Author: Jacob Zhao, IOSG
Artificial intelligence is transitioning from a statistical learning paradigm focused on "pattern fitting" to a capability system centered on "structured reasoning," with the importance of post-training rapidly increasing. The emergence of DeepSeek-R1 marks a paradigm shift for reinforcement learning in the era of large models, leading to a consensus in the industry: pre-training builds a general capability foundation for models, and reinforcement learning is no longer just a tool for value alignment but has been proven to systematically enhance the quality of reasoning chains and complex decision-making capabilities, gradually evolving into a technical path for continuously improving intelligence levels.
At the same time, Web3 is reconstructing the production relationship of AI through decentralized computing networks and cryptographic incentive systems, while the structural needs of reinforcement learning for rollout sampling, reward signals, and verifiable training naturally align with blockchain's computational collaboration, incentive distribution, and verifiable execution. This research report will systematically break down the AI training paradigm and the technical principles of reinforcement learning, demonstrating the structural advantages of reinforcement learning × Web3, and analyzing projects such as Prime Intellect, Gensyn, Nous Research, Gradient, Grail, and Fraction AI.
I. Three Stages of AI Training: Pre-training, Instruction Fine-tuning, and Post-training Alignment
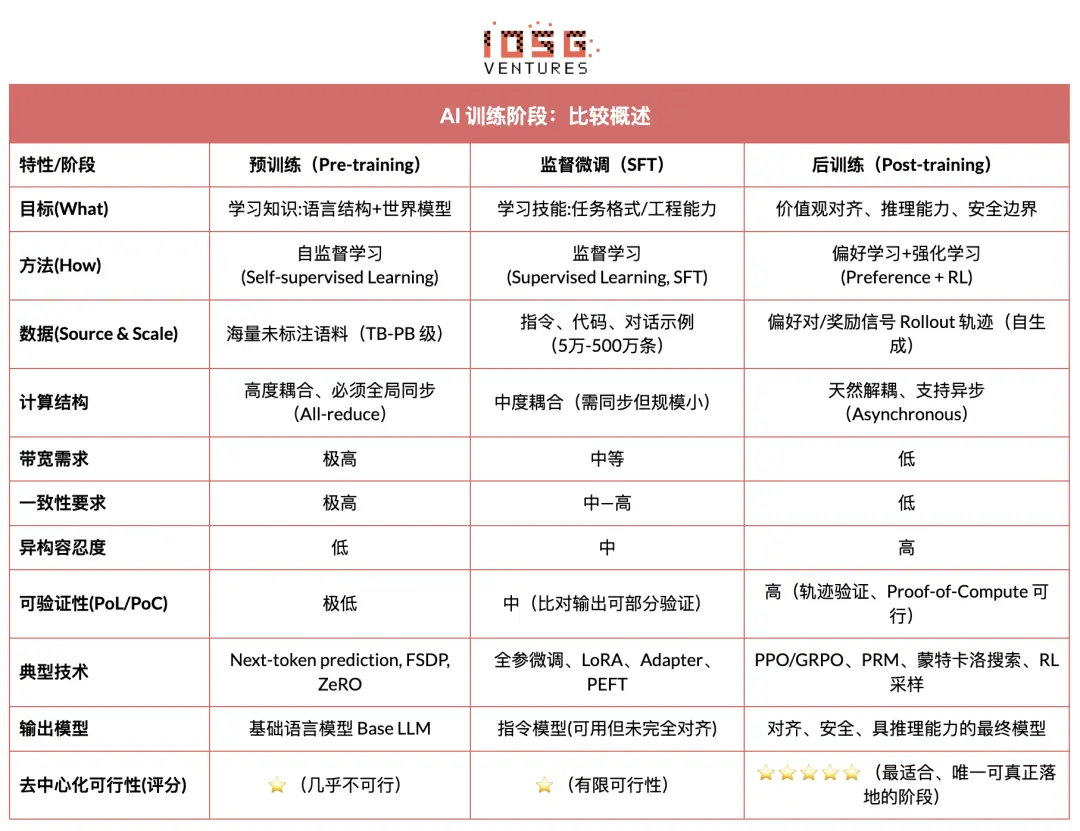
The entire lifecycle of modern large language model (LLM) training is typically divided into three core stages: Pre-training, Supervised Fine-tuning (SFT), and Post-training (Post-training/RL). Each stage serves the function of "building a world model—injecting task capabilities—shaping reasoning and values," and the computational structure, data requirements, and verification difficulties determine the degree of decentralization.
Pre-training builds the language statistical structure and cross-modal world model of the model through large-scale self-supervised learning, forming the foundation of LLM capabilities. This stage requires training on trillions of tokens in a globally synchronized manner, relying on thousands to tens of thousands of H100 homogeneous clusters, with costs accounting for 80–95%. It is extremely sensitive to bandwidth and data copyright, thus must be completed in a highly centralized environment.
Fine-tuning is used to inject task capabilities and instruction formats, with a smaller data volume and costs accounting for about 5–15%. Fine-tuning can be conducted through full parameter training or parameter-efficient fine-tuning (PEFT) methods, with LoRA, Q-LoRA, and Adapter being mainstream in the industry. However, it still requires synchronized gradients, limiting its decentralization potential.
Post-training consists of multiple iterative sub-stages that determine the model's reasoning ability, values, and safety boundaries. Its methods include reinforcement learning systems (RLHF, RLAIF, GRPO) as well as non-RL preference optimization methods (DPO) and process reward models (PRM). This stage has lower data volume and costs (5–10%), mainly focusing on rollout and policy updates; it naturally supports asynchronous and distributed execution, where nodes do not need to hold complete weights. Combined with verifiable computation and on-chain incentives, it can form an open decentralized training network, making it the most compatible training segment for Web3.
II. Overview of Reinforcement Learning Technology: Architecture, Framework, and Applications
System Architecture and Core Elements of Reinforcement Learning
Reinforcement Learning (RL) drives the model's autonomous improvement of decision-making capabilities through "environment interaction—reward feedback—policy update." Its core structure can be viewed as a feedback loop composed of states, actions, rewards, and policies. A complete RL system typically includes three types of components: Policy (policy network), Rollout (experience sampling), and Learner (policy updater). The policy interacts with the environment to generate trajectories, and the Learner updates the policy based on reward signals, forming a continuous iterative and optimizing learning process:
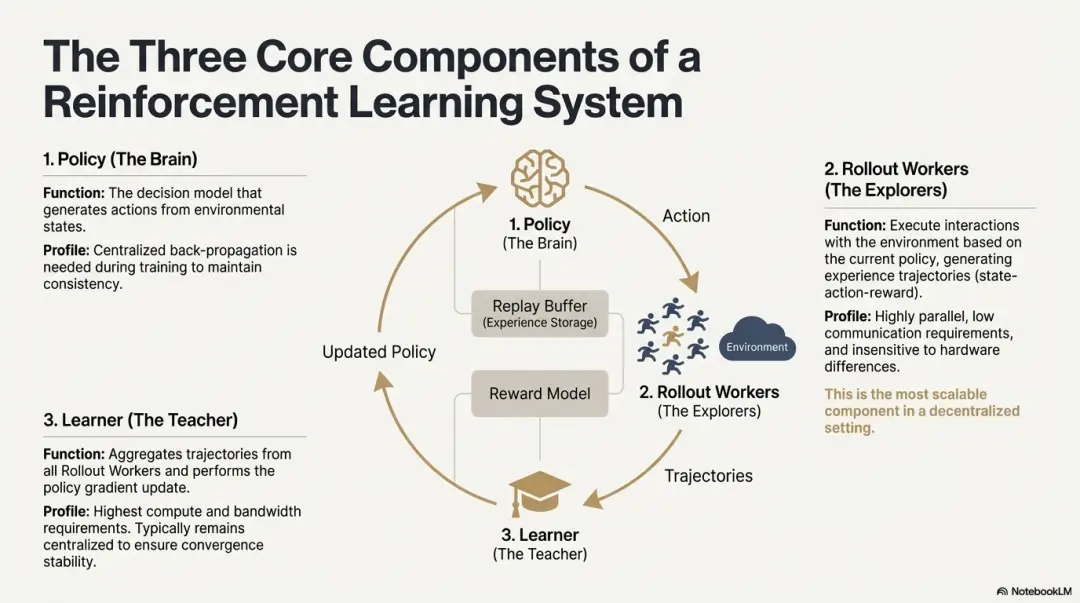
Policy: Generates actions from the environment state and is the core of the system's decision-making. During training, centralized backpropagation is required to maintain consistency; during inference, it can be distributed to different nodes for parallel execution.
Rollout: Nodes execute environment interactions based on the policy, generating state-action-reward trajectories. This process is highly parallel, with minimal communication, and is less sensitive to hardware differences, making it the most suitable segment for scaling in a decentralized manner.
Learner: Aggregates all Rollout trajectories and performs policy gradient updates, being the module with the highest requirements for computing power and bandwidth. Therefore, it is usually kept centralized or lightly centralized to ensure convergence stability.
Reinforcement Learning Stage Framework (RLHF → RLAIF → PRM → GRPO)
Reinforcement learning can typically be divided into five stages, with the overall process described as follows:
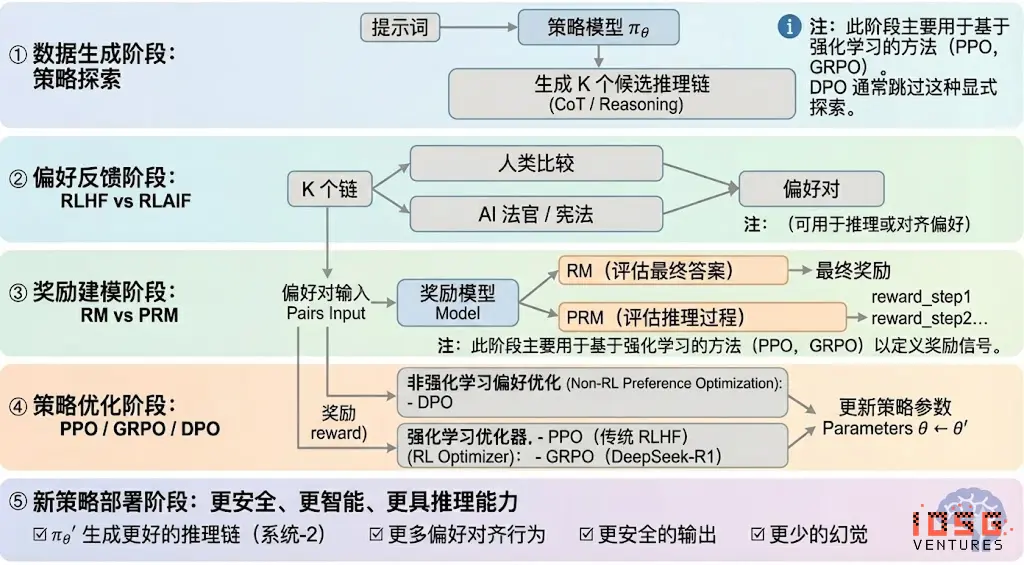
# Data Generation Stage (Policy Exploration)
Under the condition of given input prompts, the policy model πθ generates multiple candidate reasoning chains or complete trajectories, providing a sample basis for subsequent preference evaluation and reward modeling, determining the breadth of policy exploration.
# Preference Feedback Stage (RLHF / RLAIF)
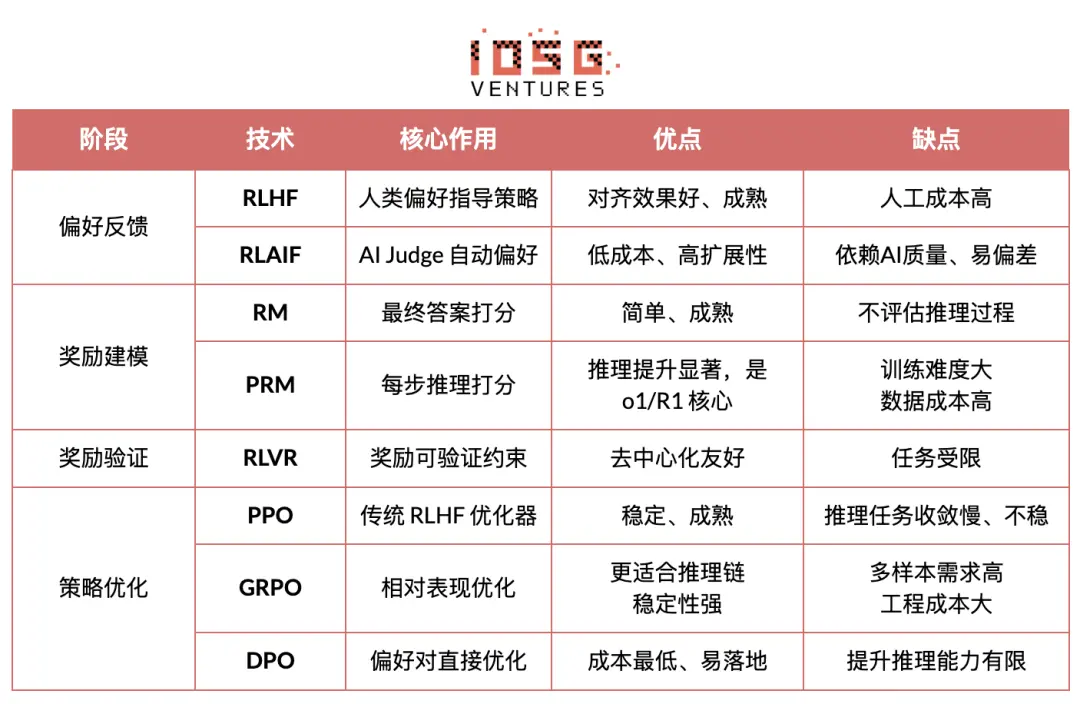
RLHF (Reinforcement Learning from Human Feedback) generates multiple candidate responses, annotates human preferences, trains reward models (RM), and optimizes policies using PPO, making model outputs more aligned with human values. This is a key step from GPT-3.5 to GPT-4.
RLAIF (Reinforcement Learning from AI Feedback) replaces human annotations with AI judges or constitutional rules, automating preference acquisition, significantly reducing costs, and exhibiting scalability. It has become the mainstream alignment paradigm for Anthropic, OpenAI, DeepSeek, and others.
# Reward Modeling Stage (Reward Modeling)
Preferences inform the input reward model, learning to map outputs to rewards. RM teaches the model "what the correct answer is," while PRM teaches the model "how to reason correctly."
RM (Reward Model) is used to evaluate the quality of final answers, scoring only the outputs:
PRM (Process Reward Model) evaluates not only the final answer but also scores each step of reasoning, each token, and each logical segment. It is also a key technology of OpenAI o1 and DeepSeek-R1, essentially "teaching the model how to think."
# Reward Verification Stage (RLVR / Reward Verifiability)
In the process of generating and using reward signals, "verifiable constraints" are introduced, ensuring that rewards come as much as possible from reproducible rules, facts, or consensus, thereby reducing the risks of reward hacking and bias, and enhancing auditability and scalability in open environments.
# Policy Optimization Stage (Policy Optimization)
This stage updates policy parameters θ based on signals provided by the reward model to achieve stronger reasoning capabilities, higher safety, and more stable behavior patterns in the policy πθ′. Mainstream optimization methods include:
PPO (Proximal Policy Optimization): The traditional optimizer for RLHF, known for its stability, but often faces limitations such as slow convergence and insufficient stability in complex reasoning tasks.
GRPO (Group Relative Policy Optimization): A core innovation of DeepSeek-R1, it models the advantage distribution within candidate answer groups to estimate expected value rather than simple ranking. This method retains reward magnitude information, making it more suitable for reasoning chain optimization, with a more stable training process, regarded as an important reinforcement learning optimization framework for deep reasoning scenarios following PPO.
DPO (Direct Preference Optimization): A non-reinforcement learning post-training method that does not generate trajectories or build reward models but directly optimizes on preferences, being low-cost and stable in effect, widely used for aligning open-source models like Llama and Gemma, but does not enhance reasoning capabilities.
# New Policy Deployment Stage (New Policy Deployment)
The optimized model exhibits: stronger reasoning chain generation capabilities (System-2 Reasoning), behaviors more aligned with human or AI preferences, lower hallucination rates, and higher safety. The model continuously learns preferences, optimizes processes, and improves decision quality through ongoing iterations, forming a closed loop.
Five Major Categories of Industrial Applications of Reinforcement Learning
Reinforcement Learning has evolved from early game intelligence to a core framework for autonomous decision-making across industries. Its application scenarios can be categorized into five major types based on technological maturity and industrial implementation, driving key breakthroughs in their respective directions.
Game & Strategy: This is the earliest validated direction for RL, where RL has demonstrated decision-making intelligence comparable to or even surpassing human experts in environments with "perfect information + clear rewards," such as AlphaGo, AlphaZero, AlphaStar, and OpenAI Five, laying the foundation for modern RL algorithms.
Embodied AI: RL enables robots to learn manipulation, motion control, and cross-modal tasks (e.g., RT-2, RT-X) through continuous control, dynamics modeling, and environmental interaction, rapidly moving towards industrialization and serving as a key technological route for real-world robot deployment.
Digital Reasoning / LLM System-2: RL + PRM drives large models from "language imitation" to "structured reasoning," with representative achievements including DeepSeek-R1, OpenAI o1/o3, Anthropic Claude, and AlphaGeometry. The essence lies in optimizing rewards at the reasoning chain level rather than merely evaluating final answers.
Scientific Discovery: RL seeks optimal structures or strategies in unlabeled, complex reward scenarios with vast search spaces, achieving foundational breakthroughs such as AlphaTensor, AlphaDev, and Fusion RL, showcasing exploration capabilities that surpass human intuition.
Economic Decision-making & Trading: RL is used for strategy optimization, high-dimensional risk control, and adaptive trading system generation, enabling continuous learning in uncertain environments compared to traditional quantitative models, making it an important component of intelligent finance.
III. The Natural Match Between Reinforcement Learning and Web3
The high compatibility between Reinforcement Learning (RL) and Web3 stems from the fact that both are essentially "incentive-driven systems." RL relies on reward signals to optimize strategies, while blockchain coordinates participant behavior through economic incentives, making their mechanisms inherently consistent. The core requirements of RL—large-scale heterogeneous Rollout, reward distribution, and authenticity verification—align perfectly with the structural advantages of Web3.
# Decoupling Reasoning and Training
The training process of reinforcement learning can be clearly divided into two stages:
Rollout (Exploration Sampling): The model generates a large amount of data based on the current policy, which is computation-intensive but communication-sparse. It does not require frequent communication between nodes, making it suitable for parallel generation on globally distributed consumer-grade GPUs.
Update (Parameter Update): This stage updates the model weights based on the collected data and requires high-bandwidth centralized nodes to complete.
The "decoupling of reasoning and training" naturally fits the decentralized heterogeneous computing structure: Rollout can be outsourced to an open network, settled based on contributions through a token mechanism, while model updates remain centralized to ensure stability.
# Verifiability
ZK and Proof-of-Learning provide means to verify whether nodes genuinely execute reasoning, addressing honesty issues in open networks. In deterministic tasks such as code and mathematical reasoning, verifiers only need to check the answers to confirm the workload, significantly enhancing the credibility of decentralized RL systems.
# Incentive Layer: Token-Economy-Based Feedback Production Mechanism
The token mechanism of Web3 can directly reward contributors of preference feedback in RLHF/RLAIF, creating a transparent, accountable, and permissionless incentive structure for preference data generation. Staking and slashing further constrain feedback quality, forming a more efficient and aligned feedback market than traditional crowdsourcing.
# Potential of Multi-Agent Reinforcement Learning (MARL)
Blockchain is essentially a public, transparent, and continuously evolving multi-agent environment, where accounts, contracts, and agents constantly adjust strategies under incentive-driven conditions, making it inherently capable of building large-scale MARL experimental fields. Although still in its early stages, its characteristics of public state, verifiable execution, and programmable incentives provide principled advantages for the future development of MARL.
IV. Analysis of Classic Web3 + Reinforcement Learning Projects
Based on the theoretical framework above, we will briefly analyze the most representative projects in the current ecosystem:
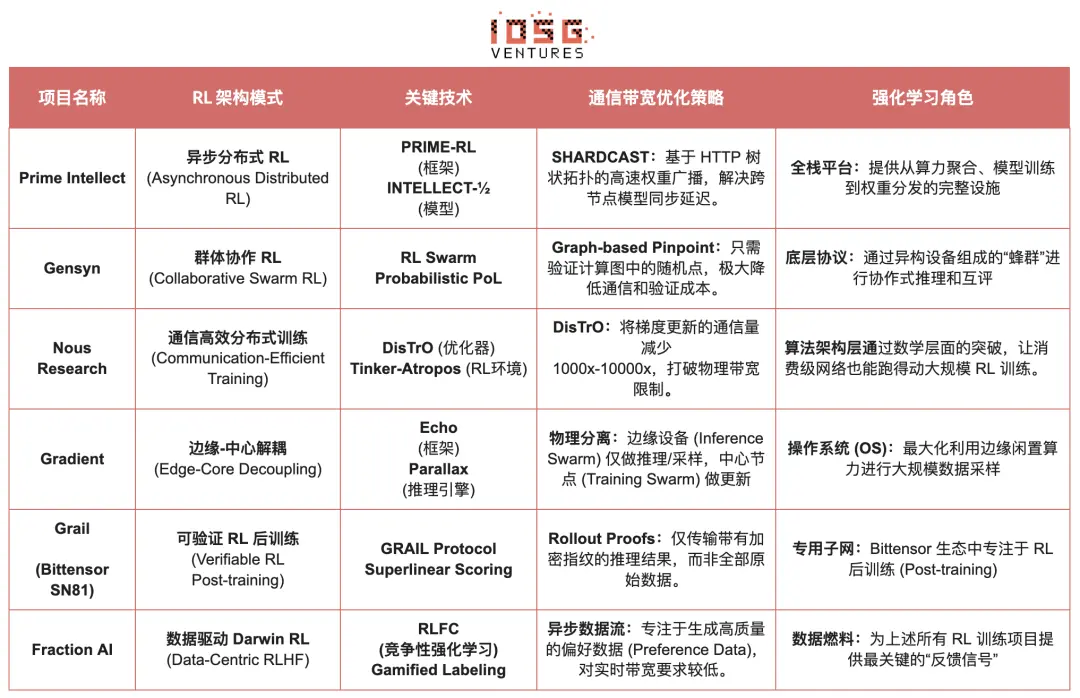
Prime Intellect: Asynchronous Reinforcement Learning Paradigm prime-rl
Prime Intellect is dedicated to building a global open computing power market, lowering training thresholds, promoting collaborative decentralized training, and developing a complete open-source superintelligence technology stack. Its system includes: Prime Compute (unified cloud/distributed computing environment), INTELLECT model family (10B–100B+), Open Reinforcement Learning Environment Center (Environments Hub), and large-scale synthetic data engine (SYNTHETIC-1/2).
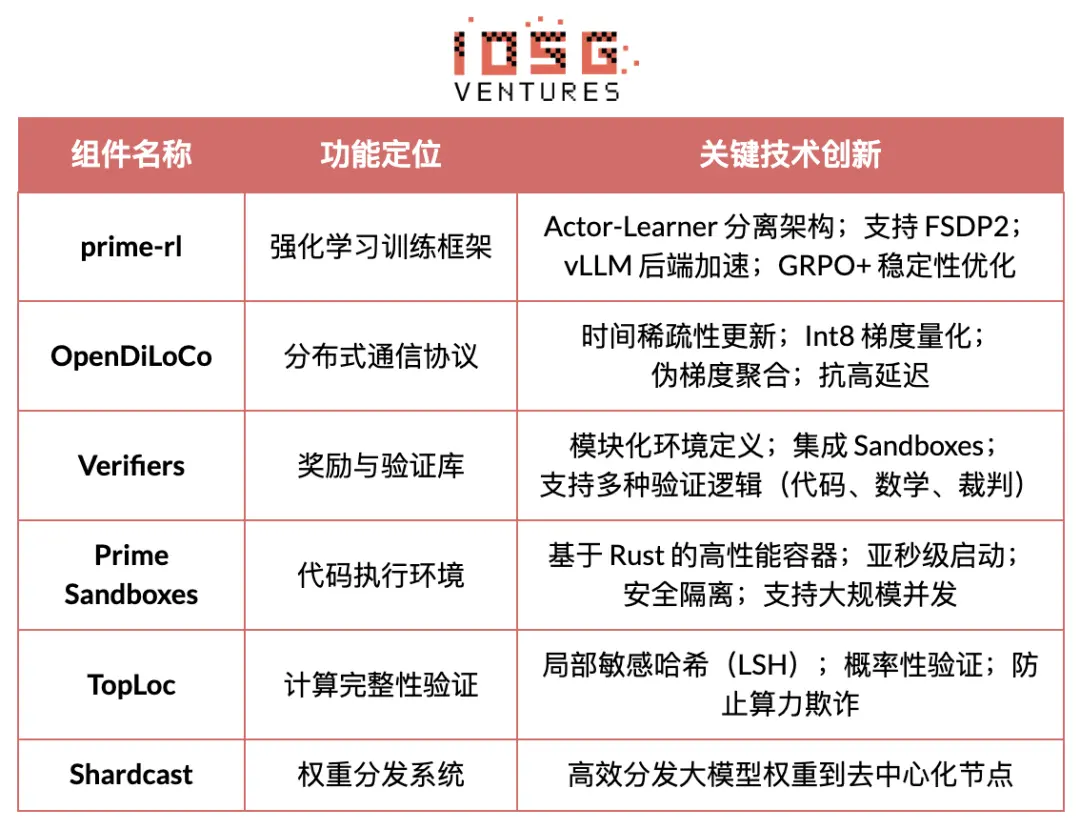
The core infrastructure component of Prime Intellect, the prime-rl framework, is designed for asynchronous distributed environments and is highly relevant to reinforcement learning. Other components include the OpenDiLoCo communication protocol, which breaks bandwidth bottlenecks, and the TopLoc verification mechanism, which ensures computational integrity.
# Overview of Prime Intellect's Core Infrastructure Components
# Technical Cornerstone: prime-rl Asynchronous Reinforcement Learning Framework
prime-rl is the core training engine of Prime Intellect, designed for large-scale asynchronous decentralized environments. It achieves high-throughput reasoning and stable updates through complete decoupling of Actor–Learner. The executors (Rollout Workers) and learners (Trainers) no longer block synchronously; nodes can join or leave at any time, only needing to continuously pull the latest policy and upload generated data:
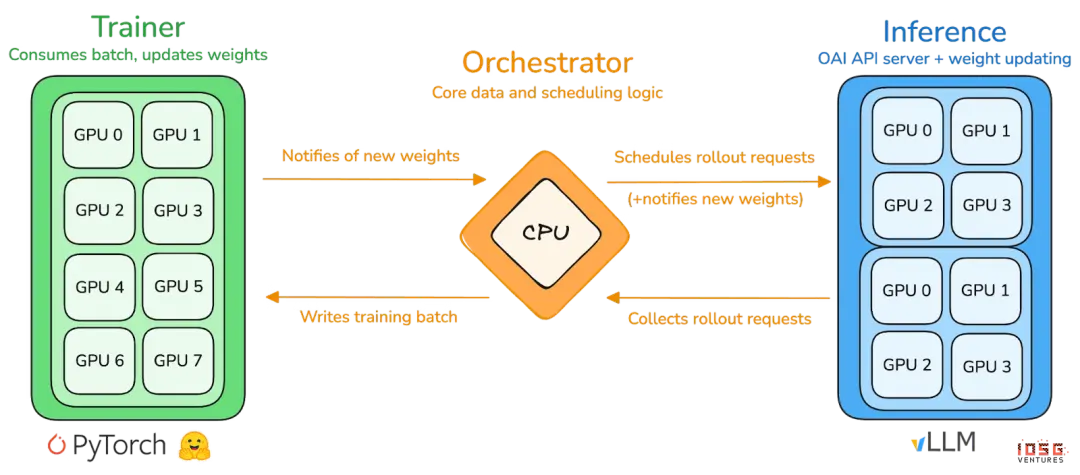
Executor Actor (Rollout Workers): Responsible for model reasoning and data generation. Prime Intellect innovatively integrates the vLLM reasoning engine on the Actor side. The PagedAttention technology and continuous batching capability of vLLM enable Actors to generate reasoning trajectories with extremely high throughput.
Learner (Trainer): Responsible for policy optimization. The Learner asynchronously pulls data from a shared experience replay buffer (Experience Buffer) for gradient updates without waiting for all Actors to complete the current batch.
Orchestrator: Responsible for scheduling model weights and data flow.
# Key Innovations of prime-rl
True Asynchrony: prime-rl abandons the synchronous paradigm of traditional PPO, not waiting for slow nodes or requiring batch alignment, allowing any number and performance of GPUs to connect at any time, establishing the feasibility of decentralized RL.
Deep Integration of FSDP2 and MoE: Through FSDP2 parameter slicing and MoE sparse activation, prime-rl enables efficient training of hundred-billion-level models in distributed environments, with Actors only running active experts, significantly reducing memory and inference costs.
GRPO+ (Group Relative Policy Optimization): GRPO eliminates the Critic network, significantly reducing computational and memory overhead, naturally adapting to asynchronous environments. The GRPO+ of prime-rl further ensures reliable convergence under high-latency conditions through stabilization mechanisms.
# INTELLECT Model Family: A Mark of Decentralized RL Technology Maturity
INTELLECT-1 (10B, October 2024): First proves that OpenDiLoCo can efficiently train across heterogeneous networks spanning three continents (communication accounts for 2%, computing power utilization at 98%), breaking the physical cognition of cross-regional training.
INTELLECT-2 (32B, April 2025): As the first permissionless RL model, it verifies the stable convergence capabilities of prime-rl and GRPO+ in multi-step delays and asynchronous environments, achieving decentralized RL with global open computing power participation.
INTELLECT-3 (106B MoE, November 2025): Adopts a sparse architecture that activates only 12B parameters, trained on 512×H200, achieving flagship-level reasoning performance (AIME 90.8%, GPQA 74.4%, MMLU-Pro 81.9%, etc.), with overall performance approaching or even surpassing centralized closed-source models of much larger scale.
Additionally, Prime Intellect has built several supporting infrastructures: OpenDiLoCo reduces the communication volume of cross-regional training by hundreds of times through time-sparse communication and quantized weight differences, maintaining 98% utilization for INTELLECT-1 across networks spanning three continents; TopLoc + Verifiers form a decentralized trusted execution layer, ensuring the authenticity of reasoning and reward data through activation fingerprints and sandbox verification; the SYNTHETIC data engine produces large-scale high-quality reasoning chains and efficiently runs the 671B model on consumer-grade GPU clusters through pipeline parallelism. These components provide a critical engineering foundation for data generation, verification, and reasoning throughput in decentralized RL. The INTELLECT series demonstrates that this technology stack can produce mature world-class models, marking the transition of decentralized training systems from the conceptual stage to practical application.
Gensyn: Core RL Stack RL Swarm and SAPO
Gensyn aims to aggregate global idle computing power into an open, trustless, and infinitely scalable AI training infrastructure. Its core includes a standardized execution layer across devices, a peer-to-peer coordination network, and a trustless task verification system, automatically allocating tasks and rewards through smart contracts. Centered around the characteristics of reinforcement learning, Gensyn introduces core mechanisms such as RL Swarm, SAPO, and SkipPipe, decoupling the generation, evaluation, and updating phases, and utilizing a "swarm" of globally heterogeneous GPUs for collective evolution. Its ultimate delivery is not merely computing power, but verifiable intelligence.
# Reinforcement Learning Applications in the Gensyn Stack
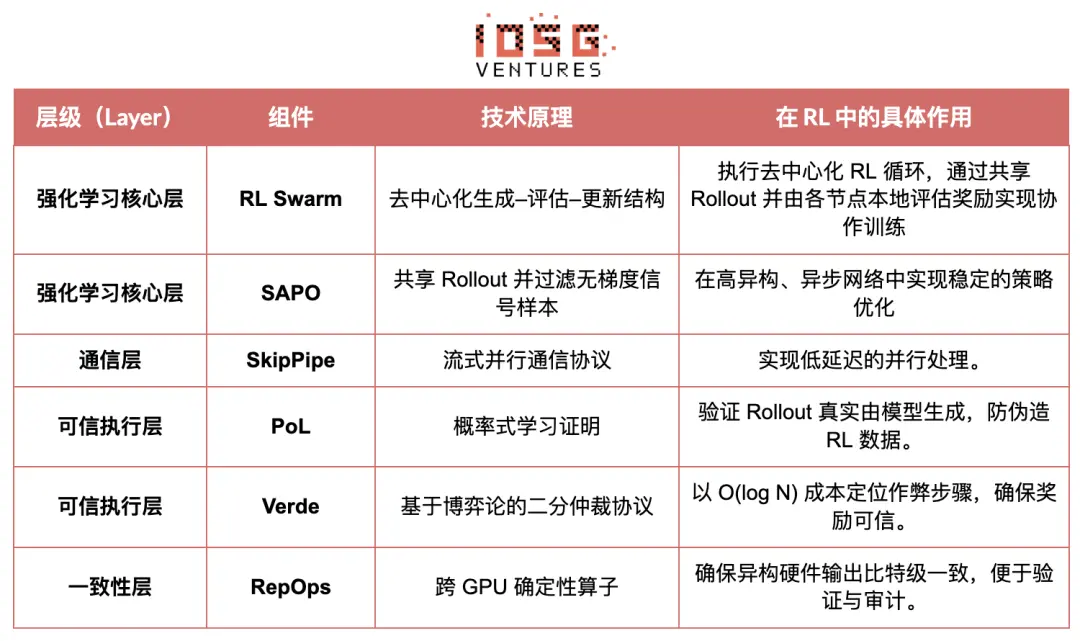
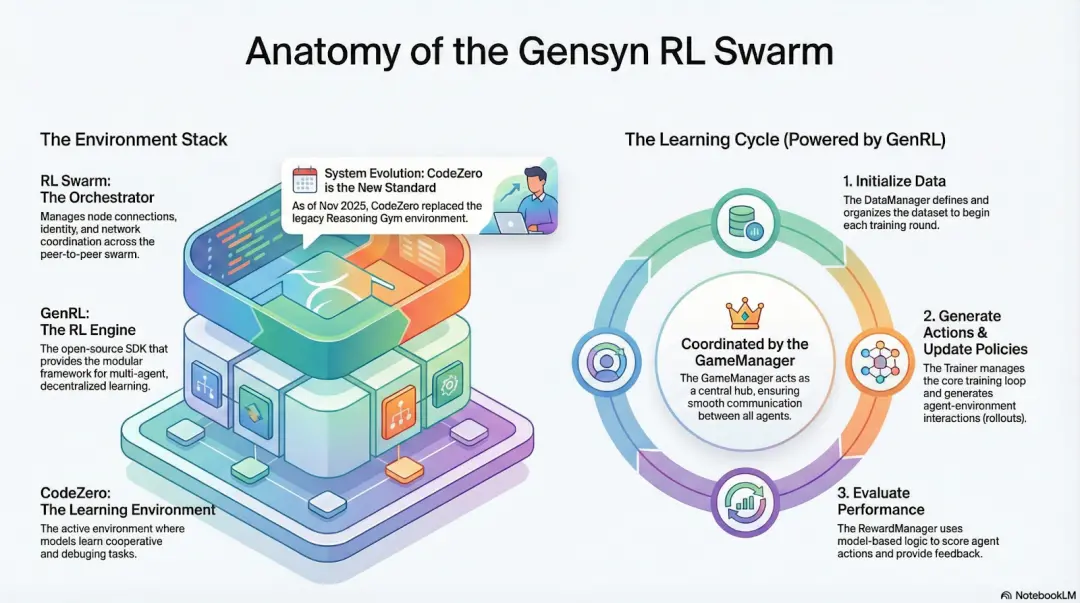
# RL Swarm: Decentralized Collaborative Reinforcement Learning Engine
RL Swarm showcases a new collaborative model. It is no longer a simple task distribution but a decentralized "generate-evaluate-update" loop that simulates human social learning, akin to a collaborative learning process, infinitely looping:
Solvers (Executors): Responsible for local model inference and Rollout generation, with heterogeneous nodes being inconsequential. Gensyn integrates high-throughput inference engines (such as CodeZero) locally, capable of outputting complete trajectories rather than just answers.
Proposers: Dynamically generate tasks (math problems, coding questions, etc.), supporting task diversity and difficulty adaptation similar to Curriculum Learning.
Evaluators: Use a frozen "judge model" or rules to evaluate local Rollouts, generating local reward signals. The evaluation process can be audited, reducing the space for malicious actions.
Together, these three form a P2P RL organizational structure that can achieve large-scale collaborative learning without centralized scheduling.
# SAPO: Strategy Optimization Algorithm Reconstructed for Decentralization
SAPO (Swarm Sampling Policy Optimization) focuses on "sharing Rollouts and filtering non-gradient signal samples rather than sharing gradients." It maintains stable convergence in environments with significant node delay differences and no central coordination through large-scale decentralized Rollout sampling, treating received Rollouts as locally generated. Compared to PPO, which relies on a Critic network and incurs high computational costs, or GRPO, which is based on intra-group advantage estimation, SAPO allows consumer-grade GPUs to effectively participate in large-scale reinforcement learning optimization with extremely low bandwidth.
Through RL Swarm and SAPO, Gensyn demonstrates that reinforcement learning (especially RLVR in the post-training phase) is naturally suited to decentralized architectures—because it relies more on large-scale, diverse exploration (Rollout) rather than high-frequency parameter synchronization. Combined with the verification systems of PoL and Verde, Gensyn provides an alternative path for training trillion-parameter models that no longer depends on a single tech giant: a self-evolving superintelligent network composed of millions of heterogeneous GPUs worldwide.
Nous Research: Verifiable Reinforcement Learning Environment Atropos
Nous Research is building a decentralized, self-evolving cognitive infrastructure. Its core components—Hermes, Atropos, DisTrO, Psyche, and World Sim—are organized into a continuously closed-loop intelligent evolution system. Unlike the traditional "pre-training—post-training—inference" linear process, Nous employs reinforcement learning techniques such as DPO, GRPO, and rejection sampling to unify data generation, verification, learning, and inference into a continuous feedback loop, creating a self-improving closed-loop AI ecosystem.
# Overview of Nous Research Components

# Model Layer: Evolution of Hermes and Inference Capabilities
The Hermes series is the main model interface for Nous Research, and its evolution clearly demonstrates the industry's transition from traditional SFT/DPO alignment to reasoning reinforcement learning (Reasoning RL):
Hermes 1–3: Instruction alignment and early agent capabilities: Hermes 1–3 achieved robust instruction alignment through low-cost DPO, and Hermes 3 introduced the Atropos verification mechanism with synthetic data.
Hermes 4 / DeepHermes: Incorporates System-2 style slow thinking into weights through thought chains, enhances mathematical and coding performance via Test-Time Scaling, and builds high-purity reasoning data relying on "rejection sampling + Atropos verification."
DeepHermes further adopts GRPO to replace PPO, which is difficult to implement in a distributed manner, allowing reasoning RL to run on the Psyche decentralized GPU network, laying the engineering foundation for the scalability of open-source reasoning RL.
# Atropos: Verifiable Reward-Driven Reinforcement Learning Environment
Atropos is the true hub of the Nous RL system. It encapsulates prompts, tool calls, code execution, and multi-turn interactions into a standardized RL environment, allowing direct verification of output correctness, thus providing deterministic reward signals that replace expensive and unscalable human annotations. More importantly, in the decentralized training network Psyche, Atropos acts as a "judge" to verify whether nodes genuinely improve strategies, supporting auditable Proof-of-Learning and fundamentally addressing the reward credibility issue in distributed RL.
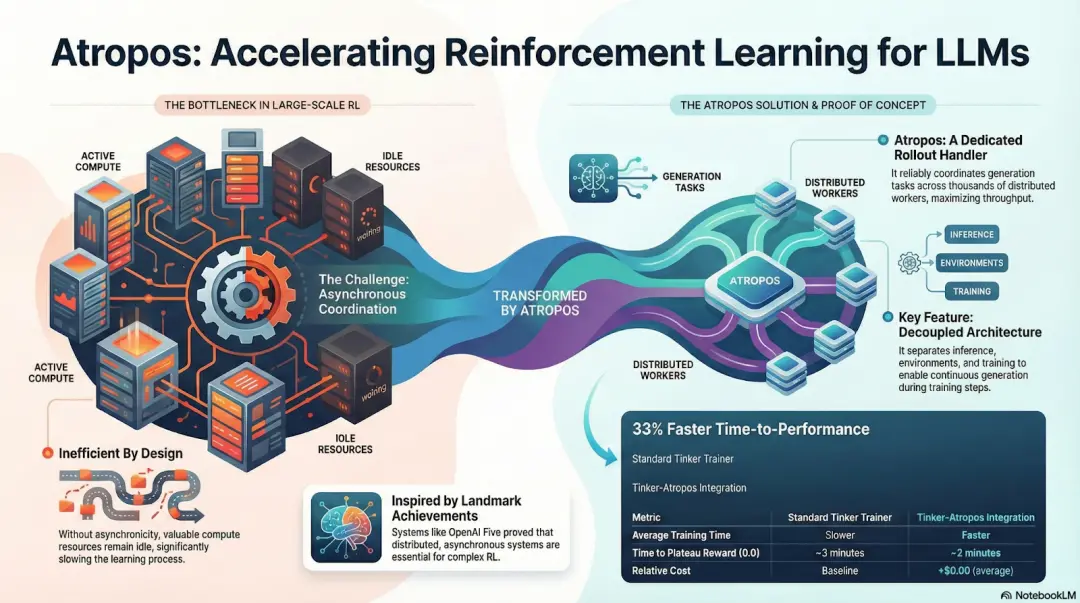
# DisTrO and Psyche: Optimizer Layer for Decentralized Reinforcement Learning
Traditional RLF (RLHF/RLAIF) training relies on centralized high-bandwidth clusters, which is a core barrier that open-source cannot replicate. DisTrO reduces the communication costs of RL by several orders of magnitude through momentum decoupling and gradient compression, enabling training to run on internet bandwidth; Psyche deploys this training mechanism on a blockchain network, allowing nodes to complete inference, verification, reward evaluation, and weight updates locally, forming a complete RL closed loop.
In Nous's system, Atropos verifies thought chains; DisTrO compresses training communication; Psyche runs the RL loop; World Sim provides complex environments; Forge collects real reasoning; Hermes writes all learning into weights. Reinforcement learning is not just a training phase but the core protocol in the Nous architecture that connects data, environments, models, and infrastructure, making Hermes a living system capable of continuous self-improvement on an open-source computing network.
Gradient Network: Reinforcement Learning Architecture Echo
The core vision of Gradient Network is to reconstruct the computational paradigm of AI through an "Open Intelligence Stack." Gradient's technology stack consists of a set of independently evolving yet heterogeneously collaborative core protocols. Its system includes: Parallax (distributed inference), Echo (decentralized RL training), Lattica (P2P network), SEDM / Massgen / Symphony / CUAHarm (memory, collaboration, security), VeriLLM (trusted verification), and Mirage (high-fidelity simulation), collectively forming a continuously evolving decentralized intelligent infrastructure.
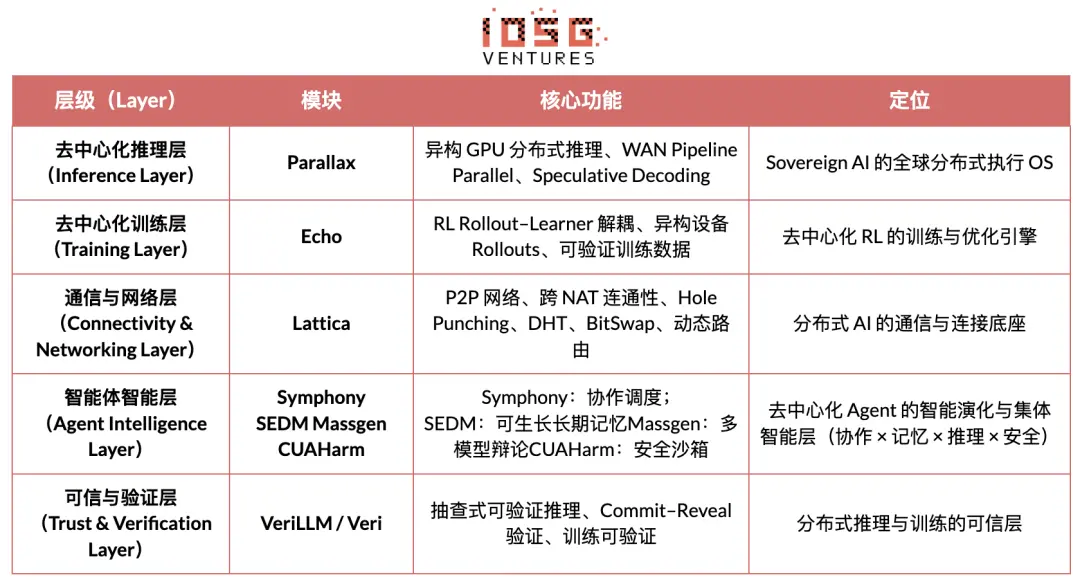
Echo — Reinforcement Learning Training Architecture
Echo is Gradient's reinforcement learning framework, with the core design concept of decoupling the training, inference, and data (reward) paths in reinforcement learning, allowing Rollout generation, policy optimization, and reward evaluation to independently scale and schedule in heterogeneous environments. It operates in a collaborative manner within a heterogeneous network composed of inference-side and training-side nodes, maintaining training stability in wide-area heterogeneous environments through lightweight synchronization mechanisms, effectively alleviating the SPMD failure and GPU utilization bottlenecks caused by mixed running of inference and training in traditional DeepSpeed RLHF / VERL.
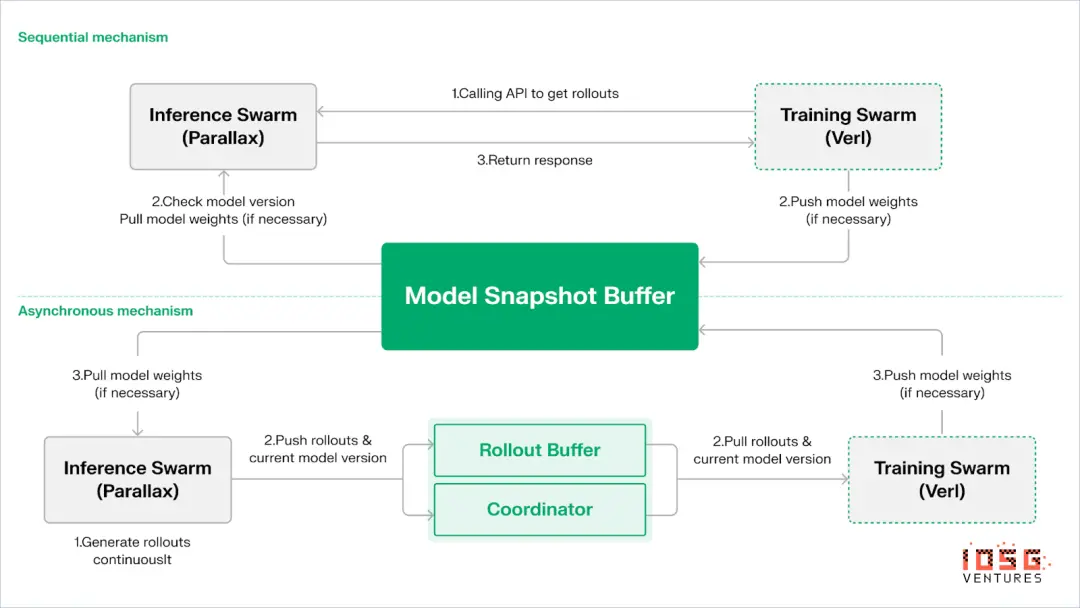
Echo employs a "dual-group architecture for reasoning and training" to maximize computing power utilization, with each group operating independently and not blocking each other:
Maximizing Sampling Throughput: The inference group Inference Swarm consists of consumer-grade GPUs and edge devices, building a high-throughput sampler through Parallax in a pipeline-parallel manner, focusing on trajectory generation.
Maximizing Gradient Computing Power: The training group Training Swarm consists of consumer-grade GPU networks that can run on centralized clusters or globally in multiple locations, responsible for gradient updates, parameter synchronization, and LoRA fine-tuning, focusing on the learning process.
To maintain consistency between strategies and data, Echo provides two types of lightweight synchronization protocols: sequential and asynchronous, achieving bidirectional consistency management of policy weights and trajectories.
Sequential Pull Mode | Accuracy First: The training side forces inference nodes to refresh model versions before pulling new trajectories, ensuring the freshness of trajectories, suitable for tasks highly sensitive to outdated strategies;
Asynchronous Push-Pull Mode | Efficiency First: The inference side continuously generates trajectories with version tags, while the training side consumes at its own pace. The coordinator monitors version deviations and triggers weight refreshes to maximize device utilization.
At the underlying level, Echo is built on Parallax (heterogeneous inference in low-bandwidth environments) and lightweight distributed training components (such as VERL), relying on LoRA to reduce cross-node synchronization costs, allowing reinforcement learning to operate stably on a global heterogeneous network.
Grail: Reinforcement Learning in the Bittensor Ecosystem
Bittensor constructs a vast, sparse, and non-stationary reward function network through its unique Yuma consensus mechanism.
Covenant AI within the Bittensor ecosystem builds a vertically integrated pipeline from pre-training to RL post-training through SN3 Templar, SN39 Basilica, and SN81 Grail. Among these, SN3 Templar is responsible for pre-training the base model, SN39 Basilica provides a distributed computing power market, and SN81 Grail serves as a "verifiable reasoning layer" for RL post-training, carrying out the core processes of RLHF / RLAIF and completing the closed-loop optimization from the base model to aligned strategies.
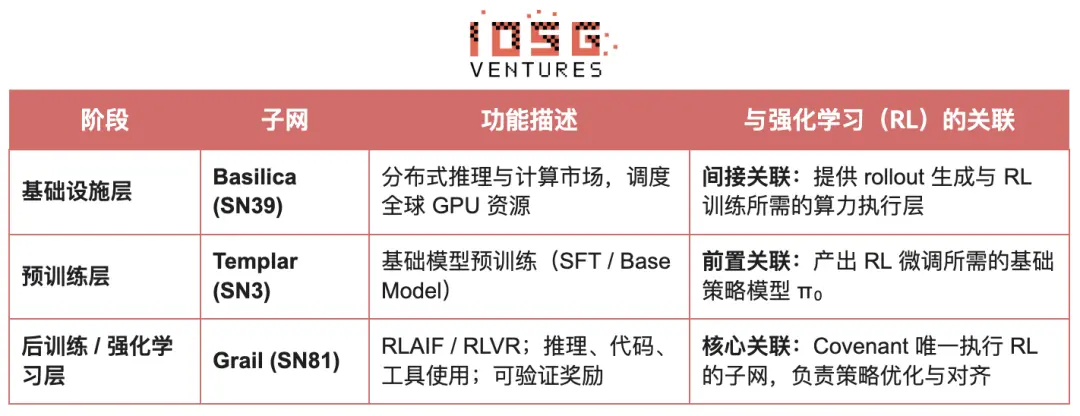
The goal of GRAIL is to cryptographically prove the authenticity of each reinforcement learning rollout and bind it to the model identity, ensuring that RLHF can be securely executed in a trustless environment. The protocol establishes a trusted chain through a three-layer mechanism:
Deterministic Challenge Generation: Utilizing drand random beacons and block hashes to generate unpredictable yet reproducible challenge tasks (such as SAT, GSM8K), eliminating pre-computation cheating;
Token-Level Logprob Sampling and Sketch Commitments: Allowing verifiers to sample token-level logprob and reasoning chains at extremely low costs, confirming that the rollout is indeed generated by the declared model;
Model Identity Binding: Binding the reasoning process to the model weight fingerprint and the structural signature of token distribution, ensuring that any model replacement or result replay will be immediately recognized. This provides a foundation of authenticity for reasoning trajectories (rollouts) in RL.
Based on this mechanism, the Grail subnet implements a GRPO-style verifiable post-training process: miners generate multiple reasoning paths for the same question, and verifiers score based on correctness, reasoning chain quality, and SAT satisfaction, writing the normalized results on-chain as TAO weights. Public experiments show that this framework has improved the MATH accuracy of Qwen2.5-1.5B from 12.7% to 47.6%, proving its ability to prevent cheating and significantly enhance model capabilities. In Covenant AI's training stack, Grail is the cornerstone of decentralized RLVR/RLAIF trust and execution, and it has not yet officially launched on the mainnet.
Fraction AI: Competition-Based Reinforcement Learning RLFC
Fraction AI's architecture is explicitly built around Reinforcement Learning from Competition (RLFC) and gamified data labeling, replacing the static rewards and manual annotations of traditional RLHF with an open, dynamic competitive environment. Agents compete in different Spaces, and their relative rankings and AI judge scores together form real-time rewards, transforming the alignment process into a continuously online multi-agent game system.
The core differences between traditional RLHF and Fraction AI's RLFC:

The core value of RLFC lies in the fact that rewards no longer come from a single model but from continuously evolving opponents and evaluators, preventing the reward model from being exploited and using strategy diversity to avoid local optima in the ecosystem. The structure of Spaces determines the nature of the game (zero-sum or positive-sum), promoting the emergence of complex behaviors through competition and cooperation.
In terms of system architecture, Fraction AI breaks down the training process into four key components:
Agents: Lightweight strategy units based on open-source LLMs, expanded with differential weights through QLoRA for low-cost updates;
Spaces: Isolated task domain environments where agents pay to enter and earn rewards based on wins and losses;
AI Judges: An instant reward layer built with RLAIF, providing scalable and decentralized evaluation;
Proof-of-Learning: Binding strategy updates to specific competitive outcomes, ensuring the training process is verifiable and cheat-proof.
The essence of Fraction AI is to build a "human-machine collaborative evolution engine." Users act as "meta-optimizers" at the strategy layer, guiding exploration directions through prompt engineering and hyperparameter configuration; while agents automatically generate massive amounts of high-quality preference data pairs in micro-level competition. This model allows data labeling to achieve a commercial closed loop through "trustless fine-tuning."
Comparison of Reinforcement Learning Web3 Project Architectures
V. Summary and Outlook: Paths and Opportunities for Reinforcement Learning × Web3
Based on the deconstruction analysis of the aforementioned cutting-edge projects, we observe that although the entry points of various teams (algorithm, engineering, or market) differ, when reinforcement learning (RL) combines with Web3, their underlying architectural logic converges into a highly consistent "decoupling-verification-incentive" paradigm. This is not only a technical coincidence but also an inevitable result of decentralized networks adapting to the unique properties of reinforcement learning.
Common Architectural Features of Reinforcement Learning: Addressing Core Physical Limitations and Trust Issues
Decoupling of Rollouts & Learning — Default Computational Topology
Communication-sparse, parallel Rollouts are outsourced to global consumer-grade GPUs, while high-bandwidth parameter updates are concentrated on a few training nodes, as seen from Prime Intellect's asynchronous Actor–Learner to Gradient Echo's dual-group architecture.
Verification-Driven Trust — Infrastructure
In a permissionless network, the authenticity of computation must be enforced through mathematical and mechanism design, represented by implementations including Gensyn's PoL, Prime Intellect's TOPLOC, and Grail's cryptographic verification.
Tokenized Incentive Loop — Market Self-Regulation
The supply of computing power, data generation, verification ranking, and reward distribution form a closed loop, driving participation through rewards and suppressing cheating through slashing, allowing the network to remain stable and continuously evolve in an open environment.
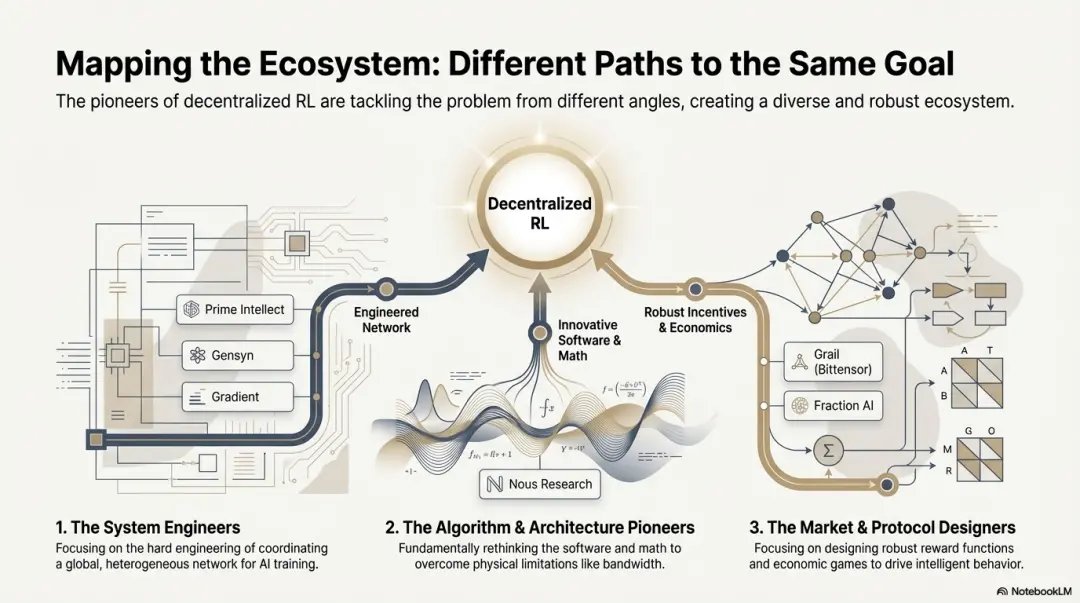
Differentiated Technical Paths: Different "Breakthrough Points" Under a Consistent Architecture
Although the architectures converge, each project has chosen different technical moats based on its own genetics:
Algorithm Breakthrough Faction (Nous Research): Attempts to solve the fundamental contradictions of distributed training (bandwidth bottleneck) from a mathematical foundation. Its DisTrO optimizer aims to compress gradient communication by thousands of times, targeting household broadband to run large model training, which is a "dimensionality reduction strike" against physical limitations.
System Engineering Faction (Prime Intellect, Gensyn, Gradient): Focuses on building the next generation of "AI runtime systems." Prime Intellect's ShardCast and Gradient's Parallax are designed to extract the highest efficiency from heterogeneous clusters through extreme engineering means under existing network conditions.
Market Game Faction (Bittensor, Fraction AI): Concentrates on the design of reward functions. By designing sophisticated scoring mechanisms, it guides miners to spontaneously seek optimal strategies to accelerate intelligent emergence.
Advantages, Challenges, and Future Outlook
In the paradigm of combining reinforcement learning with Web3, system-level advantages are first reflected in the rewriting of cost structures and governance structures.
Cost Restructuring: The demand for sampling (Rollout) in post-training is infinite, and Web3 can mobilize global long-tail computing power at extremely low costs, which is a cost advantage that centralized cloud vendors find hard to match.
Sovereign Alignment: Breaking the monopoly of large companies on AI values (Alignment), communities can vote with tokens to decide what constitutes a "good answer" for models, achieving democratization of AI governance.
At the same time, this system also faces two major structural constraints.
Bandwidth Wall: Despite innovations like DisTrO, physical latency still limits the full training of ultra-large parameter models (70B+), and currently, Web3 AI is more limited to fine-tuning and inference.
Goodhart's Law (Reward Hacking): In a highly incentivized network, miners can easily "overfit" reward rules (score farming) rather than enhancing real intelligence. Designing robust reward functions to prevent cheating is an eternal game.
Malicious Byzantine Node Attacks (BYZANTINE worker): Actively manipulating and poisoning training signals to disrupt model convergence. The core issue is not just continuously designing anti-cheating reward functions but building mechanisms with adversarial robustness.
The combination of reinforcement learning and Web3 fundamentally rewrites the mechanisms of "how intelligence is produced, aligned, and valued." Its evolutionary path can be summarized in three complementary directions:
Decentralized Training Network: From computing power mining machines to strategy networks, outsourcing parallel and verifiable Rollouts to global long-tail GPUs, focusing on the verifiable inference market in the short term, and evolving into task-clustered reinforcement learning subnets in the medium term;
Assetization of Preferences and Rewards: From labeling labor to data equity. Achieving the assetization of preferences and rewards, transforming high-quality feedback and Reward Models into governable and distributable data assets, upgrading from "labeling labor" to "data equity";
"Small but Beautiful" Evolution in Vertical Domains: Cultivating small yet powerful dedicated RL Agents in vertically defined scenarios where results are verifiable and returns are quantifiable, such as DeFi strategy execution and code generation, directly binding strategy improvement and value capture, with the potential to outperform general closed-source models.
Overall, the real opportunity of reinforcement learning × Web3 lies not in replicating a decentralized version of OpenAI, but in rewriting the "intelligent production relationship": making training execution an open computing power market, turning rewards and preferences into governable on-chain assets, and redistributing the value brought by intelligence among trainers, aligners, and users rather than concentrating it on platforms.
Recommended Reading:
Why is Asia's largest Bitcoin treasury company Metaplanet not bottom-fishing?
Multicoin Capital: The Arrival of Fintech 4.0 Era
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







