest, there are still many pitfalls in data processing, and this varies with each person's different data.
Experience 3: Hard work is essential.
Current promotions lead most people to believe that in the AI era, you only need to spend a few minutes to get things done, and the rest will be handled by AI. However, the reality is completely the opposite. There are still many tedious tasks. For example, despite my data having AI annotations and using code processing to improve efficiency, manual checking of the data still took me 7 days.
- Fine-tuning Models with Different Parameters
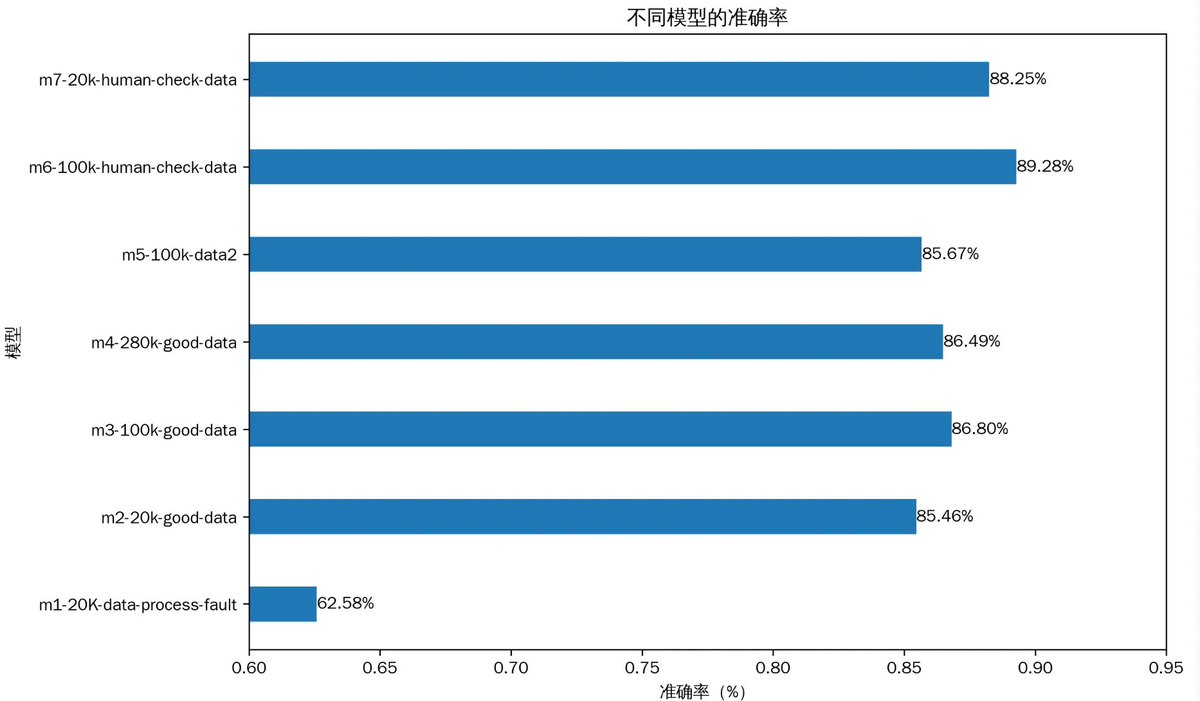
I fine-tuned a total of 8 models, and to test the impact of different parameters on the final results, I selected 7 of them for analysis. Among them, the models are labeled m1 to m7 in the chart above.
m1: As mentioned earlier, this was my first fine-tuned model, but due to the use of labeled data processing methods, the data processing was incorrect. The final accuracy was only about 62%.
m2: After resolving the issues with m1, I trained using the same amount of data. The result suddenly improved to 85%. This result brought it up to the level of the top-tier large models.
m2, m3, m4: These were trained using 20K, 100K, and 280K data volumes, respectively. I found that when increasing from 20K to 100K, the accuracy improved from 85.6% to 86.8%. However, when further increasing to 280K, the accuracy did not improve and instead dropped to 86.4%. This indicates that more data is not always better; too much data can lead to model overfitting.
m6, m7: The data for these models was further validated based on the previous models. The core was manual review; yes, I manually reviewed 100,000 data points, which was the most tedious and labor-intensive task. From the results, the improvement in data quality was the reason for the further increase in accuracy for models m6 and m7. Their accuracy also surpassed the world's strongest model, Sonnet 4.5.
- Conclusion
Overall, although I encountered many pitfalls during this work, the final results left me very satisfied. This has laid a good foundation for large-scale real-time data analysis. Moreover, based on the experiences gained from this work, I may further improve the training data in the future.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。









