跟大家汇报一下,最近我微调了一个自己的模型。用于专门从推特文章中识别加密代币。结果还不错
-准确度已经超过了现在最强的大模型,
比如sonnet 4.5,gpt5
-分析速度是他们的250倍
-成本只有1/100
所以,我来介绍一下这个模型,并总结一些经验我踩过的坑。
1 模型介绍
推特是币圈人获得最新消息、寻找潜力项目的最重要的途径。要想做好推文分析,最最基础的第一步就是识别推文中的加密货币。
但是对推文分析又是比较复杂和困难的,因为
1)每个人的表达方式各式各样,不像新闻稿件、专业论文有比较固定的格式
2)推文中的文字、语法的错误率明显高于此类文章
3)大量新内容,并不在AI训练数据库内
在这方面,我做了大量的工作。我最一开始的方向是使用现有的大模型进行分析,并且测试了几乎所有的模型(包括不同的参数)。
然后我发现现有的大模型的准确度能够基本满足我的需求,但是其高昂的价格,最终让我决定自己微调一个模型。下面是具体的数据
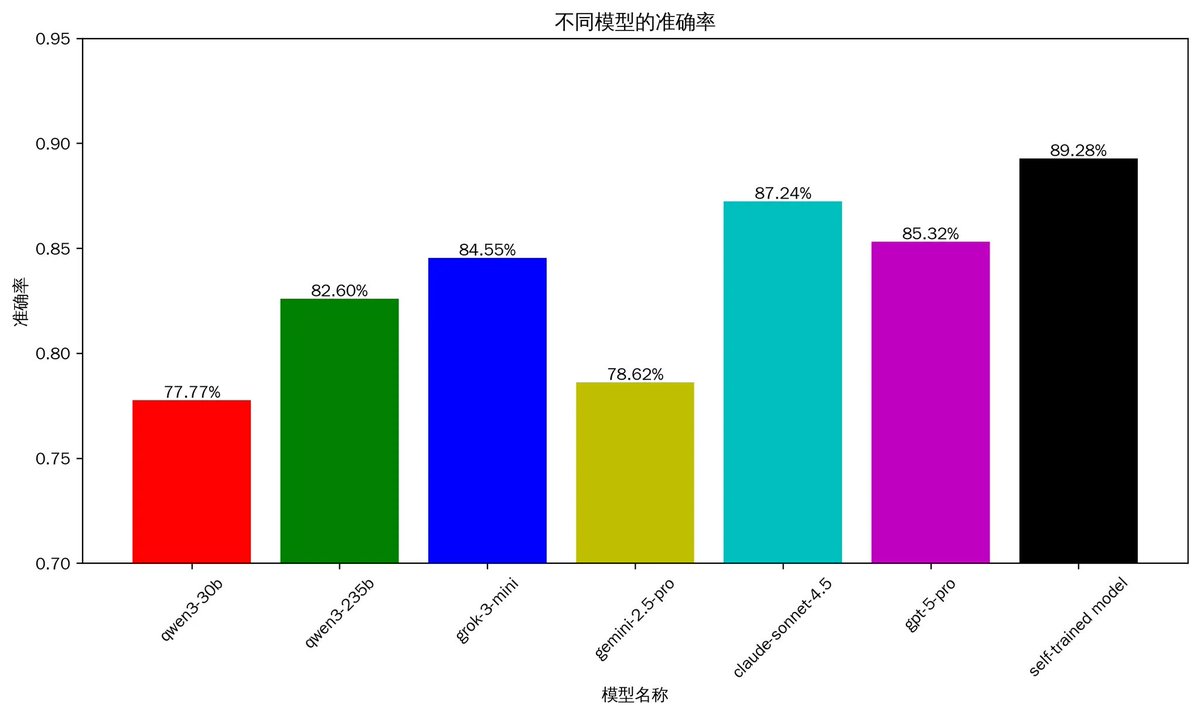
1.1 分析推文的准确率
上图是准确率,可以看到自己训练的模型已经达到了89%,超过了claude-sonnet 4.5的87%,以及gpt-5 的85%。其中比较意外的是,同为第一梯队的gemini 2.5 pro在这方面的表现并不好,只有78%。而国内的开源qwen3 235b的表现要好于gemini 2.5 pro
说明一下,上面的准确率:是同一批1057条精细挑选的推文中执行,充分包含不同的场景推文、中文和英文、文章长中短、讨论代币数量0~6个不等。并且不在训练数据之内。
有人可能认为这个准确率并不算高。其实真实的准确率一定会高于现在的数据。是因为现在测试数据都是币圈的,而真实的推文有大量非币圈的内容。具体来说,现在的1000多条测试推文都一定是币圈的,准确度在90%左右。但是真实的情况是,可能是3000条中有1000条是讨论币,还有2000条讨论其他话题的。所以真实的准确度会达到96%以上。
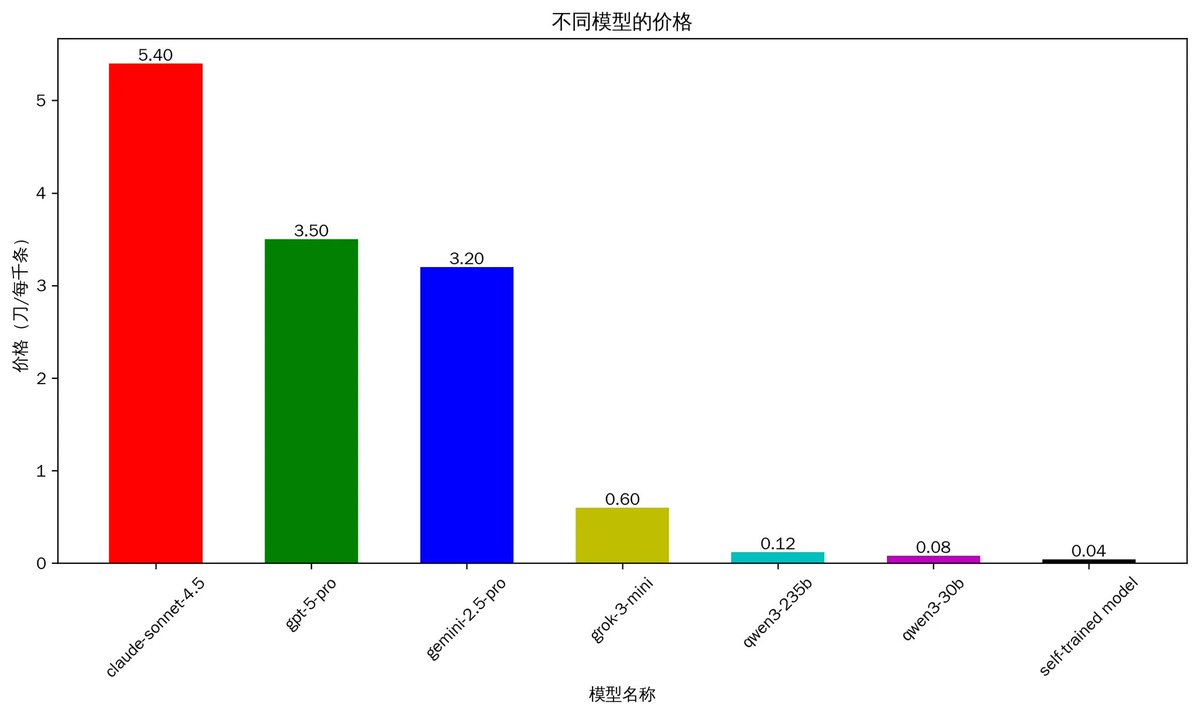
1.2 分析的成本
成本是考虑的另外一个因素。说实话,促使我微调一个自己的模型的原因,就是现在的大模型太贵了。
从上图中可以看到,成本最贵claude4.5, 分析一千条推文大概需要5.4刀,这个价格其实是很贵的。同处于第一梯队的gpt5 和gemini2.5 需要3刀多。而qwen3相对比较便宜,但是也需要0.12刀。我们可以算一个简单的账,如果一个账号关注了1000个人,那么根据经验,这些人一天推文数量大概在1500条。即使使用qwen 235b,一日也需要0.18刀左右。如果只是个人日常使用,完全可以接受。
但是如果需要做一个产品,有1万个用户。那么每月费用将要达到5.4万刀,这将是非常大的一笔开支。而现在自己训练的模型,跟sonnet 4.5相比,成本降低了100倍,但是准确率依然超过他们。
(说明:由于推文的字数差别非常大,所以单次AI分析的成本也是差别巨大,而上面的价格计算的是平均数)
2 一些经验总结和踩过的坑
接下来,聊聊这段时间做的一些心得和感受,当然主要是踩的的坑吧
经验1:比起大而全的大模型,使用小参数解决单一任务才是正确的选择
现在,整个社会的风向都是往更大参数、更强的性能。我一开始也是这样的想法。所以我一开始的方案就是调用现有大模型的api,我测试了多个AI模型,试图找到成本低又能满足需求的大模型。但是最后发现并不是最优解。
然后后来发现,一些参数很低的模型。虽然最初回答一个简单问题,看起来还有点弱智。但是,经过细心的微调,在分析推文的任务上,会好于现在最强的模型。优势是成本低,速度还快。
经验2:优质的数据至关重要。
微调的核心是优质的数据,这方面几乎占据我90%的时间。
在数据方面,我遇到的最大的一个坑是来自标准数据处理流程。简单来说,在进行微调前,需要对数据进行一系列转化。这些工作就是标准化的,Huggging face有标注代码库可以直接使用。于是,当我使用精心准备的数据,进行微调的第一次微调,出来的结果准确率只有62%。这样的结果让我一度质疑自己训练这条路是否走得通。几经排查才发现,使用标注库处理出来的数据有很多的问题。
另外一个大坑,就是代币名称是常见词的特殊处理。比如说near、in、ip等这些都是日常中常见的单词,需要进行区分处理。否则,微调后的模型并不只是对这些词错误那么简单。因为模的是对语言的学习。
说实话,数据处理中大大小小的坑还是很多,这还跟每个人不同的数据有关。
经验3:苦活累活是必不可少
现在的宣传导致大部分人都以为,在AI时代只需要花几分钟动动手,剩下AI都会做完。但是实际情况是完全相反的。依然有不少的苦活累活,比如尽管我的数据有AI的标注,以及使用代码处理,提高效率。但是数据的人工检查,依然花费了我7天的时间。
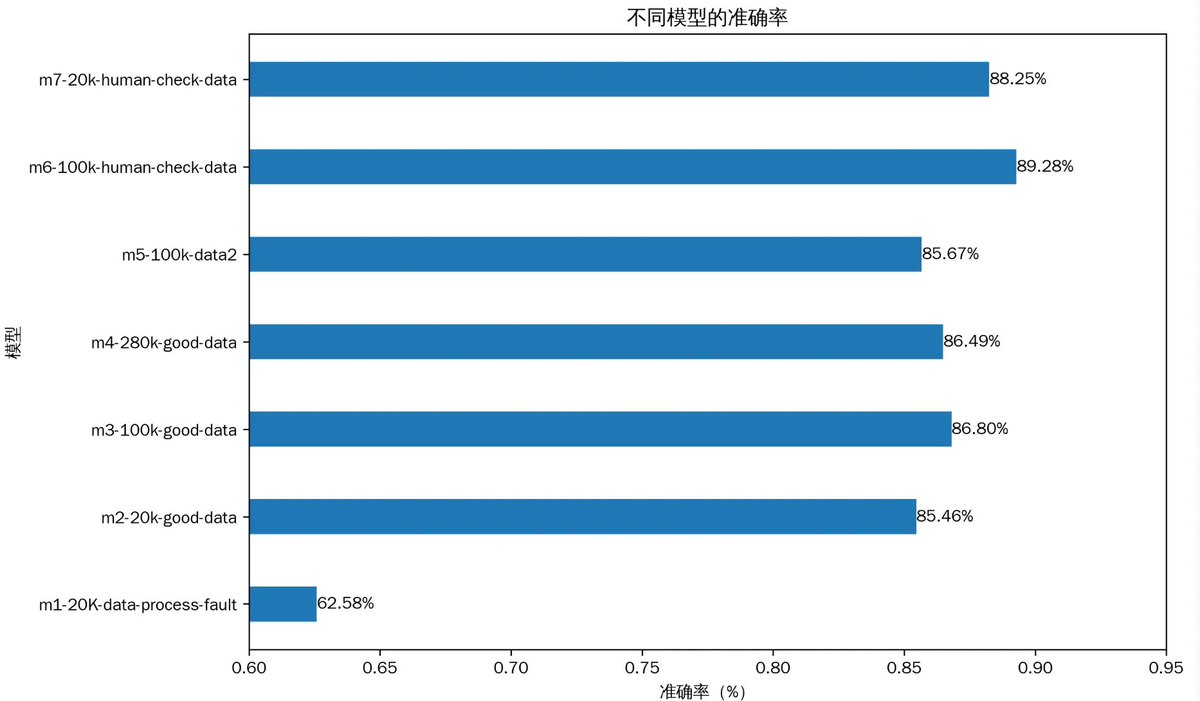
3 使用不同参数的微调模型
我前后一共微调了8个模型,为了测试不同的参数对最后结果的影响,我选取了其中的7个来分析。其中上图中,m1~m7
m1:在前文中介绍过,是我第一个微调的模型,但是由于使用标注的数据处理方式,导致数据处理错误。最终准确率只有62%左右。
m2:是在解决了M1的问题后,使用同样的数据量进行训练的。然后结果一下子就提升到了85%。这个结果是一下子提升到第一梯队大模型的水平。
m2、m3、m4 :分别使用20K、100K、280K的数据量进行训练,发现当从20K的数据,增加到100K的时候,准确率从85.6%提高到了86.8%。但是继续增加到280K的时候,准确率并没有提高反而下降到86.4%。这说明了数据量并不是越多越好,太多的数据会导致模型训练过拟合。
m6、m7:的数据是在前面的基础上面,做进一步数据校验。核心是人工审核,是的,10万条数据,我进行了人工审核,这就是最苦最累的活。从结果来看,数据质量的提高是m6、m7模型的准确率进一步提高的原因。他们的准确度也超过了世界最强的模型sonnet4.5。
4 总结
整体而言,这次工作虽然踩了很多坑,最后的结果还是让我非常的满意。这也为大批量实时分析数据打下了良好的基础。并且,根据这次工作掌握的经验,接下来可能对训练的数据做进一步的提高。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。









