

Author: danny
Open Binance spot and perpetual, the order books are almost identical. But at the moment of "selling," behind it are two fundamentally different state machines. Why does perp need to maintain two sets of prices? Why must an Iron Condor be executed simultaneously with four legs? Why are Polymarket's fees the highest when p=0.5? Why do Uniswap LPs always underperform holding? These questions superficially ask about mechanisms; at their essence, they all ask the same thing——the matching engine is never an independent engineering module; it is shaped by the assets it serves.
The differences between the five forms—spot, perpetual, options, Polymarket, and AMM—are much deeper than their similarities. This article will dissect them to see what forces cause "matching" to diverge into almost unrelated engineering entities.
1. Matching is not a standard component
If you have only seen the implementation of matching in spot trading, you might think that the "matching engine" is a mature, converged, and technically simple thing——a sorted order book, a price-time priority matching loop, plus a one-time settlement path, end of the story.
That would be a serious mistake...
When you pull your perspective from Coinbase's BTC/USDT to Binance's BTCUSDT perpetual contract, then to Deribit's BTC-26DEC25-50000-C, and finally land on a market event on Polymarket, you will find that the matching engines behind these four markets are structurally almost four different machines. They share certain algorithmic similarities——all have buyers, sellers, prices, and quantities——but when you dive into state machine, risk control coupling, transaction boundaries, and trust assumptions, the differences are so significant that the term "matching engine" itself seems overly abstract.
What this article aims to do is to break down these four typical forms and clarify what forces allow the same underlying concept to differentiate into different engineering entities under different subjects.
2. Spot Matching: The most basic form
Spot matching is a standard model; nearly all textbooks and open-source projects (LMAX Disruptor, simplified version of CME Globex, various open-source matching engines) start here.
The core data structure usually consists of two price trees (bid side, ask side), with each price node linked to a FIFO queue. The matching loop is straightforward: when a taker arrives, it starts scanning from the opposing side's best price level, consuming the maker queue in time order until the taker quantity is exhausted or the price exceeds the limit.
Several key points about core features are worth highlighting:
First, the assets are homogeneous and separable. The buyer holds the quote asset (USDT), and the seller holds the base asset (BTC); the essence of matching is an asset swap. The operations on the ledger consist of a pair of balances linked in transactions, and settlement and matching are completed within the same transaction. The matching engine requires almost no external dependencies——matching equals settlement, with no downstream link.
Second, risk is instantly cleared. The moment a spot transaction is completed, all position relationships disappear; there is no continuity of the "position" concept at the matching level. The engine does not need to worry whether you will be liquidated due to price fluctuations in the next second because there is fundamentally no "position" to speak of.
Third, order types are relatively convergent. Limit, Market, IOC, FOK, Post-only, Stop——these are all variants of order lifecycle management.

Consider a specific scenario. BTC/USDT has sell one at 50,001 × 1.5 BTC (maker A placed the order at 09:30:00.100), sell two at 50,002 × 3.0 BTC (maker B placed 1.0 at 09:30:00.200, maker C placed 2.0 at 09:30:00.300). A market order of 4.0 BTC arrives. The matching loop: first consumes A's entire 1.5 @ 50,001, then moves to the next level in FIFO order——B before C, consuming B's entire 1.0 @ 50,002 and then part of C's 1.5 (C has 0.5 left on the book). The taker's account decreases by 200,006.5 USDT and increases by 4.0 BTC, with corresponding reverse updates for the three maker accounts. This series of operations is completed within a single database transaction; matching equals settlement. Notably, B's precedence over C is not due to price (same level), but due to the order of placement——this is the actual embodiment of price-time priority.
The engineering challenges of spot matching are not in the logic but in performance: how to maintain microsecond-level latency under millions of TPS, how to handle cache locality for cold and hot paths, and how to achieve deterministic replay. But these are optimization problems, not mechanism problems.
3. Perpetual Contract Matching: The invasion of the risk control engine
If you place a screenshot of the Binance perpetual contract order book next to the spot order book, there might be no noticeable difference at first glance. However, the underlying structure is another landscape altogether.
The key change is that the matching engine is not the endpoint of settlement; it is merely an event source. (aka a domino)
Each completion of perp matching triggers a complex downstream link: mark price updates, position updates, margin recalculations, unrealized profit and loss refreshes, and possible liquidations. The matching engine and risk engine in perp are deeply coupled, and the way they are coupled determines the character of the entire system.
The dual-price system is the first unique structure of perp. Matching is still driven by the "last traded price," but maintaining margins, liquidation triggers, and UPnL calculations utilize the "mark price," which is synthesized from multiple spot markets' indices plus funding adjustments. This is a design against manipulation: if the matching price and mark price are identical, an attacker can use a small amount of capital to push the order book to an extreme price, instantly triggering the liquidation of all opposing positions. The dual-track system eliminates this attack surface.
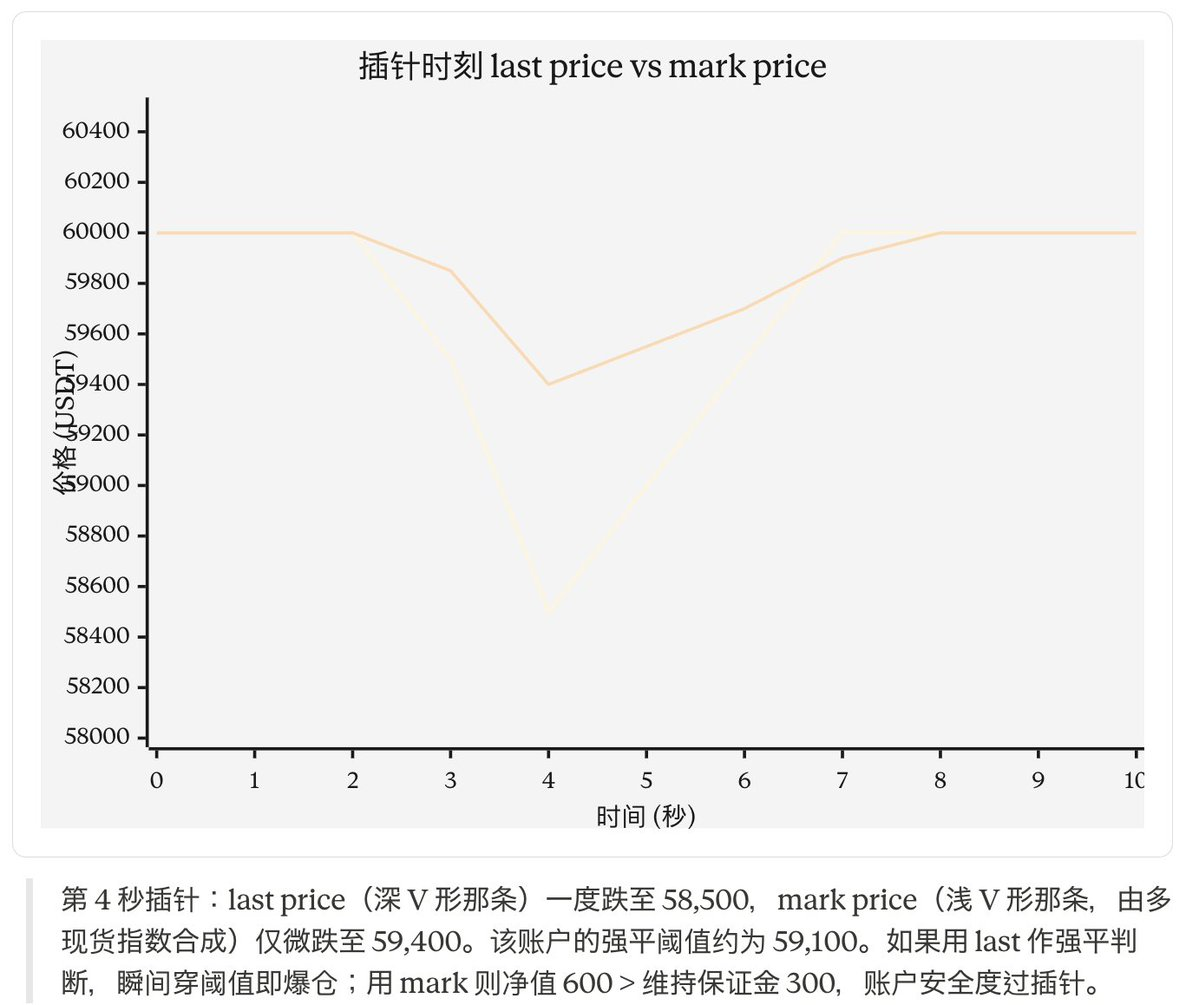
Consider a specific scenario to illustrate the role of the dual price. A trader holds 50x long 1 BTC, enters at 60,000, with initial margin of 1,200 USDT and maintenance margin of 300 USDT. At some moment, the order book is pierced by a large market order, pushing the last price to 58,500——according to last price, the unrealized loss is 1,500 USDT, already a liquidation. However, at the same moment, the mark price (weighted multiple spot index + funding adjustment) = 59,400; according to mark price, the unrealized loss is 600 USDT, with net equity of 600 > maintenance margin of 300, not triggering liquidation. Seconds later, the last price returns to 59,400; this trader is not liquidated by the spike. If matching and liquidation share the last price, an attacker could use a small amount of capital at a thin moment in the order book to pull the price to an extreme position, thereby triggering a chain liquidation of opposing positions and then buying back at a lower price——this was a frequent occurrence on BitMEX in its early days. The dual-track system is not "for precision," but "to avoid being attacked."
Pre-trade risk control is another critical insertion point. In spot, when a taker arrives, it directly matches; in perp, a taker must first pass a margin check——can your available margin cover the position change brought about by this transaction? If it's in cross-margin mode, this check also needs to consider all positions you have within your account for mutual hedging. This check must be completed synchronously within the matching loop, or else there could be a state inconsistency of "realizing insufficient margin after transaction."
The special matching channel for liquidation is the most interesting part of the perp engine. When the account margin rate falls below the maintenance line, the liquidation engine takes over——it will send IOC orders to the order book at the account's bankruptcy price (or some protective price), attempting to close out the position. What if the order book is too thin and can't absorb this liquidation order? Here are a few engineering choices: one is to plug into an insurance fund for coverage, the other triggers ADL (automatic deleveraging), where the system forcibly reduces the positions of profitable counterparties.
ADL is essentially "the last link of matching": when the order book and insurance fund both fail, the system skips the order book, directly settling between the two accounts. This is a design that expands the concept of "matching" from "voluntary matching" to "involuntary matching"——it no longer belongs to traditional matching but must exist; otherwise, the system would go bankrupt under extreme market conditions.
Self-trading prevention (STP) complexity is also unique to perp. In spot, self-trading prevention mainly prevents wash trading; in perp, the same account can hold both long and short (hedge mode), thus the semantics of STP need segmentation: is it by sub-account, by user ID, or by master account? Different exchanges choose differently.
In summary: the "difficulty" of perp matching is not in the order book itself but in the entire set of state machines bound to the risk engine behind the order book. Designers must clearly think about which checks are on the main path of matching (synchronous) and which can be asynchronous; what execution model is used for liquidation; how the insurance fund is accrued; and how the priority queue for ADL triggers is sorted (usually sorted by "profit percentage × leverage," letting the most profitable and highly leveraged be the first to be reduced).
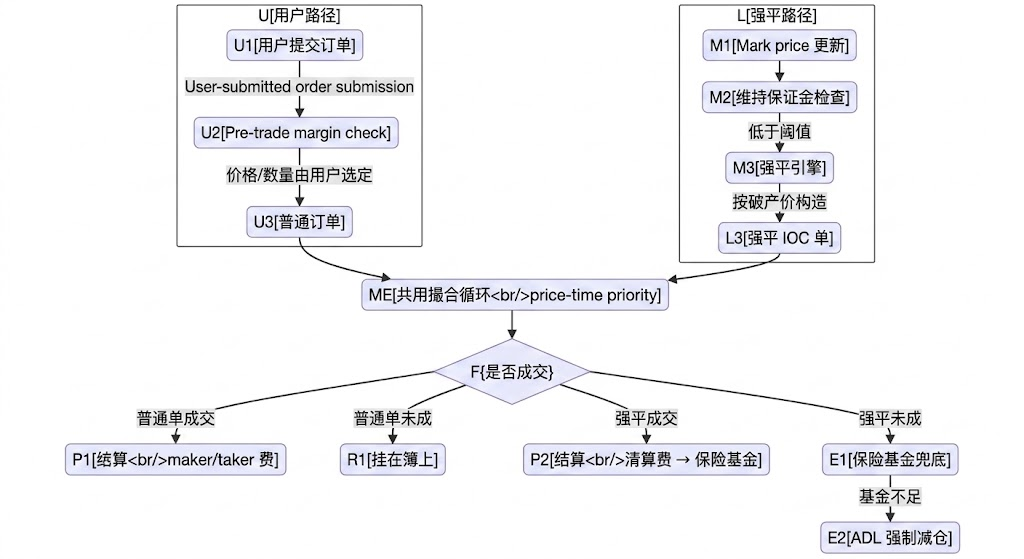
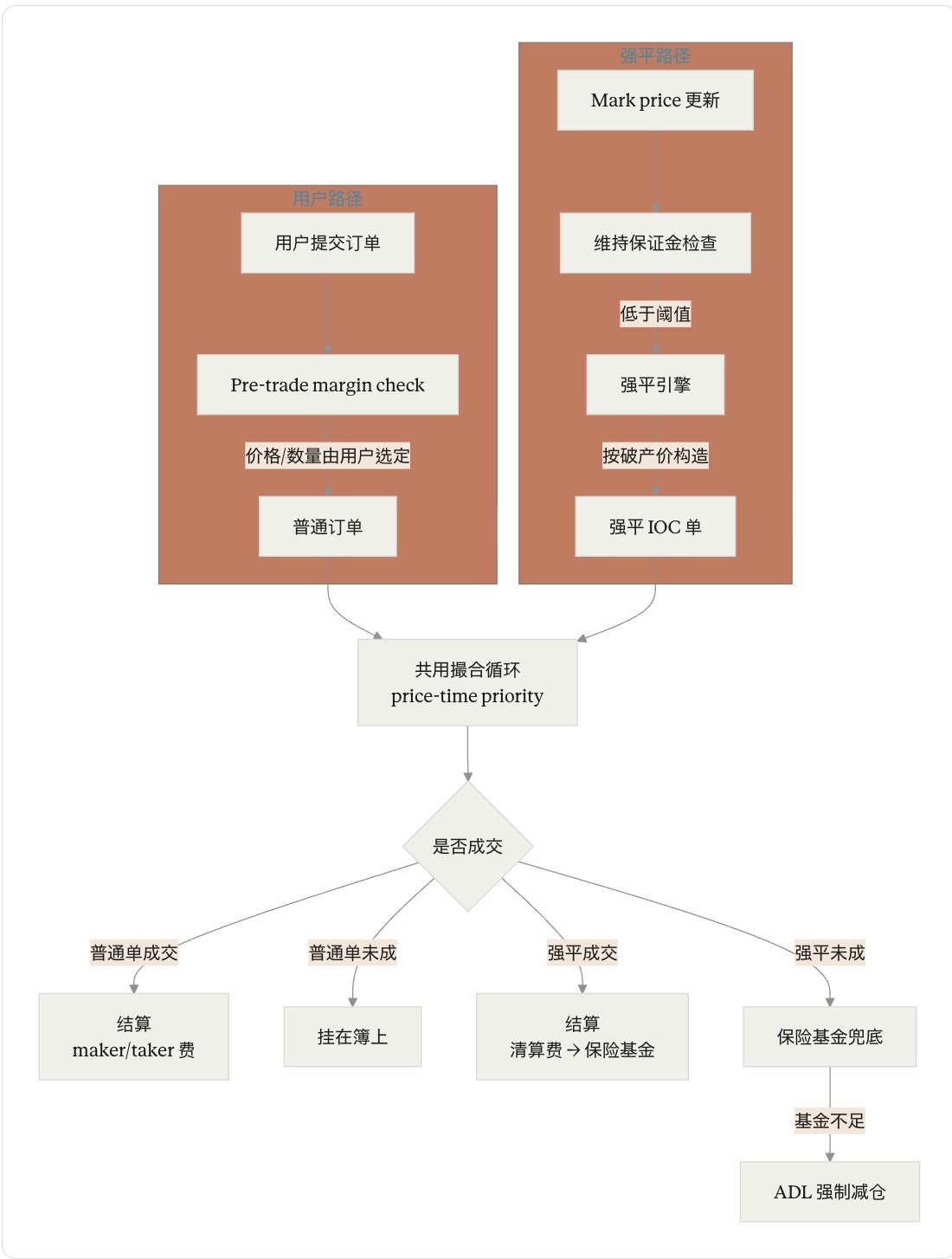
4. The dual path of perpetual matching: a layered decision-making, structuring, and execution
Perp matching has another layer worth discussing specifically: the liquidation path merges with ordinary orders during the matching stage but follows a completely different logic before and after the merge. Understanding this layering is crucial for designing or debugging a perp engine——otherwise, it will repeatedly confuse the boundaries between "matching" and "settlement."
Breaking down liquidation into three layers:
The first layer is trigger determination. Using mark price——the goal is to prevent the decision of "should it be liquidated" from being influenced by momentary manipulations of the order book. This layer is completely detached from market depth; it is an independent risk control judgment.
The second layer is order construction. After the liquidation engine determines liquidation, it constructs an IOC order to submit to the order book. This order structurally differs from regular user orders in several dimensions: the price is not chosen by the user but is set by the engine based on the bankruptcy price as a limit; the type is always IOC and not allowed to rest in the book; fees follow the liquidation rate (0.5–1.5%) rather than taker rates, directing to the insurance fund; the order submission authority belongs to the system rather than the account——accounts being liquidated may even first have all their existing orders forcibly withdrawn from the book (to avoid self-trading contamination in liquidation); the fallback for failure is different——user IOC orders vanish if they cannot be filled, while liquidation IOC orders triggering the insurance fund → ADL cascade.
The third layer is matching execution. Once in the order book, liquidation IOC and regular IOC follow precisely the same price-time priority rules to consume counterparty liquidity. This layer is symmetric; the matching engine should not "treat" liquidation orders with special prioritization——the matching loop should not have such if-else, as it would undermine deterministic replay.
Thus, an accurate description is: the matching loop itself is not separated into two sets, but the sources, structures, billing, and failure paths of the orders are divided into two sets. From the perspective of the main path of matching, liquidation and regular orders are equal; in terms of the entire transaction panorama, they traverse two parallel paths that merge only at the matching stage.
Another noteworthy point here——the mark price determines "at what price should liquidation occur" (trigger condition), but the last price (market depth) determines "at what price can liquidation actually occur." When the order book is thin and the depth is exhausted, the actual settlement price of the liquidation IOC can significantly deviate from the bankruptcy price; this gap becomes the insurance fund's "profit and loss source." The insurance fund essentially absorbs the deviation between the "theoretical liquidation price provided by the mark" and "the actual settlement price executed in the market." If both were always the same, the insurance fund wouldn't need to exist at all.
More aggressive designs (Hyperliquid's HLP, early dYdX backstop liquidator network) simply add a layer of "liquidation market" in front of the order book——allowing specialized market makers to preemptively take on entire positions at agreed discounts, bypassing the slow order book route. This fundamentally separates "liquidation execution" from market matching, providing its own matching channel for the liquidation path. This is another way of answering the dual path problem: some exchanges believe that merging two paths into the same order book is a compromise; they simply let them operate through different matching channels.
Returning to the core of perp matching complexity: the main matching loop can remain simple, but the surrounding state machines——risk control, liquidation, insurance fund, ADL, possibly a backstop liquidator network——constitute a much more complex system than the order book itself. The visual illusion that "the order book looks the same as spot" actually hides two independent entry pipelines and four different exit paths. This is the true shape of the "difficulty" of perp matching. (It is rumored that some exchanges have even created a b book.)

5. Options Matching: Gridding and Market Maker Dominance
Options are the only category among these four types where "the underlying itself has explosive quantities." A BTC spot market has only one order book; a BTC perpetual has only one; but BTC options——for example, Deribit——have hundreds of active contracts at any given time, generated by the combination of strike × expiry × call/put across three dimensions. Each contract needs an independent order book.
This introduces the first fundamental issue: liquidity is sparse. Deep in-the-money or out-of-the-money contracts may only have a few trades in a day, and the order book often appears empty or features only two quotes from market makers. This sparsity renders a pure LOB model nearly unusable——a typical buyer placing a limit order might wait days to get filled.
The industry's solution is to mix three modes:
LOB is used for the contracts with the deepest liquidity, primarily ATM options and near-month contracts. This part does not differ fundamentally from spot logic.
RFQ (Request For Quote) is used for contracts with sparse liquidity. Traders issue quote requests, multiple market makers respond, and traders select the best one. This process operates outside of LOB, matching "inquiry orders vs. multiple quote responses," which is essentially a reverse auction.
Block trade is used for very large orders. Two counterparties negotiate a price off-market, report the trade for registration and settlement at the exchange; the order book does not participate in matching but only in registration.
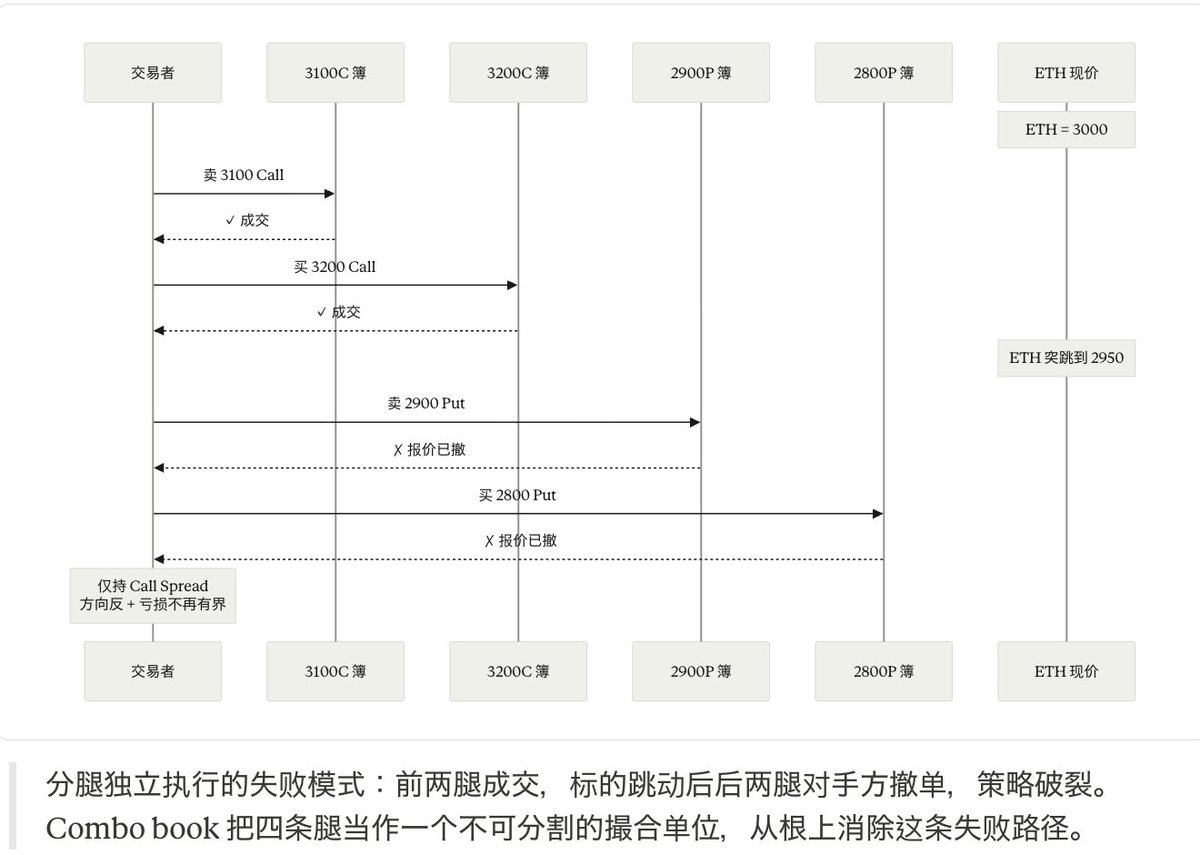
Multi-leg synchronized matching is another core requirement of options matching. A common strategy——like an iron condor——needs to buy and sell four different options contracts simultaneously. If the four legs were independently matched across four order books, the result might be that two legs get filled while the other two do not, exposing the trader to unintended risk. Therefore, the options matching engine must support combo book or multi-leg atomic execution: all four legs must either be filled entirely or not at all, handled as a whole.
Deribit's approach is considered the current industry reference standard: it has a separate combo order book, where combo orders can be placed independently or implied matched with single-leg order books——the system automatically synthesizes combo prices from single-leg liquidity and vice versa. This is an exquisitely designed system, but it also means the main matching path must maintain the state synchronization of a "virtual order book."
To illustrate why multi-leg synchronized matching is not optional, consider a specific scenario. ETH's current price is 3,000, and the trader predicts a future 7-day range between [2,900, 3,100], constructing an Iron Condor: sell 3,100 Call, buy 3,200 Call, sell 2,900 Put, buy 2,800 Put. The net income of four legs is the maximum profit of the combination, and the maximum loss is strictly capped due to protective legs——this is the prerequisite for the strategy's validity. If the four orders were submitted independently to four order books for matching, the most common failure scenario would be: the first two legs (call spread part) are filled, ETH jumps to 2,950 in milliseconds, and the second two legs (put spread part) face invalid counterparty quotes; market makers withdraw or significantly adjust, C and D do not get filled. As a result, the trader holds an uncovered call spread——the directional exposure is entirely reversed, turning the originally "beneficial in fluctuations" strategy into "damaged in bearish," and the maximum loss is no longer capped. The combo book bundles the four legs into an entirety: they either all fill or none do; implied matching further allows the single-leg order books' liquidity to be dynamically synthesized into combo pricing, and conversely, liquidity from the combo book will flow back to single legs, with two layers of liquidity complementing each other.
Market makers' pricing algorithms mainly use IV (Implied Volatility) instead of prices (which is specific to options). Market makers do not post "50000 strike call $1500"; they post "buy at 65 vol, sell at 67 vol," and the system calculates the actual quote using BSM (or more complex models) based on the current underlying price each time a quote goes live. This means market makers' quotes dynamically follow the underlying, and the order book will automatically adjust when the underlying price changes——transforming "posting" in options into a continuous function rather than a discrete event.
Greek-based composite margins make risk control different as well. In perp, each position independently calculates its margin; in options, market makers may simultaneously hold hundreds of contracts, and calculating margins for each individual contract would reduce capital efficiency to the point of being unviable. Therefore, options exchanges typically use composite margin based on the Greeks (delta, gamma, vega, theta), treating the entire portfolio as a net exposure, calculating margins based on net Greeks. This, in turn, affects matching——the "margin cost" of a transaction depends on whether it hedges existing positions.
6. Polymarket Matching: A Mixed On-chain and Off-chain Architecture
Before delving deeper, let’s answer a possible doubt: why discuss Polymarket separately, and not AMM? Why not merge it into a generalized "DEX matching" category?
Because Polymarket's uniqueness does not lie solely in the "on-chain" label. What truly makes Polymarket distinctive is the combination of three mechanisms: [0, 1] price capping + CTF complementary minting + UMA outcome determination (similar to mark price). Together, these three create a state machine form that is different from spot, perp, options, and other DEX——a bounded discrete price space, liquidity creation from nothing, and an endpoint in the lifecycle.
Let’s unfold this based on these three mechanisms and their underlying trust assumptions.
Polymarket is a (first?) prediction market built on Polygon; all positions are ERC-1155 tokens issued by Gnosis's Conditional Token Framework (CTF). A market——for instance, a binary prediction for a presidential election——issues two types of tokens: YES token and NO token, where at the end of the market, one token is worth $1, and the other worth $0.
The complementary minting mechanism is at the core of CTF. Anyone can deposit 1 USDC to receive 1 YES + 1 NO. Anyone can also destroy 1 YES + 1 NO to redeem 1 USDC. The existence of this mechanism allows market makers to "create liquidity from nothing"——market makers do not need to hold tokens in advance to sell; they can mint immediately and then sell. From the perspective of the matching engine, this is equivalent to market makers having infinite initial inventory, but the cost constraint is held within margins——this is a key difference between Polymarket and traditional CLOB.
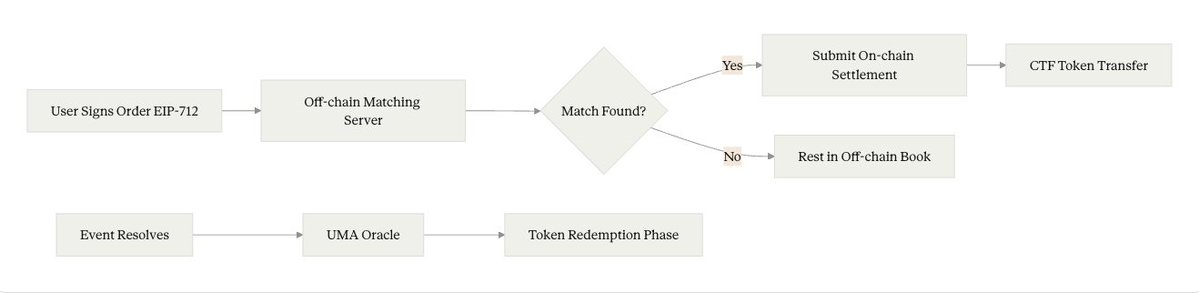
Off-chain matching + on-chain settlement is the overall architecture of Polymarket. The specific process: users sign a limit order using EIP-712, which is sent to Polymarket's centralized matching server; the server maintains a traditional LOB; when two orders match, the server packages these two signatures into a single on-chain transaction and calls the exchange contract to complete settlement. Thus, the matching itself is off-chain (in milliseconds), while the settlement is on-chain (in seconds).
This architecture has a special characteristic at the trust level: the matching server cannot forge transactions because it does not possess users' private keys; but it can scrutinize transactions——rejecting certain orders from matching.
Gas economics shape the settlement path rather than user behavior. A common misunderstanding is attributing Polymarket's gas cost to users——in reality, gas is paid by the relayer (Polymarket's operator). Users sign orders using EIP-712, and the relayer, after matching, submits batches of completed transactions on-chain, with gas covered by Polymarket, then recouped through trading fees. This means that for users, placing and withdrawing orders are free——withdrawals may not even go on-chain, merely notifying the matching server to remove the order, logically akin to withdrawal in CEX.
However, this does not mean that gas is without constraints; the constraints are merely transferred to the relayer's side: the on-chain settlement cost of each completed transaction is borne by Polymarket, and the relayer's gas budget + Polygon's throughput limit jointly determine the system's maximum transaction frequency. Market makers experience not "expensive orders" during extreme congestion, but rather settlement delays and throughput bottlenecks——which conveys the congestion propagation path that is entirely different from CEX.
The true shaping imposed on the matching engine by this architecture is: it must enable the relayer to batch settle multiple transactions (amortize gas) while keeping every transaction independently verifiable within the settlement contract (to prevent relayer tampering or embezzlement). Thus, Polymarket's exchange contract is designed to accept "multiple signed orders + one batch submission" structure. Gas has not turned Polymarket into a "low-frequency market," but rather made its matching-settlement coupling method different from both CEX and purely on-chain DEX——the matching layer inherits CEX's lightweight operations (millisecond withdrawals, zero-gas orders), while the settlement layer inherits the verifiability constraints of on-chain DEX.
The finality of oracle result determination is the most distinguishing feature of prediction market matching. The other three types of markets are "continuously running"——prices are always changing, and markets are always open. However, prediction markets have a clear "termination moment": the event occurs, and the result is parsed by an oracle (Polymarket uses UMA's optimistic oracle), determining whether YES or NO (which may also be disputed; this paper does not discuss that), and all positions settle at 1:0 or 0:1. This means that the matching engine must handle a "market freeze" state machine: prohibiting new orders during the parsing window and allowing challenges during the dispute window, finally stopping all trading activities after the final settlement. This kind of state machine has no counterpart in CEX spot.
The price being constrained to [0, 1] is another mechanistic constraint. This appears advantageous (prevents infinite liquidation), but it means that the price tier space in the order book is limited——generally 1 cent per level, with a maximum of 100 tiers. This imposes a strong constraint on the matching data structure (you could use a fixed-size array instead of a tree), but it also means that the precision of price discovery has an upper limit.
To illustrate how mint/redeem shapes market-making behavior, consider a specific market reporting YES at $0.65 and NO at $0.35 (YES + NO must equal $1; otherwise, arbitragers will immediately mint or redeem to balance). Market maker M wants to provide liquidity for selling in this market but has no YES; he deposits 100 USDC into the CTF contract, instantly receiving 100 YES + 100 NO, and posts 100 YES at 0.66 and 100 NO at 0.36. Once both fill, M holds a net exposure of 0, earning a bid-ask spread of 0.02 × 100 = 2 USDC. This exemplifies the standard playbook in Polymarket market-making: leveraging mint/redeem to convert "capital occupation" into "bilateral pricing spread."
It's noteworthy to analyze: the invariant YES + NO = 1 is not actively maintained by the matching engine; it is automatically ensured by the market structure through arbitragers——this kind of "invariant carried by market structure" is not present in traditional LOB, and market makers cannot sell "without holding inventory." Therefore, the design of Polymarket's matching engine can omit certain inventory constraint checks that are necessary for CEX but at the cost of requiring the mint/redeem path to be tightly integrated into the settlement contract.
To summarize the distinctiveness of Polymarket matching: the trust assumptions are a mix of "off-chain matching + on-chain settlement," the token model is the CTF's complementary minting, the price space is a bounded discrete [0, 1], the time dimension has an endpoint, and gas is borne by the relayer and recouped through fees. These constraints together create a matching engine with a completely different form than the first three.
7. Where the differences come from: A five-dimensional framework
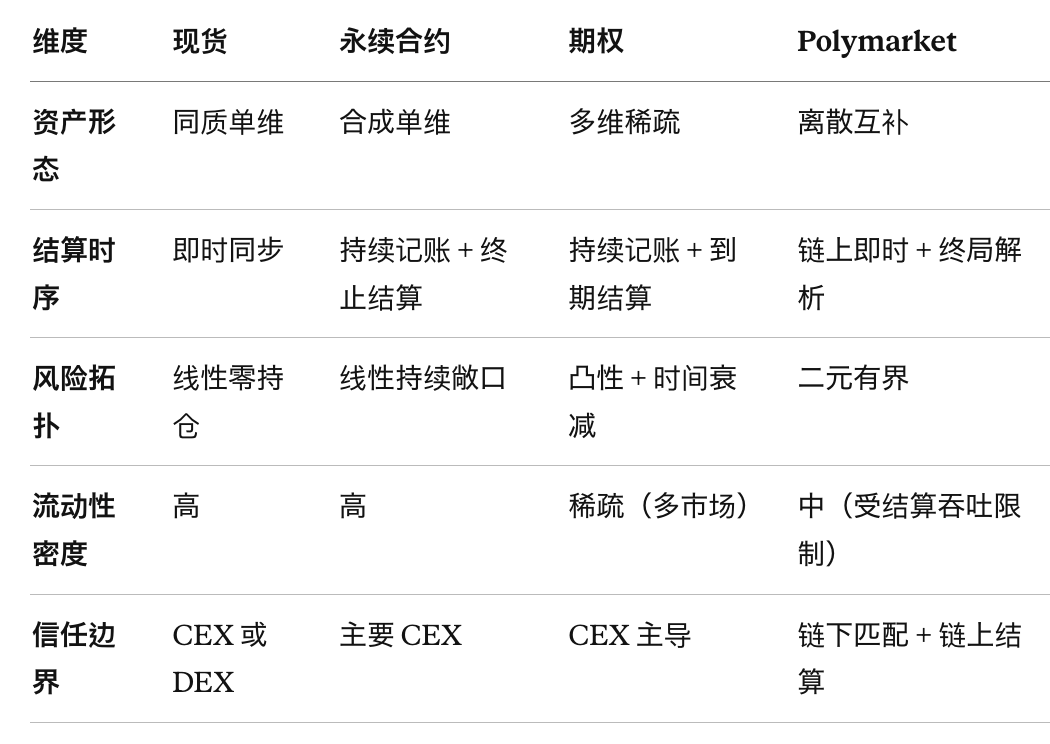
By laying out these four forms, five dimensions can be distilled to explain why matching engines differentiate under different subjects:
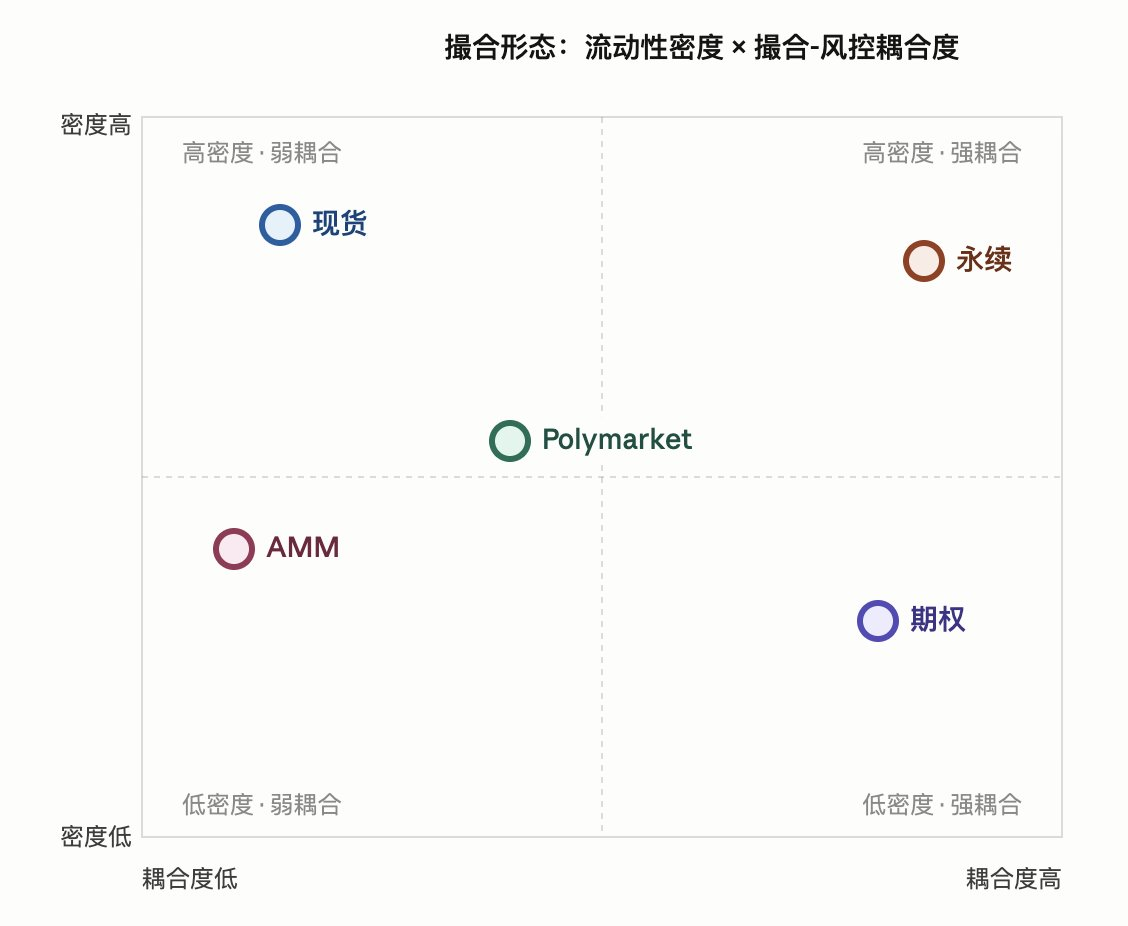
Placing the five-dimensional framework on the two dimensions of "matching-risk control coupling degree" and "liquidity density," the positions of the four forms become clear: spot is in the comfortable zone of low coupling and high density, perpetual is in high coupling and high density (the most complex engineering reality), options are in high coupling and low density (must use RFQ + combo to mitigate sparsity), and Polymarket falls in the middle——its coupling degree is raised by on-chain settlement, while density is boosted by complementary minting.
Each dimension applies pressure on the matching engine:
The asset form determines the number and sparsity of the order books. Homogeneous in a single dimension (spot, perp) only needs one book, while multi-dimensional sparsity (options) requires hundreds of books and must address sparsity; discrete complementarity (Polymarket) needs to incorporate "mint/redeem" into the matching path.
Settlement timing determines the complexity of the state machine. Instant synchronization (spot) makes matching equal to settlement; continuous accounting (perp, options) requires maintaining position states, margin states, PnL states, and updating them after each match; final parsing (Polymarket) requires the state machine to transition from "open" to "frozen" to "parsed."
Risk topology determines the degree of risk control coupling. Linear zero positions (spot) hardly require risk control; linear continuous exposures (perp) require pre-trade margin checks and a liquidation engine; convexity (options) requires Greeks-based composite margins; binary bounded (prediction) hardly needs risk control (the maximum loss is the money paid).
Liquidity density determines the liquidity source strategy. High-density markets can use pure LOB; sparse markets must introduce RFQ, AMM, market maker incentives, and other supplementary mechanisms.
Trust boundaries determine which components must be verifiable. All components are internal in CEX; all components are on-chain in pure DEX; in a mixed architecture, it must be clear what must be on-chain (settlement), what can be off-chain (matching), and what the attack model is (cannot steal money but can scrutinize).
8. Not a single step is superfluous: matching is a mirror of the mechanism
Returning to the initial question——why does the "matching engine" differentiate into four almost different machines across different markets?
Because matching is never an independent engineering module; it is the product of the nature of the assets themselves, settling models, risk structures, liquidity forms, and trust assumptions, these five variables acting in concert. The matching engine is the manifestation of these variables——you see what matching looks like, which in turn reveals what the financial structure of the market is like.
The simplicity of spot matching corresponds to a "homogeneous asset + one-time settlement + zero position continuation" clean structure;
The complexity of perpetual contract matching corresponds to an "synthetic asset + continuous exposure + deep coupling of risk control and matching" engineering reality;
The hybrid form of options matching corresponds to a "dimensional explosion + liquidity sparsity + market maker dominance" market structure;
The on-chain and off-chain split of Polymarket's matching corresponds to an engineering compromise between "no scrutiny" and "anti-theft" security goals.
If settlement is the conscience of the exchange, then the matching mechanism is the bottom line of the exchange.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








