谷歌今天发布了Veo 3.1,这是其AI视频生成器的更新版本,增加了音频功能,并引入了新的编辑能力,旨在让创作者对他们的剪辑有更多的控制权。
这一公告正值OpenAI的竞争应用Sora 2在应用商店排行榜上攀升,并引发关于AI生成内容充斥社交媒体的辩论。
这一时机表明谷歌希望将Veo 3.1定位为Sora 2病毒式社交动态的专业替代品。OpenAI于9月30日推出了Sora 2,采用了优先考虑分享和重混的TikTok风格界面。
该应用在五天内达到了100万次下载,并在苹果App Store中位居榜首。Meta采取了类似的方法,推出了由AI视频驱动的虚拟社交媒体。
用户现在可以使用“视频成分”工具创建带有同步环境噪音、对话和音效的影片,该工具将多个参考图像组合成一个场景。
“帧到视频”功能在起始图像和结束图像之间生成过渡,而“延续”功能通过延续现有视频最后一秒的动作,创建持续最长达一分钟的剪辑。
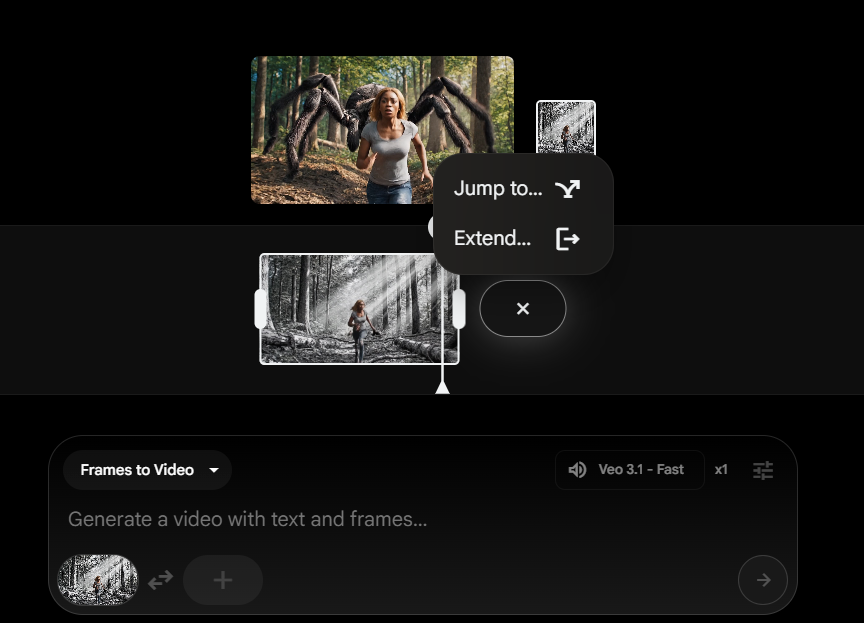
新的编辑工具允许用户从生成的场景中添加或移除元素,并自动调整阴影和光照。该模型以1080p分辨率生成视频,支持横向或纵向的宽高比。
该模型通过Flow供消费者使用,通过Gemini API供开发者使用,以及通过Vertex AI供企业客户使用。可以使用“延续”功能创建最长达一分钟的视频,该功能延续现有剪辑最后一秒的动作。
到2025年,AI视频生成市场变得拥挤,Runway的Gen-4模型针对电影制作人,Luma Labs为社交媒体提供快速生成,Adobe将Firefly Video集成到Creative Cloud中,xAI、Kling、Meta和谷歌的更新则针对真实感、声音生成和提示遵循。
但它的效果如何?我们测试了该模型,以下是我们的印象。
测试模型
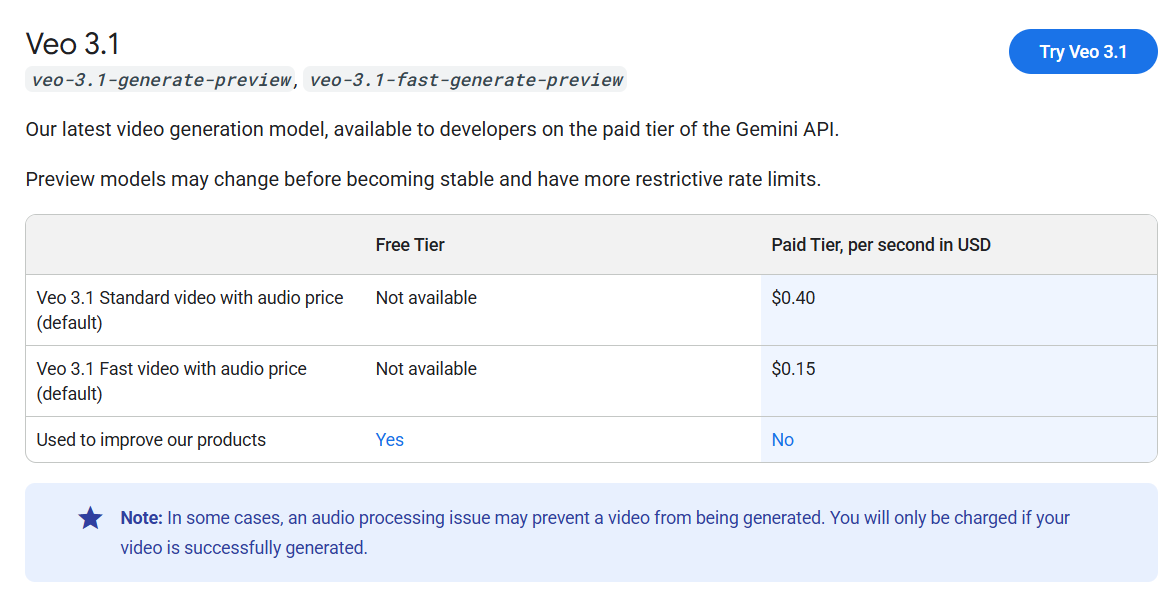
如果你想尝试,最好有一些深厚的资金。Veo 3.1目前是最昂贵的视频生成模型,与Sora 2持平,仅次于Sora 2 Pro,后者每次生成的费用是其两倍多。
免费用户每月获得100个积分来测试系统,这足以每月生成大约五个视频。通过Gemini API,Veo 3.1生成带音频的视频大约需要$0.40每秒,而一种名为Veo 3.1 Fast的更快变体则为每秒$0.15。
对于愿意以此价格使用的人来说,以下是它的优缺点。
文本到视频
Veo 3.1相比其前身有了明显的改进。该模型在连贯性方面表现良好,并展示了对上下文环境的更好理解。
它在不同风格之间运作,从照片真实主义到风格化内容。
我们要求模型融合一个场景,该场景从一幅画开始,过渡到实景镜头。它在处理这一任务时的表现优于我们测试的任何其他模型。
在没有任何参考帧的情况下,Veo 3.1在文本到视频模式下的表现优于使用相同提示和初始图像时的表现,这让人感到惊讶。
权衡在于运动速度。Veo 3.1优先考虑连贯性而非流畅性,这使得生成快速动作变得具有挑战性。
元素移动得较慢,但在整个剪辑中保持一致性。Kling在快速运动方面仍然领先,尽管它需要更多的尝试才能获得可用的结果。
图像到视频
Veo在图像到视频生成方面建立了声誉,结果仍然令人满意——但有一些警告。这似乎是更新中的一个薄弱环节。当使用不同的宽高比作为起始帧时,模型在保持曾经的连贯性水平方面遇到了困难。
如果提示与输入图像逻辑上应跟随的内容相差太远,Veo 3.1会找到一种“作弊”的方式。它生成不连贯的场景或剪辑,这些剪辑在不同地点、设置或完全不同的元素之间跳跃。
这浪费了时间和积分,因为这些剪辑无法编辑成更长的序列,因为它们不符合格式。
当它有效时,结果看起来非常出色。达到这一点既需要技巧,也需要运气——主要是运气。
元素到视频
此功能类似于视频的修复,让用户可以从场景中插入或删除元素。不过,不要指望它能保持完美的连贯性或使用你提供的确切参考图像。
例如,下面的视频是使用这三个参考和提示生成的:一名男子和一名女子在未来城市中奔跑时偶然相遇,那里有一个旋转的比特币标志全息图。男子对女子说:“快,比特币崩盘了!我们必须买更多!”

正如你所看到的,城市和角色实际上并不存在。然而,角色穿着参考中的衣服,城市与图像中的城市相似,事物表现出元素的概念,而不是元素本身。
Veo 3.1将上传的元素视为灵感,而不是严格的模板。它生成遵循提示的场景,并包括与您提供的对象相似的物体,但不要浪费时间试图将自己插入电影——这不会奏效。
一种变通方法:使用Nanobanana或Seedream先上传元素并生成一个连贯的起始帧。然后将该图像输入Veo 3.1,它将生成一个视频,其中角色和物体在整个场景中显示出最小的变形。
带对话的文本到视频
这是谷歌的卖点。Veo 3.1在唇同步方面的表现优于目前可用的任何其他模型。在文本到视频模式下,它生成与场景元素匹配的连贯环境声音。
对话、语调、声音和情感都准确无误,超越了竞争模型。
其他生成器可以产生环境噪音,但只有Sora、Veo和Grok能够生成实际的单词。
在这三者中,Veo 3.1在文本到视频模式下获得良好结果所需的尝试次数最少。
带对话的图像到视频
在这里事情就崩溃了。带对话的图像到视频生成遭遇了与标准图像到视频生成相同的问题。Veo 3.1过于重视连贯性,以至于忽视了提示遵循和参考图像。
例如,这个场景是使用元素到视频部分中显示的参考生成的。
正如你所看到的,我们的测试生成了与参考图像完全不同的主题。视频质量非常出色——语调和手势都很到位——但这不是我们上传的人,使得结果毫无用处。
Sora的重混功能是这个用例的最佳选择。该模型可能受到审查,但其图像到视频的能力、真实的唇同步以及对语调、口音、情感和真实感的关注使其成为明显的赢家。
Grok的视频生成器排名第二。它比Veo 3.1更好地尊重了参考图像,并产生了更优的结果。这是使用相同参考图像和提示生成的一次。
如果你不想处理Sora的社交应用或无法访问它,Grok可能是你最好的选择。它也是未审查的,但经过审核,因此如果你需要这种特定的方法,马斯克可以满足你的需求。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






